ADN



| Parte de una serie sobre |
| Genética |
|---|
 |


Ácido desoxirribonucleico ( / d iː ˈ ɒ k s ɪ ˌ r aɪ b oʊ nj uː ˌ k l iː ɪ k , - ˌ k l eɪ -/ ;[1] El ADN) es unpolímerocompuesto por dosde polinucleótidosque se enrollan una alrededor de la otra para formar unadoble hélice. El polímero llevagenéticaspara el desarrollo, funcionamiento, crecimiento yreproducciónde todoslos organismosy muchosvirus. El ADN yel ácido ribonucleico(ARN) sonácidos nucleicos. Junto conlas proteínas,los lípidosy los carbohidratos complejos (polisacáridos), los ácidos nucleicos son uno de los cuatro tipos principales demacromoléculasvidaconocidas.
Las dos cadenas de ADN se conocen como polinucleótidos, ya que están compuestas de unidades monoméricas más simples llamadas nucleótidos . [2] [3] Cada nucleótido está compuesto por una de las cuatro nucleobases que contienen nitrógeno ( citosina [C], guanina [G], adenina [A] o timina [T]), un azúcar llamado desoxirribosa y un grupo fosfato . Los nucleótidos están unidos entre sí en una cadena mediante enlaces covalentes (conocidos como enlace fosfodiéster ) entre el azúcar de un nucleótido y el fosfato del siguiente, lo que da como resultado una cadena principal alternada de azúcar-fosfato . Las bases nitrogenadas de las dos cadenas de polinucleótidos separadas están unidas entre sí, de acuerdo con las reglas de apareamiento de bases (A con T y C con G), con enlaces de hidrógeno para formar ADN bicatenario. Las bases nitrogenadas complementarias se dividen en dos grupos, las pirimidinas de anillo simple y las purinas de anillo doble . En el ADN, las pirimidinas son timina y citosina; las purinas son adenina y guanina.
Ambas hebras de ADN bicatenario almacenan la misma información biológica . Esta información se replica cuando las dos hebras se separan. Una gran parte del ADN (más del 98% para los humanos) es no codificante , lo que significa que estas secciones no sirven como patrones para las secuencias de proteínas . Las dos hebras de ADN discurren en direcciones opuestas entre sí y, por tanto, son antiparalelas . Unido a cada azúcar hay uno de los cuatro tipos de nucleobases (o bases ). Es la secuencia de estas cuatro nucleobases a lo largo de la cadena principal la que codifica la información genética. Las hebras de ARN se crean utilizando hebras de ADN como plantilla en un proceso llamado transcripción , donde las bases de ADN se intercambian por sus bases correspondientes excepto en el caso de la timina (T), por la que el ARN sustituye al uracilo (U). [4] Según el código genético , estas hebras de ARN especifican la secuencia de aminoácidos dentro de las proteínas en un proceso llamado traducción .
Dentro de las células eucariotas, el ADN se organiza en estructuras largas llamadas cromosomas . Antes de la división celular típica , estos cromosomas se duplican en el proceso de replicación del ADN, proporcionando un conjunto completo de cromosomas para cada célula hija. Los organismos eucariotas ( animales , plantas , hongos y protistas ) almacenan la mayor parte de su ADN dentro del núcleo celular como ADN nuclear , y algo en las mitocondrias como ADN mitocondrial o en los cloroplastos como ADN de cloroplasto . [5] En contraste, los procariotas ( bacterias y arqueas ) almacenan su ADN solo en el citoplasma , en cromosomas circulares . Dentro de los cromosomas eucariotas, las proteínas de la cromatina , como las histonas , compactan y organizan el ADN. Estas estructuras compactadoras guían las interacciones entre el ADN y otras proteínas, ayudando a controlar qué partes del ADN se transcriben.
Propiedades

El ADN es un polímero largo hecho de unidades repetidas llamadas nucleótidos . [6] [7] La estructura del ADN es dinámica a lo largo de su longitud, siendo capaz de enrollarse en bucles apretados y otras formas. [8] En todas las especies está compuesto de dos cadenas helicoidales, unidas entre sí por enlaces de hidrógeno . Ambas cadenas están enrolladas alrededor del mismo eje y tienen el mismo paso de 34 ångströms (3,4 nm ). El par de cadenas tiene un radio de 10 Å (1,0 nm). [9] Según otro estudio, cuando se midió en una solución diferente, la cadena de ADN midió 22-26 Å (2,2-2,6 nm) de ancho, y una unidad de nucleótido midió 3,3 Å (0,33 nm) de largo. [10] La densidad de flotación de la mayoría del ADN es de 1,7 g/cm 3 . [11]
El ADN no suele existir como una sola hebra, sino como un par de hebras que se mantienen firmemente unidas. [9] [12] Estas dos hebras largas se enrollan una alrededor de la otra, en forma de doble hélice . El nucleótido contiene tanto un segmento de la estructura principal de la molécula (que mantiene unida la cadena) como una nucleobase (que interactúa con la otra hebra de ADN en la hélice). Una nucleobase unida a un azúcar se llama nucleósido , y una base unida a un azúcar y a uno o más grupos fosfato se llama nucleótido . Un biopolímero que comprende múltiples nucleótidos unidos (como en el ADN) se llama polinucleótido . [13]
La estructura principal de la cadena de ADN está formada por grupos de fosfato y azúcar alternados . [14] El azúcar del ADN es la 2-desoxirribosa , que es un azúcar pentosa (de cinco carbonos ). Los azúcares están unidos por grupos de fosfato que forman enlaces fosfodiéster entre el tercer y quinto átomo de carbono de los anillos de azúcar adyacentes. Estos se conocen como carbonos del extremo 3' (tres extremos primos) y del extremo 5' (cinco extremos primos), utilizándose el símbolo primo para distinguir estos átomos de carbono de los de la base con la que la desoxirribosa forma un enlace glucosídico . [12]
Por lo tanto, cualquier cadena de ADN normalmente tiene un extremo en el que hay un grupo fosfato unido al carbono 5' de una ribosa (el fosforilo 5') y otro extremo en el que hay un grupo hidroxilo libre unido al carbono 3' de una ribosa (el hidroxilo 3'). La orientación de los carbonos 3' y 5' a lo largo de la cadena principal de azúcar-fosfato confiere direccionalidad (a veces llamada polaridad) a cada cadena de ADN. En una doble hélice de ácido nucleico , la dirección de los nucleótidos en una cadena es opuesta a su dirección en la otra cadena: las cadenas son antiparalelas . Se dice que los extremos asimétricos de las cadenas de ADN tienen una direccionalidad de cinco extremos primarios (5') y tres extremos primarios (3'), con el extremo 5' que tiene un grupo fosfato terminal y el extremo 3' un grupo hidroxilo terminal. Una diferencia importante entre el ADN y el ARN es el azúcar, ya que la 2-desoxirribosa en el ADN es reemplazada por el azúcar pentosa relacionado, la ribosa, en el ARN. [12]

La doble hélice del ADN se estabiliza principalmente por dos fuerzas: enlaces de hidrógeno entre nucleótidos e interacciones de apilamiento de bases entre nucleobases aromáticas . [16] Las cuatro bases que se encuentran en el ADN son adenina ( A ), citosina ( C ), guanina ( G ) y timina ( T ). Estas cuatro bases están unidas al fosfato de azúcar para formar el nucleótido completo, como se muestra para el monofosfato de adenosina . La adenina se empareja con la timina y la guanina se empareja con la citosina, formando pares de bases AT y GC . [17] [18]
Clasificación de nucleobases
Las nucleobases se clasifican en dos tipos: las purinas , A y G , que son compuestos heterocíclicos fusionados de cinco y seis miembros , y las pirimidinas , los anillos de seis miembros C y T. [12] Una quinta nucleobase pirimidínica, el uracilo ( U ), suele ocupar el lugar de la timina en el ARN y se diferencia de esta por carecer de un grupo metilo en su anillo. Además del ARN y el ADN, se han creado muchos análogos artificiales de ácidos nucleicos para estudiar las propiedades de los ácidos nucleicos o para su uso en biotecnología. [19]
Bases no canónicas
Las bases modificadas se encuentran en el ADN. La primera de ellas reconocida fue la 5-metilcitosina , que se encontró en el genoma de Mycobacterium tuberculosis en 1925. [20] La razón de la presencia de estas bases no canónicas en los virus bacterianos ( bacteriófagos ) es evitar las enzimas de restricción presentes en las bacterias. Este sistema enzimático actúa al menos en parte como un sistema inmunológico molecular que protege a las bacterias de la infección por virus. [21] Las modificaciones de las bases citosina y adenina, las bases del ADN más comunes y modificadas, desempeñan papeles vitales en el control epigenético de la expresión génica en plantas y animales. [22]
Se sabe que en el ADN existen varias bases no canónicas. [23] La mayoría de ellas son modificaciones de las bases canónicas más uracilo.
- Adenina modificada
- N6-carbamoil-metiladenina
- N6-metiadenina
- Guanina modificada
- 7-Deazaguanina
- 7-Metilguanina
- Citosina modificada
- N4-Metilcitosina
- 5-carboxilcitosina
- 5-formilcitosina
- 5-Glicosilhidroximetilcitosina
- 5-Hidroxocitosina
- 5-Metilcitosina
- Timidina modificada
- α-Glutamitimidina
- α-Putresciniltimina
- Uracilo y modificaciones
- Base J
- Uracilo
- 5-Dihidroxipentauracilo
- 5-Hidroximetildesoxiuracilo
- Otros
- Desoxiarqueosina
- 2,6-Diaminopurina (2-Aminoadenina)
Surcos

Las hebras helicoidales gemelas forman la estructura principal del ADN. Se puede encontrar otra doble hélice trazando los espacios, o surcos, entre las hebras. Estos huecos son adyacentes a los pares de bases y pueden proporcionar un sitio de unión . Como las hebras no están ubicadas simétricamente entre sí, los surcos tienen un tamaño desigual. El surco mayor tiene 22 ångströms (2,2 nm) de ancho, mientras que el surco menor tiene 12 Å (1,2 nm) de ancho. [24] Debido al mayor ancho del surco mayor, los bordes de las bases son más accesibles en el surco mayor que en el surco menor. Como resultado, las proteínas como los factores de transcripción que pueden unirse a secuencias específicas en el ADN bicatenario generalmente hacen contacto con los lados de las bases expuestas en el surco mayor. [25] Esta situación varía en conformaciones inusuales de ADN dentro de la célula (ver abajo) , pero los surcos mayores y menores siempre se nombran para reflejar las diferencias de ancho que se verían si el ADN se torciera nuevamente a la forma B ordinaria .
Apareamiento de bases
 |
 |
En una doble hélice de ADN, cada tipo de nucleobase en una cadena se enlaza con solo un tipo de nucleobase en la otra cadena. Esto se llama apareamiento de bases complementarias . Las purinas forman enlaces de hidrógeno con las pirimidinas, con la adenina uniéndose solo a la timina en dos enlaces de hidrógeno, y la citosina uniéndose solo a la guanina en tres enlaces de hidrógeno. Esta disposición de dos nucleótidos que se unen a través de la doble hélice (de anillo de seis carbonos a anillo de seis carbonos) se llama par de bases Watson-Crick. El ADN con alto contenido de GC es más estable que el ADN con bajo contenido de GC . Un par de bases Hoogsteen (unión de hidrógeno del anillo de 6 carbonos al anillo de 5 carbonos) es una variación rara del apareamiento de bases. [26] Como los enlaces de hidrógeno no son covalentes , se pueden romper y volver a unir con relativa facilidad. Las dos cadenas de ADN en una doble hélice se pueden separar como una cremallera, ya sea por una fuerza mecánica o alta temperatura . [27] Como resultado de esta complementariedad de pares de bases, toda la información de la secuencia bicatenaria de una hélice de ADN se duplica en cada hebra, lo que es vital para la replicación del ADN. Esta interacción reversible y específica entre pares de bases complementarios es fundamental para todas las funciones del ADN en los organismos. [7]
ssDNA frente a dsDNA
La mayoría de las moléculas de ADN son en realidad dos cadenas de polímeros unidas entre sí de forma helicoidal mediante enlaces no covalentes; esta estructura de doble cadena (dsADN) se mantiene en gran medida gracias a las interacciones de apilamiento de bases intracatenarias, que son más fuertes para las pilas G,C . Las dos cadenas pueden separarse (un proceso conocido como fusión) para formar dos moléculas de ADN monocatenario (ssADN). La fusión se produce a altas temperaturas, bajo nivel de sal y pH alto (el pH bajo también funde el ADN, pero como el ADN es inestable debido a la despurinización ácida, rara vez se utiliza un pH bajo).
La estabilidad de la forma dsADN depende no solo del contenido de GC (porcentaje de pares de bases G,C ), sino también de la secuencia (ya que el apilamiento es específico de la secuencia) y también de la longitud (las moléculas más largas son más estables). La estabilidad se puede medir de varias maneras; una forma común es la temperatura de fusión (también llamada valor Tm ), que es la temperatura a la que el 50% de las moléculas de doble cadena se convierten en moléculas de cadena sencilla; la temperatura de fusión depende de la fuerza iónica y la concentración de ADN. Como resultado, es tanto el porcentaje de pares de bases GC como la longitud total de una doble hélice de ADN lo que determina la fuerza de la asociación entre las dos cadenas de ADN. Las hélices de ADN largas con un alto contenido de GC tienen cadenas que interactúan más fuertemente, mientras que las hélices cortas con un alto contenido de AT tienen cadenas que interactúan más débilmente. [28] En biología, las partes de la doble hélice del ADN que necesitan separarse fácilmente, como la caja TATAAT Pribnow en algunos promotores , tienden a tener un alto contenido de AT , lo que hace que las hebras sean más fáciles de separar. [29]
En el laboratorio, la fuerza de esta interacción se puede medir hallando la temperatura de fusión Tm necesaria para romper la mitad de los enlaces de hidrógeno. Cuando todos los pares de bases de una doble hélice de ADN se funden, las cadenas se separan y existen en solución como dos moléculas completamente independientes. Estas moléculas de ADN monocatenario no tienen una única forma común, pero algunas conformaciones son más estables que otras. [30]
Cantidad

En los seres humanos, el genoma nuclear diploide femenino total por célula se extiende por 6,37 pares de gigabases (Gbp), tiene 208,23 cm de largo y pesa 6,51 picogramos (pg). [31] Los valores masculinos son 6,27 Gbp, 205,00 cm, 6,41 pg. [31] Cada polímero de ADN puede contener cientos de millones de nucleótidos, como en el cromosoma 1. El cromosoma 1 es el cromosoma humano más grande con aproximadamente 220 millones de pares de bases , y sería85 mm de largo si se endereza. [32]
En los eucariotas , además del ADN nuclear , también existe el ADN mitocondrial (ADNmt), que codifica ciertas proteínas utilizadas por las mitocondrias. El ADNmt suele ser relativamente pequeño en comparación con el ADN nuclear. Por ejemplo, el ADN mitocondrial humano forma moléculas circulares cerradas, cada una de las cuales contiene 16.569 [33] [34] pares de bases de ADN, [35] y cada una de estas moléculas contiene normalmente un conjunto completo de genes mitocondriales. Cada mitocondria humana contiene, en promedio, aproximadamente 5 moléculas de ADNmt. [35] Cada célula humana contiene aproximadamente 100 mitocondrias, lo que da un número total de moléculas de ADNmt por célula humana de aproximadamente 500. [35] Sin embargo, la cantidad de mitocondrias por célula también varía según el tipo de célula, y un óvulo puede contener 100.000 mitocondrias, que corresponden a hasta 1.500.000 copias del genoma mitocondrial (que constituye hasta el 90% del ADN de la célula). [36]
Sentido y antisentido
Una secuencia de ADN se denomina secuencia "sentido" si es la misma que la de una copia de ARN mensajero que se traduce en proteína. [37] La secuencia en la cadena opuesta se denomina secuencia "antisentido". Tanto las secuencias sentido como las antisentido pueden existir en diferentes partes de la misma cadena de ADN (es decir, ambas cadenas pueden contener secuencias sentido y antisentido). Tanto en procariotas como en eucariotas, se producen secuencias de ARN antisentido, pero las funciones de estos ARN no están del todo claras. [38] Una propuesta es que los ARN antisentido están involucrados en la regulación de la expresión génica a través del apareamiento de bases ARN-ARN. [39]
Unas pocas secuencias de ADN en procariotas y eucariotas, y más en plásmidos y virus , difuminan la distinción entre cadenas con sentido y antisentido al tener genes superpuestos . [40] En estos casos, algunas secuencias de ADN cumplen una doble función, codificando una proteína cuando se leen a lo largo de una cadena, y una segunda proteína cuando se leen en la dirección opuesta a lo largo de la otra cadena. En las bacterias , esta superposición puede estar involucrada en la regulación de la transcripción genética, [41] mientras que en los virus, los genes superpuestos aumentan la cantidad de información que se puede codificar dentro del pequeño genoma viral. [42]
Superenrollamiento
El ADN se puede torcer como una cuerda en un proceso llamado superenrollamiento del ADN . Con el ADN en su estado "relajado", una hebra generalmente rodea el eje de la doble hélice una vez cada 10,4 pares de bases, pero si el ADN está torcido, las hebras se enrollan más apretadamente o más flojamente. [43] Si el ADN se tuerce en la dirección de la hélice, esto es superenrollamiento positivo, y las bases se mantienen más juntas. Si se tuercen en la dirección opuesta, esto es superenrollamiento negativo, y las bases se separan más fácilmente. En la naturaleza, la mayoría del ADN tiene un ligero superenrollamiento negativo que es introducido por enzimas llamadas topoisomerasas . [44] Estas enzimas también son necesarias para aliviar las tensiones de torsión introducidas en las hebras de ADN durante procesos como la transcripción y la replicación del ADN . [45]
Estructuras alternativas del ADN

El ADN existe en muchas conformaciones posibles que incluyen las formas A-ADN , B-ADN y Z-ADN , aunque solo el B-ADN y el Z-ADN se han observado directamente en organismos funcionales. [14] La conformación que adopta el ADN depende del nivel de hidratación, la secuencia de ADN, la cantidad y dirección del superenrollamiento, las modificaciones químicas de las bases, el tipo y la concentración de iones metálicos y la presencia de poliaminas en solución. [46]
Los primeros informes publicados de patrones de difracción de rayos X de A-ADN (y también de B-ADN) utilizaron análisis basados en funciones de Patterson que proporcionaron solo una cantidad limitada de información estructural para fibras orientadas de ADN. [47] [48] Wilkins et al. propusieron un análisis alternativo en 1953 para los patrones de dispersión por difracción de rayos X de B-ADN in vivo de fibras de ADN altamente hidratadas en términos de cuadrados de funciones de Bessel . [49] En la misma revista, James Watson y Francis Crick presentaron su análisis de modelado molecular de los patrones de difracción de rayos X de ADN para sugerir que la estructura era una doble hélice. [9]
Aunque la forma B-ADN es la más común en las condiciones que se dan en las células, [50] no es una conformación bien definida sino una familia de conformaciones de ADN relacionadas [51] que se dan en los altos niveles de hidratación presentes en las células. Sus correspondientes patrones de difracción y dispersión de rayos X son característicos de los paracristales moleculares con un grado significativo de desorden. [52] [53]
En comparación con el ADN-B, la forma del ADN-A es una espiral dextrógira más ancha , con un surco menor ancho y poco profundo y un surco mayor más estrecho y profundo. La forma A se produce en condiciones no fisiológicas en muestras de ADN parcialmente deshidratadas, mientras que en la célula puede producirse en apareamientos híbridos de cadenas de ADN y ARN, y en complejos enzima-ADN. [54] [55] Los segmentos de ADN en los que las bases han sido modificadas químicamente por metilación pueden sufrir un cambio mayor en la conformación y adoptar la forma Z. Aquí, las cadenas giran alrededor del eje helicoidal en una espiral levógira, lo opuesto a la forma B más común. [56] Estas estructuras inusuales pueden ser reconocidas por proteínas de unión específicas del ADN-Z y pueden estar involucradas en la regulación de la transcripción. [57]
Química alternativa del ADN
Durante muchos años, los exobiólogos han propuesto la existencia de una biosfera de sombra , una biosfera microbiana postulada de la Tierra que utiliza procesos bioquímicos y moleculares radicalmente diferentes a los de la vida actualmente conocida. Una de las propuestas fue la existencia de formas de vida que utilizan arsénico en lugar de fósforo en el ADN . En 2010 se anunció un informe sobre la posibilidad en la bacteria GFAJ-1 , [58] [59] aunque la investigación fue cuestionada, [59] [60] y la evidencia sugiere que la bacteria previene activamente la incorporación de arsénico en la cadena principal del ADN y otras biomoléculas. [61]
Estructuras cuádruplex

En los extremos de los cromosomas lineales hay regiones especializadas de ADN llamadas telómeros . La función principal de estas regiones es permitir que la célula replique los extremos de los cromosomas utilizando la enzima telomerasa , ya que las enzimas que normalmente replican el ADN no pueden copiar los extremos 3′ de los cromosomas. [63] Estas tapas cromosómicas especializadas también ayudan a proteger los extremos del ADN y evitan que los sistemas de reparación del ADN en la célula los traten como un daño que debe corregirse. [64] En las células humanas , los telómeros suelen ser longitudes de ADN monocatenario que contienen varios miles de repeticiones de una secuencia TTAGGG simple. [65]
Estas secuencias ricas en guanina pueden estabilizar los extremos de los cromosomas al formar estructuras de conjuntos apilados de unidades de cuatro bases, en lugar de los pares de bases habituales que se encuentran en otras moléculas de ADN. Aquí, cuatro bases de guanina, conocidas como tétrada de guanina , forman una placa plana. Estas unidades planas de cuatro bases luego se apilan una sobre otra para formar una estructura G-quadruplex estable . [66] Estas estructuras se estabilizan mediante enlaces de hidrógeno entre los bordes de las bases y la quelación de un ion metálico en el centro de cada unidad de cuatro bases. [67] También se pueden formar otras estructuras, con el conjunto central de cuatro bases provenientes de una sola hebra doblada alrededor de las bases, o de varias hebras paralelas diferentes, cada una contribuyendo con una base a la estructura central.
Además de estas estructuras apiladas, los telómeros también forman grandes estructuras en forma de bucle llamadas bucles teloméricos o bucles T. Aquí, el ADN monocatenario se enrolla en un largo círculo estabilizado por proteínas que se unen a los telómeros. [68] En el extremo del bucle T, el ADN monocatenario del telómero se mantiene en una región de ADN bicatenario por la hebra del telómero, lo que altera el ADN de doble hélice y el apareamiento de bases con una de las dos hebras. Esta estructura de triple hebra se llama bucle de desplazamiento o bucle D. [66 ]
ADN ramificado
 |  |
| Rama única | Varias sucursales |
En el ADN, el deshilachado se produce cuando existen regiones no complementarias al final de una doble cadena de ADN que, por lo demás, sería complementaria. Sin embargo, el ADN ramificado puede producirse si se introduce una tercera cadena de ADN que contenga regiones adyacentes capaces de hibridar con las regiones deshilachadas de la doble cadena preexistente. Aunque el ejemplo más simple de ADN ramificado implica solo tres cadenas de ADN, también son posibles complejos que implican cadenas adicionales y múltiples ramificaciones. [69] El ADN ramificado se puede utilizar en nanotecnología para construir formas geométricas; consulte la sección sobre usos en tecnología a continuación.
Bases artificiales
Se han sintetizado varias nucleobases artificiales y se han incorporado con éxito en el análogo de ADN de ocho bases llamado ADN Hachimoji . Bautizadas como S, B, P y Z, estas bases artificiales son capaces de unirse entre sí de una manera predecible (S–B y P–Z), mantener la estructura de doble hélice del ADN y transcribirse en ARN. Su existencia podría verse como una indicación de que no hay nada especial en las cuatro nucleobases naturales que evolucionaron en la Tierra. [70] [71] Por otro lado, el ADN está estrechamente relacionado con el ARN , que no solo actúa como una transcripción del ADN, sino que también realiza como máquinas moleculares muchas tareas en las células. Para este propósito, tiene que plegarse en una estructura. Se ha demostrado que para permitir la creación de todas las estructuras posibles se requieren al menos cuatro bases para el ARN correspondiente , [72] aunque también es posible un número mayor, pero esto iría en contra del principio natural del mínimo esfuerzo .
Acidez
Los grupos fosfato del ADN le confieren propiedades ácidas similares a las del ácido fosfórico y puede considerarse un ácido fuerte . Se ionizará por completo a un pH celular normal, liberando protones que dejan cargas negativas en los grupos fosfato. Estas cargas negativas protegen al ADN de la descomposición por hidrólisis al repeler a los nucleófilos que podrían hidrolizarlo. [73]
Aspecto macroscópico
.jpg/1280px-Estrazione_DNA_(cropped).jpg)
El ADN puro extraído de las células forma grumos blancos y fibrosos. [74]
Modificaciones químicas y empaquetamiento alterado del ADN
Modificaciones de bases y empaquetamiento del ADN
 |  |  |
| citosina | 5-metilcitosina | timina |
La expresión de los genes está influenciada por la forma en que el ADN está empaquetado en los cromosomas, en una estructura llamada cromatina . Las modificaciones de bases pueden estar involucradas en el empaquetamiento, con regiones que tienen baja o nula expresión génica que generalmente contienen altos niveles de metilación de bases de citosina . El empaquetamiento del ADN y su influencia en la expresión génica también puede ocurrir por modificaciones covalentes del núcleo de la proteína histona alrededor del cual se envuelve el ADN en la estructura de la cromatina o bien por remodelación llevada a cabo por complejos de remodelación de la cromatina (ver Remodelación de la cromatina ). Existe, además, una comunicación cruzada entre la metilación del ADN y la modificación de las histonas, por lo que pueden afectar de manera coordinada a la cromatina y la expresión génica. [75]
Por ejemplo, la metilación de la citosina produce 5-metilcitosina , que es importante para la inactivación del cromosoma X. [76] El nivel promedio de metilación varía entre organismos: el gusano Caenorhabditis elegans carece de metilación de citosina, mientras que los vertebrados tienen niveles más altos, con hasta un 1% de su ADN que contiene 5-metilcitosina. [77] A pesar de la importancia de la 5-metilcitosina, puede desaminarse para dejar una base de timina, por lo que las citosinas metiladas son particularmente propensas a las mutaciones . [78] Otras modificaciones de bases incluyen la metilación de adenina en bacterias, la presencia de 5-hidroximetilcitosina en el cerebro , [79] y la glicosilación de uracilo para producir la "base J" en los cinetoplastos . [80] [81]
Daño

El ADN puede resultar dañado por muchos tipos de mutágenos , que modifican la secuencia del ADN . Los mutágenos incluyen agentes oxidantes , agentes alquilantes y también radiación electromagnética de alta energía como la luz ultravioleta y los rayos X. El tipo de daño al ADN producido depende del tipo de mutágeno. Por ejemplo, la luz ultravioleta puede dañar el ADN produciendo dímeros de timina , que son enlaces cruzados entre bases de pirimidina. [83] Por otro lado, oxidantes como los radicales libres o el peróxido de hidrógeno producen múltiples formas de daño, incluidas modificaciones de bases, en particular de guanosina, y roturas de doble cadena. [84] Una célula humana típica contiene alrededor de 150.000 bases que han sufrido daño oxidativo. [85] De estas lesiones oxidativas, las más peligrosas son las roturas de doble cadena, ya que son difíciles de reparar y pueden producir mutaciones puntuales , inserciones , deleciones de la secuencia de ADN y translocaciones cromosómicas . [86] Estas mutaciones pueden provocar cáncer . Debido a los límites inherentes de los mecanismos de reparación del ADN, si los humanos vivieran lo suficiente, todos acabarían desarrollando cáncer. [87] [88] Los daños en el ADN que se producen de forma natural , debido a los procesos celulares normales que producen especies reactivas de oxígeno, las actividades hidrolíticas del agua celular, etc., también ocurren con frecuencia. Aunque la mayoría de estos daños se reparan, en cualquier célula puede quedar algo de daño en el ADN a pesar de la acción de los procesos de reparación. Estos daños restantes en el ADN se acumulan con la edad en los tejidos postmitóticos de los mamíferos. Esta acumulación parece ser una causa subyacente importante del envejecimiento. [89] [90] [91]
Muchos mutágenos encajan en el espacio entre dos pares de bases adyacentes, esto se llama intercalación . La mayoría de los intercaladores son moléculas aromáticas y planares; los ejemplos incluyen bromuro de etidio , acridinas , daunomicina y doxorrubicina . Para que un intercalador encaje entre pares de bases, las bases deben separarse, distorsionando las cadenas de ADN al desenrollar la doble hélice. Esto inhibe tanto la transcripción como la replicación del ADN, causando toxicidad y mutaciones. [92] Como resultado, los intercaladores de ADN pueden ser carcinógenos y, en el caso de la talidomida, un teratógeno . [93] Otros, como el epóxido de benzo[ a ]pirenodiol y la aflatoxina, forman aductos de ADN que inducen errores en la replicación. [94] Sin embargo, debido a su capacidad para inhibir la transcripción y replicación del ADN, también se utilizan otras toxinas similares en quimioterapia para inhibir las células cancerosas de crecimiento rápido . [95]
Funciones biológicas

El ADN generalmente se presenta como cromosomas lineales en eucariotas y cromosomas circulares en procariotas . El conjunto de cromosomas en una célula constituye su genoma ; el genoma humano tiene aproximadamente 3 mil millones de pares de bases de ADN organizados en 46 cromosomas. [96] La información transportada por el ADN se mantiene en la secuencia de piezas de ADN llamadas genes . La transmisión de información genética en los genes se logra mediante el apareamiento de bases complementarias. Por ejemplo, en la transcripción, cuando una célula usa la información en un gen, la secuencia de ADN se copia en una secuencia de ARN complementaria a través de la atracción entre el ADN y los nucleótidos de ARN correctos. Por lo general, esta copia de ARN se usa luego para hacer una secuencia de proteína coincidente en un proceso llamado traducción , que depende de la misma interacción entre los nucleótidos de ARN. De manera alternativa, una célula puede copiar su información genética en un proceso llamado replicación de ADN . Los detalles de estas funciones se tratan en otros artículos; aquí el enfoque está en las interacciones entre el ADN y otras moléculas que median la función del genoma.
Genes y genomas
El ADN genómico se empaqueta de forma compacta y ordenada en el proceso llamado condensación del ADN , para adaptarse a los pequeños volúmenes disponibles de la célula. En los eucariotas, el ADN se encuentra en el núcleo celular , con pequeñas cantidades en las mitocondrias y los cloroplastos . En los procariotas, el ADN se mantiene dentro de un cuerpo de forma irregular en el citoplasma llamado nucleoide . [97] La información genética de un genoma se mantiene dentro de los genes, y el conjunto completo de esta información en un organismo se llama genotipo . Un gen es una unidad de herencia y es una región de ADN que influye en una característica particular de un organismo. Los genes contienen un marco de lectura abierto que se puede transcribir y secuencias reguladoras como promotores y potenciadores , que controlan la transcripción del marco de lectura abierto.
En muchas especies , sólo una pequeña fracción de la secuencia total del genoma codifica proteínas. Por ejemplo, sólo alrededor del 1,5% del genoma humano consiste en exones codificadores de proteínas, y más del 50% del ADN humano consiste en secuencias repetitivas no codificantes . [98] Las razones de la presencia de tanto ADN no codificante en los genomas eucariotas y las extraordinarias diferencias en el tamaño del genoma , o valor C , entre especies, representan un rompecabezas de larga data conocido como el " enigma del valor C ". [99] Sin embargo, algunas secuencias de ADN que no codifican proteínas aún pueden codificar moléculas de ARN no codificantes funcionales , que están involucradas en la regulación de la expresión génica . [100]

Algunas secuencias de ADN no codificante desempeñan funciones estructurales en los cromosomas. Los telómeros y centrómeros suelen contener pocos genes, pero son importantes para la función y la estabilidad de los cromosomas. [64] [102] Una forma abundante de ADN no codificante en los seres humanos son los pseudogenes , que son copias de genes que han sido desactivados por mutación. [103] Estas secuencias suelen ser simplemente fósiles moleculares , aunque ocasionalmente pueden servir como material genético en bruto para la creación de nuevos genes a través del proceso de duplicación y divergencia genética . [104]
Transcripción y traducción
Un gen es una secuencia de ADN que contiene información genética y puede influir en el fenotipo de un organismo. Dentro de un gen, la secuencia de bases a lo largo de una cadena de ADN define una secuencia de ARN mensajero , que a su vez define una o más secuencias de proteínas. La relación entre las secuencias de nucleótidos de los genes y las secuencias de aminoácidos de las proteínas está determinada por las reglas de traducción , conocidas colectivamente como el código genético . El código genético consta de "palabras" de tres letras llamadas codones formadas a partir de una secuencia de tres nucleótidos (por ejemplo, ACT, CAG, TTT).
En la transcripción, los codones de un gen se copian en ARN mensajero por la ARN polimerasa . Esta copia de ARN luego es decodificada por un ribosoma que lee la secuencia de ARN mediante el apareamiento de bases del ARN mensajero con el ARN de transferencia , que transporta aminoácidos. Dado que hay 4 bases en combinaciones de 3 letras, hay 64 codones posibles (4 combinaciones de 3 ). Estos codifican los veinte aminoácidos estándar , lo que da a la mayoría de los aminoácidos más de un codón posible. También hay tres codones de "parada" o "sin sentido" que significan el final de la región codificante; estos son los codones TAG, TAA y TGA (UAG, UAA y UGA en el ARNm).
Replicación

La división celular es esencial para que un organismo crezca, pero, cuando una célula se divide, debe replicar el ADN en su genoma para que las dos células hijas tengan la misma información genética que su progenitora. La estructura bicatenaria del ADN proporciona un mecanismo simple para la replicación del ADN . Aquí, las dos hebras se separan y luego la secuencia de ADN complementaria de cada hebra es recreada por una enzima llamada ADN polimerasa . Esta enzima crea la hebra complementaria al encontrar la base correcta a través del apareamiento de bases complementarias y unirla a la hebra original. Como las ADN polimerasas solo pueden extender una hebra de ADN en una dirección de 5' a 3', se utilizan diferentes mecanismos para copiar las hebras antiparalelas de la doble hélice. [105] De esta manera, la base en la hebra antigua dicta qué base aparece en la nueva hebra, y la célula termina con una copia perfecta de su ADN.
Ácidos nucleicos extracelulares
El ADN extracelular desnudo (eDNA), la mayor parte del cual se libera por la muerte celular, es casi omnipresente en el medio ambiente. Su concentración en el suelo puede ser tan alta como 2 μg/L, y su concentración en ambientes acuáticos naturales puede ser tan alta como 88 μg/L. [106] Se han propuesto varias funciones posibles para el eDNA: puede estar involucrado en la transferencia horizontal de genes ; [107] puede proporcionar nutrientes; [108] y puede actuar como un amortiguador para reclutar o titular iones o antibióticos. [109] El ADN extracelular actúa como un componente funcional de la matriz extracelular en las biopelículas de varias especies bacterianas. Puede actuar como un factor de reconocimiento para regular la adhesión y dispersión de tipos de células específicos en la biopelícula; [110] puede contribuir a la formación de la biopelícula; [111] y puede contribuir a la fuerza física de la biopelícula y la resistencia al estrés biológico. [112]
El ADN fetal libre de células se encuentra en la sangre de la madre y se puede secuenciar para determinar una gran cantidad de información sobre el feto en desarrollo. [113]
Bajo el nombre de ADN ambiental, el eDNA se ha utilizado cada vez más en las ciencias naturales como herramienta de estudio para la ecología , el seguimiento de los movimientos y la presencia de especies en el agua, el aire o la tierra, y la evaluación de la biodiversidad de un área. [114] [115]
Trampas extracelulares de neutrófilos
Las trampas extracelulares de neutrófilos (NET) son redes de fibras extracelulares, compuestas principalmente de ADN, que permiten a los neutrófilos , un tipo de glóbulo blanco, matar patógenos extracelulares mientras minimizan el daño a las células huésped.
Interacciones con proteínas
Todas las funciones del ADN dependen de interacciones con proteínas. Estas interacciones pueden ser inespecíficas o la proteína puede unirse específicamente a una única secuencia de ADN. Las enzimas también pueden unirse al ADN y, entre ellas, las polimerasas que copian la secuencia de bases del ADN en la transcripción y replicación del ADN son particularmente importantes.
Proteínas de unión al ADN

Las proteínas estructurales que se unen al ADN son ejemplos bien conocidos de interacciones no específicas entre ADN y proteína. Dentro de los cromosomas, el ADN se mantiene en complejos con proteínas estructurales. Estas proteínas organizan el ADN en una estructura compacta llamada cromatina . En los eucariotas, esta estructura implica la unión del ADN a un complejo de pequeñas proteínas básicas llamadas histonas , mientras que en los procariotas intervienen múltiples tipos de proteínas. [116] [117] Las histonas forman un complejo en forma de disco llamado nucleosoma , que contiene dos vueltas completas de ADN bicatenario envuelto alrededor de su superficie. Estas interacciones no específicas se forman a través de residuos básicos en las histonas, que forman enlaces iónicos con la cadena principal de azúcar-fosfato ácida del ADN y, por tanto, son en gran medida independientes de la secuencia de bases. [118] Las modificaciones químicas de estos residuos de aminoácidos básicos incluyen la metilación , la fosforilación y la acetilación . [119] Estos cambios químicos alteran la fuerza de la interacción entre el ADN y las histonas, haciendo que el ADN sea más o menos accesible a los factores de transcripción y cambiando la tasa de transcripción. [120] Otras proteínas de unión al ADN no específicas en la cromatina incluyen las proteínas del grupo de alta movilidad, que se unen al ADN doblado o distorsionado. [121] Estas proteínas son importantes para doblar conjuntos de nucleosomas y organizarlos en las estructuras más grandes que forman los cromosomas. [122]
Un grupo distinto de proteínas de unión al ADN son las proteínas de unión al ADN que se unen específicamente al ADN monocatenario. En los seres humanos, la proteína de replicación A es el miembro mejor comprendido de esta familia y se utiliza en procesos en los que se separa la doble hélice, incluida la replicación, la recombinación y la reparación del ADN. [123] Estas proteínas de unión parecen estabilizar el ADN monocatenario y protegerlo de la formación de bucles de tallo o de la degradación por nucleasas .

Por el contrario, otras proteínas han evolucionado para unirse a secuencias de ADN particulares. Las más estudiadas de ellas son los diversos factores de transcripción , que son proteínas que regulan la transcripción. Cada factor de transcripción se une a un conjunto particular de secuencias de ADN y activa o inhibe la transcripción de genes que tienen estas secuencias cerca de sus promotores. Los factores de transcripción hacen esto de dos maneras. En primer lugar, pueden unirse a la ARN polimerasa responsable de la transcripción, ya sea directamente o a través de otras proteínas mediadoras; esto ubica la polimerasa en el promotor y le permite comenzar la transcripción. [125] Alternativamente, los factores de transcripción pueden unirse a enzimas que modifican las histonas en el promotor. Esto cambia la accesibilidad de la plantilla de ADN a la polimerasa. [126]
Como estos objetivos de ADN pueden estar presentes en todo el genoma de un organismo, los cambios en la actividad de un tipo de factor de transcripción pueden afectar a miles de genes. [127] En consecuencia, estas proteínas suelen ser los objetivos de los procesos de transducción de señales que controlan las respuestas a los cambios ambientales o la diferenciación y el desarrollo celular . La especificidad de las interacciones de estos factores de transcripción con el ADN proviene de que las proteínas hacen múltiples contactos con los bordes de las bases del ADN, lo que les permite "leer" la secuencia del ADN. La mayoría de estas interacciones de bases se realizan en el surco mayor, donde las bases son más accesibles. [25]
Enzimas modificadoras del ADN
Nucleasas y ligasas
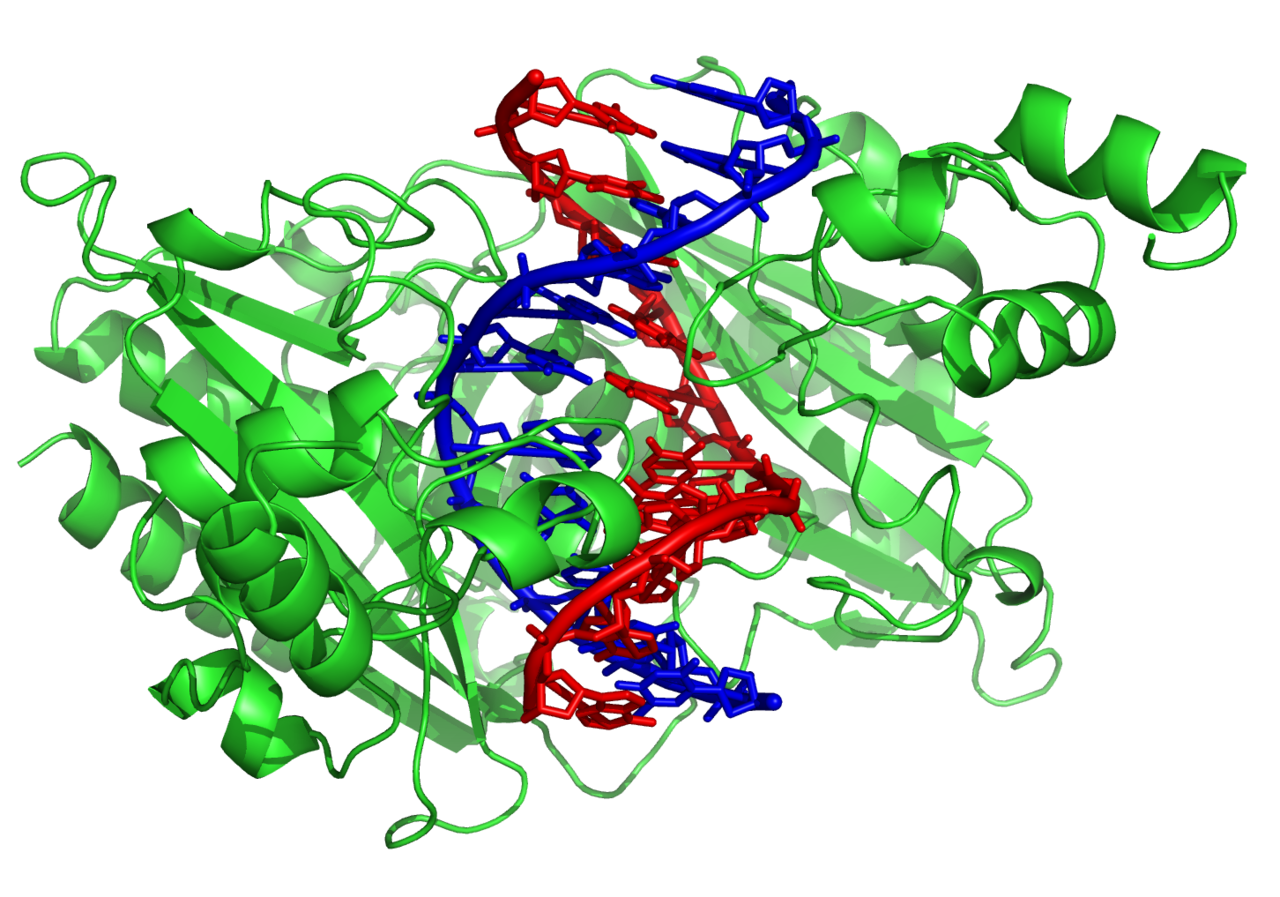
Las nucleasas son enzimas que cortan las cadenas de ADN al catalizar la hidrólisis de los enlaces fosfodiéster . Las nucleasas que hidrolizan los nucleótidos de los extremos de las cadenas de ADN se denominan exonucleasas , mientras que las endonucleasas cortan dentro de las cadenas. Las nucleasas más utilizadas en biología molecular son las endonucleasas de restricción , que cortan el ADN en secuencias específicas. Por ejemplo, la enzima EcoRV que se muestra a la izquierda reconoce la secuencia de 6 bases 5′-GATATC-3′ y realiza un corte en la línea horizontal. En la naturaleza, estas enzimas protegen a las bacterias contra la infección por fagos al digerir el ADN del fago cuando ingresa a la célula bacteriana, actuando como parte del sistema de modificación de restricción . [129] En tecnología, estas nucleasas específicas de secuencia se utilizan en la clonación molecular y la huella genética del ADN .
Las enzimas llamadas ligasas de ADN pueden volver a unir las cadenas de ADN cortadas o rotas. [130] Las ligasas son particularmente importantes en la replicación de la cadena rezagada de ADN, ya que unen los segmentos cortos de ADN producidos en la horquilla de replicación para formar una copia completa de la plantilla de ADN. También se utilizan en la reparación del ADN y la recombinación genética . [130]
Topoisomerasas y helicasas
Las topoisomerasas son enzimas con actividad tanto de nucleasa como de ligasa. Estas proteínas modifican la cantidad de superenrollamiento del ADN. Algunas de estas enzimas funcionan cortando la hélice del ADN y permitiendo que una sección rote, reduciendo así su nivel de superenrollamiento; la enzima luego sella la rotura del ADN. [44] Otros tipos de estas enzimas son capaces de cortar una hélice del ADN y luego pasar una segunda hebra de ADN a través de esta rotura, antes de volver a unir la hélice. [131] Las topoisomerasas son necesarias para muchos procesos que involucran al ADN, como la replicación y la transcripción del ADN. [45]
Las helicasas son proteínas que son un tipo de motor molecular . Utilizan la energía química de los trifosfatos de nucleósidos , predominantemente trifosfato de adenosina (ATP), para romper los enlaces de hidrógeno entre las bases y desenrollar la doble hélice del ADN en cadenas simples. [132] Estas enzimas son esenciales para la mayoría de los procesos en los que las enzimas necesitan acceder a las bases del ADN.
Polimerasas
Las polimerasas son enzimas que sintetizan cadenas de polinucleótidos a partir de trifosfatos de nucleósidos . La secuencia de sus productos se crea en función de las cadenas de polinucleótidos existentes, que se denominan plantillas . Estas enzimas funcionan añadiendo repetidamente un nucleótido al grupo hidroxilo 3' al final de la cadena de polinucleótidos en crecimiento. Como consecuencia, todas las polimerasas funcionan en una dirección de 5' a 3'. [133] En el sitio activo de estas enzimas, el trifosfato de nucleósido entrante se aparea con la plantilla: esto permite a las polimerasas sintetizar con precisión la cadena complementaria de su plantilla. Las polimerasas se clasifican según el tipo de plantilla que utilizan.
En la replicación del ADN, las ADN polimerasas dependientes del ADN hacen copias de las cadenas de polinucleótidos del ADN. Para preservar la información biológica, es esencial que la secuencia de bases en cada copia sea precisamente complementaria a la secuencia de bases en la cadena molde. Muchas ADN polimerasas tienen una actividad de corrección de errores . Aquí, la polimerasa reconoce los errores ocasionales en la reacción de síntesis por la falta de apareamiento de bases entre los nucleótidos desapareados. Si se detecta un desapareamiento, se activa una actividad de exonucleasa 3' a 5' y se elimina la base incorrecta. [134] En la mayoría de los organismos, las ADN polimerasas funcionan en un gran complejo llamado replisoma que contiene múltiples subunidades accesorias, como la abrazadera de ADN o las helicasas . [135]
Las polimerasas de ADN dependientes de ARN son una clase especializada de polimerasas que copian la secuencia de una cadena de ARN en ADN. Incluyen la transcriptasa inversa , que es una enzima viral involucrada en la infección de células por retrovirus , y la telomerasa , que es necesaria para la replicación de los telómeros. [63] [136] Por ejemplo, la transcriptasa inversa del VIH es una enzima para la replicación del virus del SIDA. [136] La telomerasa es una polimerasa inusual porque contiene su propia plantilla de ARN como parte de su estructura. Sintetiza telómeros en los extremos de los cromosomas. Los telómeros previenen la fusión de los extremos de los cromosomas vecinos y protegen los extremos de los cromosomas de daños. [64]
La transcripción la lleva a cabo una ARN polimerasa dependiente del ADN que copia la secuencia de una cadena de ADN en ARN. Para comenzar a transcribir un gen, la ARN polimerasa se une a una secuencia de ADN llamada promotor y separa las cadenas de ADN. Luego copia la secuencia del gen en una transcripción de ARN mensajero hasta que llega a una región de ADN llamada terminador , donde se detiene y se separa del ADN. Al igual que con las ADN polimerasas dependientes del ADN humano, la ARN polimerasa II , la enzima que transcribe la mayoría de los genes en el genoma humano, opera como parte de un gran complejo proteico con múltiples subunidades reguladoras y accesorias. [137]
Recombinación genética
 |
 |

Una hélice de ADN normalmente no interactúa con otros segmentos de ADN, y en las células humanas, los diferentes cromosomas incluso ocupan áreas separadas en el núcleo llamadas " territorios cromosómicos ". [139] Esta separación física de diferentes cromosomas es importante para la capacidad del ADN de funcionar como un depósito estable de información, ya que una de las pocas veces que los cromosomas interactúan es en el cruce cromosómico que ocurre durante la reproducción sexual , cuando ocurre la recombinación genética . El cruce cromosómico es cuando dos hélices de ADN se rompen, intercambian una sección y luego se vuelven a unir.
La recombinación permite que los cromosomas intercambien información genética y produzcan nuevas combinaciones de genes, lo que aumenta la eficiencia de la selección natural y puede ser importante en la rápida evolución de nuevas proteínas. [140] La recombinación genética también puede estar involucrada en la reparación del ADN, particularmente en la respuesta de la célula a las roturas de doble cadena. [141]
La forma más común de entrecruzamiento cromosómico es la recombinación homóloga , donde los dos cromosomas involucrados comparten secuencias muy similares. La recombinación no homóloga puede ser dañina para las células, ya que puede producir translocaciones cromosómicas y anomalías genéticas. La reacción de recombinación es catalizada por enzimas conocidas como recombinasas , como RAD51 . [142] El primer paso en la recombinación es una ruptura de doble cadena causada por una endonucleasa o daño al ADN. [143] Una serie de pasos catalizados en parte por la recombinasa conduce luego a la unión de las dos hélices por al menos una unión de Holliday , en la que un segmento de una sola cadena en cada hélice se une a la cadena complementaria en la otra hélice. La unión de Holliday es una estructura de unión tetraédrica que se puede mover a lo largo del par de cromosomas, intercambiando una cadena por otra. La reacción de recombinación se detiene entonces por la escisión de la unión y la religación del ADN liberado. [144] Sólo las hebras de polaridad similar intercambian ADN durante la recombinación. Hay dos tipos de escisión: escisión este-oeste y escisión norte-sur. La escisión norte-sur corta ambas hebras de ADN, mientras que la escisión este-oeste deja una hebra de ADN intacta. La formación de una unión de Holliday durante la recombinación hace posible la diversidad genética, el intercambio de genes en los cromosomas y la expresión de genomas virales de tipo salvaje.
Evolución
El ADN contiene la información genética que permite que todas las formas de vida funcionen, crezcan y se reproduzcan. Sin embargo, no está claro durante cuánto tiempo en los 4 mil millones de años de historia de la vida el ADN ha realizado esta función, ya que se ha propuesto que las primeras formas de vida pueden haber utilizado ARN como material genético. [145] [146] El ARN puede haber actuado como la parte central del metabolismo celular temprano , ya que puede transmitir información genética y llevar a cabo la catálisis como parte de las ribozimas . [147] Este antiguo mundo de ARN donde el ácido nucleico se habría utilizado tanto para la catálisis como para la genética puede haber influido en la evolución del código genético actual basado en cuatro bases de nucleótidos. Esto ocurriría, ya que el número de bases diferentes en un organismo de este tipo es una compensación entre un pequeño número de bases que aumenta la precisión de la replicación y un gran número de bases que aumenta la eficiencia catalítica de las ribozimas. [148] Sin embargo, no hay evidencia directa de sistemas genéticos antiguos, ya que la recuperación de ADN de la mayoría de los fósiles es imposible porque el ADN sobrevive en el medio ambiente durante menos de un millón de años y se degrada lentamente en fragmentos cortos en solución. [149] Se han hecho afirmaciones de ADN más antiguo, más notablemente un informe del aislamiento de una bacteria viable de un cristal de sal de 250 millones de años, [150] pero estas afirmaciones son controvertidas. [151] [152]
Los bloques de construcción del ADN ( adenina , guanina y moléculas orgánicas relacionadas ) pueden haberse formado extraterrestremente en el espacio exterior . [153] [154] [155] Los compuestos orgánicos complejos de ADN y ARN de la vida , incluidos el uracilo , la citosina y la timina , también se han formado en el laboratorio en condiciones que imitan las que se encuentran en el espacio exterior , utilizando sustancias químicas de partida, como la pirimidina , que se encuentra en meteoritos . La pirimidina, como los hidrocarburos aromáticos policíclicos (HAP), la sustancia química más rica en carbono que se encuentra en el universo , puede haberse formado en gigantes rojas o en nubes de polvo y gas cósmicos interestelares . [156]
Se ha recuperado ADN antiguo de organismos antiguos en una escala de tiempo en la que se puede observar directamente la evolución del genoma, incluso de organismos extintos de hasta millones de años de antigüedad, como el mamut lanudo . [157] [158]
Usos en tecnología
Ingeniería genética
Se han desarrollado métodos para purificar el ADN de los organismos, como la extracción con fenol-cloroformo , y para manipularlo en el laboratorio, como las digestaciones de restricción y la reacción en cadena de la polimerasa . La biología y la bioquímica modernas hacen un uso intensivo de estas técnicas en la tecnología del ADN recombinante. El ADN recombinante es una secuencia de ADN hecha por el hombre que se ha ensamblado a partir de otras secuencias de ADN. Se pueden transformar en organismos en forma de plásmidos o en el formato apropiado, utilizando un vector viral . [159] Los organismos modificados genéticamente producidos se pueden utilizar para producir productos como proteínas recombinantes , utilizadas en investigación médica , [160] o se pueden cultivar en agricultura . [161] [162]
Perfil de ADN
Los científicos forenses pueden utilizar el ADN en la sangre , el semen , la piel , la saliva o el cabello encontrados en la escena de un crimen para identificar un ADN coincidente de un individuo, como un perpetrador. [163] Este proceso se denomina formalmente perfil de ADN , también llamado huella de ADN . En el perfil de ADN, las longitudes de secciones variables de ADN repetitivo, como repeticiones cortas en tándem y minisatélites , se comparan entre personas. Este método suele ser una técnica extremadamente confiable para identificar un ADN coincidente. [164] Sin embargo, la identificación puede ser complicada si la escena está contaminada con ADN de varias personas. [165] El perfil de ADN fue desarrollado en 1984 por el genetista británico Sir Alec Jeffreys , [166] y utilizado por primera vez en la ciencia forense para condenar a Colin Pitchfork en el caso de los asesinatos de Enderby de 1988. [167]
El desarrollo de la ciencia forense y la capacidad de obtener ahora coincidencias genéticas en muestras minúsculas de sangre, piel, saliva o cabello han llevado a reexaminar muchos casos. Ahora se pueden descubrir pruebas que eran científicamente imposibles en el momento del examen original. Combinado con la eliminación de la ley de doble enjuiciamiento en algunos lugares, esto puede permitir que se reabran casos en los que los juicios anteriores no han logrado producir pruebas suficientes para convencer a un jurado. A las personas acusadas de delitos graves se les puede exigir que proporcionen una muestra de ADN para fines de comparación. La defensa más obvia para las coincidencias de ADN obtenidas forensemente es afirmar que se ha producido una contaminación cruzada de las pruebas. Esto ha dado lugar a procedimientos de manejo estrictos y meticulosos en los nuevos casos de delitos graves.
Los perfiles de ADN también se utilizan con éxito para identificar de forma positiva a víctimas de incidentes con víctimas en masa, [168] cadáveres o partes del cuerpo en accidentes graves y víctimas individuales en fosas de guerra masivas, mediante la comparación con miembros de la familia.
El perfil de ADN también se utiliza en las pruebas de paternidad de ADN para determinar si alguien es el padre o abuelo biológico de un niño; la probabilidad de paternidad suele ser del 99,99 % cuando el supuesto padre está biológicamente relacionado con el niño. Los métodos normales de secuenciación de ADN se realizan después del nacimiento, pero existen nuevos métodos para probar la paternidad mientras la madre todavía está embarazada. [169]
Enzimas de ADN o ADN catalítico
Las desoxirribozimas , también llamadas ADNzimas o ADN catalítico, se descubrieron por primera vez en 1994. [170] En su mayoría son secuencias de ADN monocatenarias aisladas de un gran grupo de secuencias de ADN aleatorias a través de un enfoque combinatorio llamado selección in vitro o evolución sistemática de ligandos por enriquecimiento exponencial (SELEX). Las ADNzimas catalizan una variedad de reacciones químicas, incluida la escisión de ARN-ADN, la ligación de ARN-ADN, la fosforilación-desfosforilación de aminoácidos, la formación de enlaces carbono-carbono, etc. Las ADNzimas pueden mejorar la tasa catalítica de las reacciones químicas hasta 100.000.000.000 de veces sobre la reacción no catalizada. [171] La clase de ADNzimas más ampliamente estudiada son los tipos de escisión de ARN que se han utilizado para detectar diferentes iones metálicos y diseñar agentes terapéuticos. Se han descrito varias ADNzimas específicas de metales, entre ellas la ADNzima GR-5 (específica del plomo), [170] las ADNzimas CA1-3 (específicas del cobre), [172] la ADNzima 39E (específica del uranilo) y la ADNzima NaA43 (específica del sodio). [173] La ADNzima NaA43, que se describe como más de 10 000 veces selectiva para el sodio sobre otros iones metálicos, se utilizó para crear un sensor de sodio en tiempo real en células.
Bioinformática
La bioinformática implica el desarrollo de técnicas para almacenar, extraer datos , buscar y manipular datos biológicos, incluidos los datos de secuencias de ácidos nucleicos de ADN. Estos han llevado a avances ampliamente aplicados en la ciencia informática , especialmente algoritmos de búsqueda de cadenas , aprendizaje automático y teoría de bases de datos . [174] Los algoritmos de búsqueda o coincidencia de cadenas, que encuentran una ocurrencia de una secuencia de letras dentro de una secuencia más grande de letras, se desarrollaron para buscar secuencias específicas de nucleótidos. [175] La secuencia de ADN se puede alinear con otras secuencias de ADN para identificar secuencias homólogas y localizar las mutaciones específicas que las hacen distintas. Estas técnicas, especialmente la alineación de secuencias múltiples , se utilizan para estudiar las relaciones filogenéticas y la función de las proteínas. [176] Los conjuntos de datos que representan secuencias de ADN de genomas enteros, como los producidos por el Proyecto Genoma Humano , son difíciles de usar sin las anotaciones que identifican las ubicaciones de los genes y los elementos reguladores en cada cromosoma. Las regiones de la secuencia de ADN que tienen patrones característicos asociados con genes codificantes de proteínas o ARN se pueden identificar mediante algoritmos de búsqueda de genes , que permiten a los investigadores predecir la presencia de productos genéticos particulares y sus posibles funciones en un organismo incluso antes de que hayan sido aislados experimentalmente. [177] También se pueden comparar genomas completos, lo que puede arrojar luz sobre la historia evolutiva de un organismo particular y permitir el examen de eventos evolutivos complejos.
Nanotecnología del ADN

La nanotecnología del ADN utiliza las propiedades únicas de reconocimiento molecular del ADN y otros ácidos nucleicos para crear complejos de ADN ramificados autoensamblables con propiedades útiles. [179] Por lo tanto, el ADN se utiliza como material estructural en lugar de como portador de información biológica. Esto ha llevado a la creación de redes periódicas bidimensionales (tanto basadas en mosaicos como utilizando el método de origami de ADN ) y estructuras tridimensionales en forma de poliedros . [180] También se han demostrado dispositivos nanomecánicos y autoensamblaje algorítmico , [181] y estas estructuras de ADN se han utilizado para modelar la disposición de otras moléculas como nanopartículas de oro y proteínas estreptavidina . [182] El ADN y otros ácidos nucleicos son la base de los aptámeros , ligandos oligonucleótidos sintéticos para moléculas diana específicas utilizadas en una variedad de aplicaciones biotecnológicas y biomédicas. [183]
Historia y antropología
Debido a que el ADN recoge mutaciones a lo largo del tiempo, que luego se heredan, contiene información histórica y, al comparar secuencias de ADN, los genetistas pueden inferir la historia evolutiva de los organismos, su filogenia . [184] Este campo de la filogenética es una herramienta poderosa en la biología evolutiva . Si se comparan las secuencias de ADN dentro de una especie, los genetistas de poblaciones pueden aprender la historia de poblaciones particulares. Esto se puede utilizar en estudios que van desde la genética ecológica hasta la antropología .
Almacenamiento de información
El ADN como dispositivo de almacenamiento de información tiene un potencial enorme, ya que tiene una densidad de almacenamiento mucho mayor en comparación con los dispositivos electrónicos. Sin embargo, los altos costos, los tiempos de lectura y escritura lentos ( latencia de memoria ) y la confiabilidad insuficiente han impedido su uso práctico. [185] [186]
Historia

El ADN fue aislado por primera vez por el médico suizo Friedrich Miescher , quien, en 1869, descubrió una sustancia microscópica en el pus de vendajes quirúrgicos desechados. Como residía en los núcleos de las células, la llamó "nucleína". [187] [188] En 1878, Albrecht Kossel aisló el componente no proteico de la "nucleína", el ácido nucleico, y más tarde aisló sus cinco nucleobases primarias . [189] [190]
En 1909, Phoebus Levene identificó la unidad de nucleótidos de base, azúcar y fosfato del ARN (entonces llamado "ácido nucleico de levadura"). [191] [192] [193] En 1929, Levene identificó el azúcar desoxirribosa en el "ácido nucleico del timo" (ADN). [194] Levene sugirió que el ADN consistía en una cadena de cuatro unidades de nucleótidos unidas entre sí a través de los grupos fosfato ("hipótesis del tetranucleótido"). Levene pensó que la cadena era corta y las bases se repetían en un orden fijo. En 1927, Nikolai Koltsov propuso que los rasgos hereditarios se heredarían a través de una "molécula hereditaria gigante" compuesta de "dos cadenas espejo que se replicarían de manera semiconservativa utilizando cada cadena como plantilla". [195] [196] En 1928, Frederick Griffith en su experimento descubrió que los rasgos de la forma "lisa" de Pneumococcus podían transferirse a la forma "rugosa" de la misma bacteria mezclando bacterias "lisas" muertas con la forma "rugosa" viva. [197] [198] Este sistema proporcionó la primera sugerencia clara de que el ADN transporta información genética.
En 1933, mientras estudiaba los huevos de erizo de mar virgen , Jean Brachet sugirió que el ADN se encuentra en el núcleo celular y que el ARN está presente exclusivamente en el citoplasma . En ese momento, se pensaba que el "ácido nucleico de levadura" (ARN) se encontraba solo en plantas, mientras que el "ácido nucleico del timo" (ADN) solo en animales. Se pensaba que este último era un tetrámero, con la función de amortiguar el pH celular. [199] [200]
En 1937, William Astbury produjo los primeros patrones de difracción de rayos X que demostraron que el ADN tenía una estructura regular. [201]
En 1943, Oswald Avery , junto con sus colaboradores Colin MacLeod y Maclyn McCarty , identificaron al ADN como el principio transformante , apoyando la sugerencia de Griffith ( experimento de Avery-MacLeod-McCarty ). [202] Erwin Chargaff desarrolló y publicó observaciones ahora conocidas como reglas de Chargaff , que establecen que en el ADN de cualquier especie de cualquier organismo, la cantidad de guanina debe ser igual a la citosina y la cantidad de adenina debe ser igual a la timina . [203] [204]

A finales de 1951, Francis Crick comenzó a trabajar con James Watson en el Laboratorio Cavendish de la Universidad de Cambridge . El papel del ADN en la herencia se confirmó en 1952 cuando Alfred Hershey y Martha Chase, en el experimento Hershey-Chase, demostraron que el ADN es el material genético del fago enterobacteriano T2 . [205]
En mayo de 1952, Raymond Gosling , un estudiante de posgrado que trabajaba bajo la supervisión de Rosalind Franklin , tomó una imagen de difracción de rayos X , etiquetada como " Foto 51 ", [206] en altos niveles de hidratación del ADN. Esta foto fue entregada a Watson y Crick por Maurice Wilkins y fue fundamental para obtener la estructura correcta del ADN. Franklin le dijo a Crick y Watson que las cadenas principales tenían que estar en el exterior. Antes de eso, Linus Pauling, y Watson y Crick, tenían modelos erróneos con las cadenas en el interior y las bases apuntando hacia afuera. La identificación de Franklin del grupo espacial para los cristales de ADN reveló a Crick que las dos cadenas de ADN eran antiparalelas . [207] En febrero de 1953, Linus Pauling y Robert Corey propusieron un modelo para los ácidos nucleicos que contenía tres cadenas entrelazadas, con los fosfatos cerca del eje y las bases en el exterior. [208] Watson y Crick completaron su modelo, que ahora se acepta como el primer modelo correcto de la doble hélice del ADN . El 28 de febrero de 1953, Crick interrumpió la hora del almuerzo en el pub The Eagle en Cambridge, Inglaterra, para anunciar que él y Watson habían "descubierto el secreto de la vida". [209]
El número del 25 de abril de 1953 de la revista Nature publicó una serie de cinco artículos que presentaban la estructura de doble hélice del ADN de Watson y Crick y evidencia que la respaldaba. [210] La estructura se informó en una carta titulada " ESTRUCTURA MOLECULAR DE LOS ÁCIDOS NUCLEICOS Una estructura para el ácido nucleico desoxirribonucleico " , en la que decían: "No se nos ha escapado que el apareamiento específico que hemos postulado sugiere inmediatamente un posible mecanismo de copia para el material genético". [9] Esta carta fue seguida por una carta de Franklin y Gosling, que fue la primera publicación de sus propios datos de difracción de rayos X y de su método de análisis original. [48] [211] Luego siguió una carta de Wilkins y dos de sus colegas, que contenía un análisis de patrones de rayos X de ADN-B in vivo , y que respaldaba la presencia in vivo de la estructura de Watson y Crick. [49]
En abril de 2023, los científicos, basándose en nuevas evidencias, concluyeron que Rosalind Franklin fue una colaboradora y un "actor igualitario" en el proceso de descubrimiento del ADN, y no lo contrario, como pudo haberse presentado posteriormente después del momento del descubrimiento. [212] [213] [214]
En 1962, tras la muerte de Franklin, Watson, Crick y Wilkins recibieron conjuntamente el Premio Nobel de Fisiología o Medicina . [215] Los premios Nobel se otorgan únicamente a los destinatarios vivos. Sigue existiendo un debate sobre a quién se le debe atribuir el descubrimiento. [216]
En una influyente presentación en 1957, Crick expuso el dogma central de la biología molecular , que predijo la relación entre el ADN, el ARN y las proteínas, y articuló la "hipótesis del adaptador". [217] La confirmación final del mecanismo de replicación que estaba implícito en la estructura de doble hélice siguió en 1958 a través del experimento de Meselson-Stahl . [218] El trabajo posterior de Crick y sus colaboradores mostró que el código genético se basaba en tripletes de bases no superpuestos, llamados codones , lo que permitió a Har Gobind Khorana , Robert W. Holley y Marshall Warren Nirenberg descifrar el código genético. [219] Estos hallazgos representan el nacimiento de la biología molecular . [220]
En 1986, el análisis de ADN se utilizó por primera vez con fines de investigación criminal cuando la policía del Reino Unido solicitó a Alec Jeffreys, de la Universidad de Leicester, que verificara o refutara la "confesión" de un sospechoso de violación y asesinato. En este caso en particular, el sospechoso había confesado dos violaciones y asesinatos, pero luego se había retractado de su confesión. Las pruebas de ADN realizadas en los laboratorios de la universidad pronto desmintieron la veracidad de la "confesión" original del sospechoso, y el sospechoso fue exonerado de los cargos de asesinato y violación. [221]
Véase también
- Autosoma : cualquier cromosoma que no sea un cromosoma sexual.
- Cristalografía : estudio científico de las estructuras cristalinas.
- Día del ADN : festividad que se celebra el 25 de abril
- Microarray de ADN : conjunto de puntos microscópicos de ADN adheridos a una superficie sólida
- Secuenciación de ADN : proceso de determinación de la secuencia de ácidos nucleicos
- Trastorno genético : Problema de salud causado por una o más anomalías en el genoma.
- Genealogía genética : pruebas de ADN para inferir relaciones
- Haplotipo : Grupo de genes de un progenitor
- Meiosis : División celular que produce gametos haploides
- Notación de ácidos nucleicos : Notación universal que utiliza los caracteres romanos A, C, G y T para denominar los cuatro nucleótidos del ADN.
- Secuencia de ácidos nucleicos – Sucesión de nucleótidos en un ácido nucleico
- ADN ribosómico : genes que codifican el ARN ribosómico
- Southern blot – técnica de análisis de ADN
- Técnicas de dispersión de rayos X : familia de técnicas analíticas no destructivasPages displaying wikidata descriptions as a fallback
- Ácidos xenonucleicos – Análogos sintéticos de ácidos nucleicos
Referencias
- ^ "ácido desoxirribonucleico". Diccionario Merriam-Webster.com . Merriam-Webster.
- ^ Alberts B, Johnson A, Lewis J, Raff M, Roberts K, Walter P (2014). Biología molecular de la célula (6.ª ed.). Garland. pág. Capítulo 4: ADN, cromosomas y genomas. ISBN 978-0-8153-4432-2Archivado desde el original el 14 de julio de 2014.
- ^ Purcell A. "ADN". Biología básica . Archivado desde el original el 5 de enero de 2017.
- ^ "Uracilo". Genome.gov . Consultado el 21 de noviembre de 2019 .
- ^ Russell P (2001). iGenetics . Nueva York: Benjamin Cummings. ISBN 0-8053-4553-1.
- ^ Saenger W (1984). Principios de la estructura de los ácidos nucleicos . Nueva York: Springer-Verlag. ISBN 0-387-90762-9.
- ^ ab Alberts B, Johnson A, Lewis J, Raff M, Roberts K, Peter W (2002). Biología molecular de la célula (cuarta edición). Nueva York y Londres: Garland Science. ISBN 0-8153-3218-1. OCLC 145080076. Archivado desde el original el 1 de noviembre de 2016.
- ^ Irobalieva RN, Fogg JM, Catanese DJ, Catanese DJ, Sutthibutpong T, Chen M, Barker AK, Ludtke SJ, Harris SA, Schmid MF, Chiu W, Zechiedrich L (octubre de 2015). "Diversidad estructural del ADN superenrollado". Nature Communications . 6 : 8440. Bibcode :2015NatCo...6.8440I. doi :10.1038/ncomms9440. ISSN 2041-1723. PMC 4608029 . PMID 26455586.
- ^ abcd Watson JD, Crick FH (abril de 1953). "Molecular structure of nucleic acids; a structure for deoxyribose nucleic acid" (PDF) . Nature . 171 (4356): 737–38. Bibcode :1953Natur.171..737W. doi :10.1038/171737a0. ISSN 0028-0836. PMID 13054692. S2CID 4253007. Archivado (PDF) desde el original el 4 de febrero de 2007.
- ^ Mandelkern M, Elias JG, Eden D, Crothers DM (octubre de 1981). "Las dimensiones del ADN en solución". Revista de biología molecular . 152 (1): 153–61. doi :10.1016/0022-2836(81)90099-1. ISSN 0022-2836. PMID 7338906.
- ^ Arrighi, Frances E.; Mandel, Manley; Bergendahl, Janet; Hsu, TC (junio de 1970). "Densidades flotantes de ADN de mamíferos". Genética Bioquímica . 4 (3): 367–376. doi :10.1007/BF00485753. ISSN 0006-2928. PMID 4991030. S2CID 27950750.
- ^ abcd Berg J, Tymoczko J, Stryer L (2002). Bioquímica . WH Freeman and Company. ISBN 0-7167-4955-6.
- ^ Comisión de Nomenclatura Bioquímica (CBN) de la IUPAC-IUB (diciembre de 1970). «Abreviaturas y símbolos para ácidos nucleicos, polinucleótidos y sus constituyentes. Recomendaciones 1970». The Biochemical Journal . 120 (3): 449–54. doi :10.1042/bj1200449. ISSN 0306-3283. PMC 1179624 . PMID 5499957. Archivado desde el original el 5 de febrero de 2007.
- ^ ab Ghosh A, Bansal M (abril de 2003). "Un glosario de estructuras de ADN de la A a la Z". Acta Crystallographica Sección D . 59 (Pt 4): 620–26. Bibcode :2003AcCrD..59..620G. doi :10.1107/S0907444903003251. ISSN 0907-4449. PMID 12657780.
- ^ Edwards KJ, Brown DG, Spink N, Skelly JV, Neidle S. "RCSB PDB – 1D65: Estructura molecular del dodecámero de ADN-B d(CGCAAATTTGCG)2. Un examen de la estructura del agua en el surco menor y la torsión de la hélice con una resolución de 2,2 A". www.rcsb.org . Consultado el 27 de marzo de 2023 .
- ^ Yakovchuk P, Protozanova E, Frank-Kamenetskii MD (2006). "Contribuciones del apilamiento y emparejamiento de bases a la estabilidad térmica de la doble hélice del ADN". Nucleic Acids Research . 34 (2): 564–74. doi :10.1093/nar/gkj454. ISSN 0305-1048. PMC 1360284 . PMID 16449200.
- ^ Tropp BE (2012). Biología molecular (4.ª ed.). Sudbury, Mass.: Jones and Barlett Learning. ISBN 978-0-7637-8663-2.
- ^ Carr S (1953). "Estructura Watson-Crick del ADN". Memorial University of Newfoundland. Archivado desde el original el 19 de julio de 2016 . Consultado el 13 de julio de 2016 .
- ^ Verma S, Eckstein F (1998). "Oligonucleótidos modificados: síntesis y estrategia para los usuarios". Revisión anual de bioquímica . 67 : 99–134. doi : 10.1146/annurev.biochem.67.1.99 . ISSN 0066-4154. PMID 9759484.
- ^ Johnson TB, Coghill RD (1925). "Pirimidinas. CIII. El descubrimiento de la 5-metilcitosina en el ácido tuberculínico, el ácido nucleico del bacilo tuberculoso". Revista de la Sociedad Química Americana . 47 : 2838–44. doi :10.1021/ja01688a030. ISSN 0002-7863.
- ^ Weigele P, Raleigh EA (octubre de 2016). "Biosíntesis y función de bases modificadas en bacterias y sus virus". Chemical Reviews . 116 (20): 12655–12687. doi : 10.1021/acs.chemrev.6b00114 . ISSN 0009-2665. PMID 27319741.
- ^ Kumar S, Chinnusamy V, Mohapatra T (2018). "Epigenética de bases de ADN modificadas: 5-metilcitosina y más allá". Frontiers in Genetics . 9 : 640. doi : 10.3389/fgene.2018.00640 . ISSN 1664-8021. PMC 6305559 . PMID 30619465.
- ^ Carell T, Kurz MQ, Müller M, Rossa M, Spada F (abril de 2018). "Bases no canónicas en el genoma: la capa de información reguladora en el ADN". Angewandte Chemie . 57 (16): 4296–4312. doi :10.1002/anie.201708228. PMID 28941008.
- ^ Wing R, Drew H, Takano T, Broka C, Tanaka S, Itakura K, Dickerson RE (octubre de 1980). "Análisis de la estructura cristalina de una vuelta completa de ADN-B". Nature . 287 (5784): 755–58. Bibcode :1980Natur.287..755W. doi :10.1038/287755a0. PMID 7432492. S2CID 4315465.
- ^ ab Pabo CO, Sauer RT (1984). "Reconocimiento proteína-ADN". Revisión anual de bioquímica . 53 : 293–321. doi :10.1146/annurev.bi.53.070184.001453. PMID 6236744.
- ^ Nikolova EN, Zhou H, Gottardo FL, Alvey HS, Kimsey IJ, Al-Hashimi HM (2013). "Un relato histórico de los pares de bases de Hoogsteen en el ADN dúplex". Biopolímeros . 99 (12): 955–68. doi :10.1002/bip.22334. PMC 3844552 . PMID 23818176.
- ^ Clausen-Schaumann H, Rief M, Tolksdorf C, Gaub HE (abril de 2000). "Estabilidad mecánica de moléculas de ADN individuales". Biophysical Journal . 78 (4): 1997–2007. Bibcode :2000BpJ....78.1997C. doi :10.1016/S0006-3495(00)76747-6. PMC 1300792 . PMID 10733978.
- ^ Chalikian TV, Völker J, Plum GE, Breslauer KJ (julio de 1999). "Una imagen más unificada de la termodinámica de la fusión de dúplex de ácidos nucleicos: una caracterización mediante técnicas calorimétricas y volumétricas". Actas de la Academia Nacional de Ciencias de los Estados Unidos de América . 96 (14): 7853–58. Bibcode :1999PNAS...96.7853C. doi : 10.1073/pnas.96.14.7853 . PMC 22151 . PMID 10393911.
- ^ deHaseth PL, Helmann JD (junio de 1995). "Formación de complejos abiertos por la ARN polimerasa de Escherichia coli: el mecanismo de separación de cadenas de ADN de doble hélice inducida por la polimerasa". Microbiología molecular . 16 (5): 817–24. doi :10.1111/j.1365-2958.1995.tb02309.x. PMID 7476180. S2CID 24479358.
- ^ Isaksson J, Acharya S, Barman J, Cheruku P, Chattopadhyaya J (diciembre de 2004). "El ADN y el ARN monocatenarios ricos en adenina conservan las características estructurales de sus respectivas conformaciones bicatenarias y muestran diferencias direccionales en el patrón de apilamiento" (PDF) . Biochemistry . 43 (51): 15996–6010. doi :10.1021/bi048221v. PMID 15609994. Archivado (PDF) desde el original el 10 de junio de 2007.
- ^ ab Piovesan A, Pelleri MC, Antonaros F, Strippoli P, Caracausi M, Vitale L (2019). "Sobre la longitud, el peso y el contenido de GC del genoma humano". BMC Res Notes . 12 (1): 106. doi : 10.1186/s13104-019-4137-z . PMC 6391780 . PMID 30813969.
- ^ Gregory SG, Barlow KF, McLay KE, Kaul R, Swarbreck D, Dunham A, et al. (mayo de 2006). "La secuencia de ADN y la anotación biológica del cromosoma humano 1". Nature . 441 (7091): 315–21. Bibcode :2006Natur.441..315G. doi : 10.1038/nature04727 . PMID 16710414.
- ^ Anderson S, Bankier AT, Barrell BG, de Bruijn MH, Coulson AR, Drouin J, et al. (abril de 1981). "Secuencia y organización del genoma mitocondrial humano". Nature . 290 (5806): 457–465. Bibcode :1981Natur.290..457A. doi :10.1038/290457a0. PMID 7219534. S2CID 4355527.
- ^ "Sin título". Archivado desde el original el 13 de agosto de 2011 . Consultado el 13 de junio de 2012 .
- ^ abc Satoh M, Kuroiwa T (septiembre de 1991). "Organización de múltiples nucleoides y moléculas de ADN en mitocondrias de una célula humana". Experimental Cell Research . 196 (1): 137–140. doi :10.1016/0014-4827(91)90467-9. PMID 1715276.
- ^ Zhang D, Keilty D, Zhang ZF, Chian RC (marzo de 2017). "Mitocondrias en el envejecimiento de los ovocitos: conocimiento actual". Facts, Views & Vision in ObGyn . 9 (1): 29–38. PMC 5506767 . PMID 28721182.
- ^ Designación de las dos hebras de ADN Archivado el 24 de abril de 2008 en Wayback Machine. Boletín JCBN/NC-IUB 1989. Consultado el 7 de mayo de 2008.
- ^ Hüttenhofer A, Schattner P, Polacek N (mayo de 2005). "ARN no codificantes: ¿esperanza o exageración?". Trends in Genetics . 21 (5): 289–97. doi :10.1016/j.tig.2005.03.007. PMID 15851066.
- ^ Munroe SH (noviembre de 2004). "Diversidad de regulación antisentido en eucariotas: mecanismos múltiples, patrones emergentes". Journal of Cellular Biochemistry . 93 (4): 664–71. doi :10.1002/jcb.20252. PMID 15389973. S2CID 23748148.
- ^ Makalowska I, Lin CF, Makalowski W (febrero de 2005). "Superposición de genes en genomas de vertebrados". Computational Biology and Chemistry . 29 (1): 1–12. doi :10.1016/j.compbiolchem.2004.12.006. PMID 15680581.
- ^ Johnson ZI, Chisholm SW (noviembre de 2004). "Las propiedades de los genes superpuestos se conservan en los genomas microbianos". Genome Research . 14 (11): 2268–72. doi :10.1101/gr.2433104. PMC 525685 . PMID 15520290.
- ^ Lamb RA, Horvath CM (agosto de 1991). "Diversidad de estrategias de codificación en virus de la gripe". Tendencias en genética . 7 (8): 261–66. doi :10.1016/0168-9525(91)90326-L. PMC 7173306 . PMID 1771674.
- ^ Benham CJ, Mielke SP (2005). "Mecánica del ADN" (PDF) . Revista anual de ingeniería biomédica . 7 : 21–53. doi :10.1146/annurev.bioeng.6.062403.132016. PMID 16004565. S2CID 1427671. Archivado desde el original (PDF) el 1 de marzo de 2019.
- ^ ab Champoux JJ (2001). "Topoisomerasas de ADN: estructura, función y mecanismo". Revista anual de bioquímica . 70 : 369–413. doi :10.1146/annurev.biochem.70.1.369. PMID 11395412. S2CID 18144189.
- ^ ab Wang JC (junio de 2002). "Funciones celulares de las topoisomerasas de ADN: una perspectiva molecular". Nature Reviews Molecular Cell Biology . 3 (6): 430–40. doi :10.1038/nrm831. PMID 12042765. S2CID 205496065.
- ^ Basu HS, Feuerstein BG, Zarling DA, Shafer RH, Marton LJ (octubre de 1988). "Reconocimiento de determinantes de ARN-Z y ADN-Z por poliaminas en solución: estudios experimentales y teóricos". Journal of Biomolecular Structure & Dynamics . 6 (2): 299–309. doi :10.1080/07391102.1988.10507714. PMID 2482766.
- ^
- Franklin RE, Gosling RG (6 de marzo de 1953). "La estructura de las fibras de timonucleato de sodio I. La influencia del contenido de agua" (PDF) . Acta Crystallogr . 6 (8–9): 673–77. Bibcode :1953AcCry...6..673F. doi : 10.1107/S0365110X53001939 . Archivado (PDF) desde el original el 9 de enero de 2016.
- Franklin RE, Gosling RG (1953). "La estructura de las fibras timonucleadas de sodio. II. La función de Patterson cilíndricamente simétrica" (PDF) . Acta Crystallogr . 6 (8–9): 678–85. Bibcode :1953AcCry...6..678F. doi : 10.1107/S0365110X53001940 . Archivado (PDF) desde el original el 29 de junio de 2017.
- ^ ab Franklin RE, Gosling RG (abril de 1953). «Molecular configuration in sodium timonucleate» (PDF) . Nature . 171 (4356): 740–41. Bibcode :1953Natur.171..740F. doi :10.1038/171740a0. PMID 13054694. S2CID 4268222. Archivado (PDF) desde el original el 3 de enero de 2011.
- ^ ab Wilkins MH, Stokes AR, Wilson HR (abril de 1953). "Molecular structure of deoxypentose nucleic acids" (PDF) . Nature . 171 (4356): 738–40. Bibcode :1953Natur.171..738W. doi :10.1038/171738a0. PMID 13054693. S2CID 4280080. Archivado (PDF) desde el original el 13 de mayo de 2011.
- ^ Leslie AG, Arnott S, Chandrasekaran R, Ratliff RL (octubre de 1980). "Polimorfismo de las dobles hélices del ADN". Journal of Molecular Biology . 143 (1): 49–72. doi :10.1016/0022-2836(80)90124-2. PMID 7441761.
- ^ Baianu IC (1980). "Orden estructural y desorden parcial en sistemas biológicos". Bull. Math. Biol . 42 (4): 137–41. doi :10.1007/BF02462372. S2CID 189888972.
- ^ Hosemann R, Bagchi RN (1962). Análisis directo de la difracción por materia . Ámsterdam – Nueva York: North-Holland Publishers.
- ^ Baianu IC (1978). «Dispersión de rayos X por sistemas de membrana parcialmente desordenados» (PDF) . Acta Crystallogr A. 34 ( 5): 751–53. Código Bibliográfico :1978AcCrA..34..751B. doi :10.1107/S0567739478001540. Archivado desde el original (PDF) el 14 de marzo de 2020. Consultado el 29 de agosto de 2019 .
- ^ Wahl MC, Sundaralingam M (1997). "Estructuras cristalinas de dúplex de A-ADN". Biopolímeros . 44 (1): 45–63. doi :10.1002/(SICI)1097-0282(1997)44:1<45::AID-BIP4>3.0.CO;2-#. PMID 9097733.
- ^ Lu XJ, Shakked Z, Olson WK (julio de 2000). "Motivos conformacionales en forma de A en estructuras de ADN unidas a ligando". Revista de biología molecular . 300 (4): 819–40. doi :10.1006/jmbi.2000.3690. PMID 10891271.
- ^ Rothenburg S, Koch-Nolte F, Haag F (diciembre de 2001). "Metilación del ADN y formación de ADN-Z como mediadores de diferencias cuantitativas en la expresión de alelos". Reseñas inmunológicas . 184 : 286–98. doi :10.1034/j.1600-065x.2001.1840125.x. PMID 12086319. S2CID 20589136.
- ^ Oh DB, Kim YG, Rich A (diciembre de 2002). "Las proteínas de unión al Z-ADN pueden actuar como potentes efectores de la expresión génica in vivo". Actas de la Academia Nacional de Ciencias de los Estados Unidos de América . 99 (26): 16666–71. Bibcode :2002PNAS...9916666O. doi : 10.1073/pnas.262672699 . PMC 139201 . PMID 12486233.
- ^ Palmer J (2 de diciembre de 2010). «Las bacterias amantes del arsénico pueden ayudar en la búsqueda de vida extraterrestre». BBC News . Archivado desde el original el 3 de diciembre de 2010. Consultado el 2 de diciembre de 2010 .
- ^ ab Bortman H (2 de diciembre de 2010). "Las bacterias que se alimentan de arsénico abren nuevas posibilidades para la vida extraterrestre". Space.com . Archivado desde el original el 4 de diciembre de 2010. Consultado el 2 de diciembre de 2010 .
- ^ Katsnelson A (2 de diciembre de 2010). "Un microbio que se alimenta de arsénico puede redefinir la química de la vida". Nature News . doi :10.1038/news.2010.645. Archivado desde el original el 12 de febrero de 2012.
- ^ Cressey D (3 de octubre de 2012). "La bacteria 'vida arsénica' prefiere el fósforo después de todo". Nature News . doi :10.1038/nature.2012.11520. S2CID 87341731.
- ^ "Estructura y empaquetamiento del ADN telomérico humano". ndbserver.rutgers.edu . Consultado el 18 de mayo de 2023 .
- ^ ab Greider CW, Blackburn EH (diciembre de 1985). "Identificación de una actividad específica de transferasa terminal de telómero en extractos de Tetrahymena". Cell . 43 (2 Pt 1): 405–13. doi : 10.1016/0092-8674(85)90170-9 . PMID 3907856.
- ^ abc Nugent CI, Lundblad V (abril de 1998). "La transcriptasa inversa de la telomerasa: componentes y regulación". Genes & Development . 12 (8): 1073–85. doi : 10.1101/gad.12.8.1073 . PMID 9553037.
- ^ Wright WE, Tesmer VM, Huffman KE, Levene SD, Shay JW (noviembre de 1997). "Los cromosomas humanos normales tienen largos salientes teloméricos ricos en G en un extremo". Genes & Development . 11 (21): 2801–09. doi :10.1101/gad.11.21.2801. PMC 316649 . PMID 9353250.
- ^ ab Burge S, Parkinson GN, Hazel P, Todd AK, Neidle S (2006). "ADN cuádruplex: secuencia, topología y estructura". Nucleic Acids Research . 34 (19): 5402–15. doi :10.1093/nar/gkl655. PMC 1636468 . PMID 17012276.
- ^ Parkinson GN, Lee MP, Neidle S (junio de 2002). "Estructura cristalina de cuadruplexes paralelos a partir de ADN telomérico humano". Nature . 417 (6891): 876–80. Bibcode :2002Natur.417..876P. doi :10.1038/nature755. PMID 12050675. S2CID 4422211.
- ^ Griffith JD, Comeau L, Rosenfield S, Stansel RM, Bianchi A, Moss H, de Lange T (mayo de 1999). "Los telómeros de los mamíferos terminan en un gran bucle dúplex". Cell . 97 (4): 503–14. CiteSeerX 10.1.1.335.2649 . doi :10.1016/S0092-8674(00)80760-6. PMID 10338214. S2CID 721901.
- ^ Seeman NC (noviembre de 2005). "El ADN permite el control a escala nanométrica de la estructura de la materia". Quarterly Reviews of Biophysics . 38 (4): 363–71. doi :10.1017/S0033583505004087. PMC 3478329 . PMID 16515737.
- ^ Warren M (21 de febrero de 2019). «Cuatro nuevas letras del ADN duplican el alfabeto de la vida». Nature . 566 (7745): 436. Bibcode :2019Natur.566..436W. doi : 10.1038/d41586-019-00650-8 . PMID 30809059.
- ^ Hoshika S, Leal NA, Kim MJ, Kim MS, Karalkar NB, Kim HJ, et al. (22 de febrero de 2019). "ADN y ARN de Hachimoji: un sistema genético con ocho bloques de construcción (de pago)". Science . 363 (6429): 884–887. Bibcode :2019Sci...363..884H. doi :10.1126/science.aat0971. PMC 6413494 . PMID 30792304.
- ^ Burghardt B, Hartmann AK (febrero de 2007). "Diseño de la estructura secundaria del ARN". Physical Review E . 75 (2): 021920. arXiv : physics/0609135 . Bibcode :2007PhRvE..75b1920B. doi :10.1103/PhysRevE.75.021920. PMID 17358380. S2CID 17574854.
- ^ Reusch W. "Nucleic Acids". Universidad Estatal de Michigan . Consultado el 30 de junio de 2022 .
- ^ "Cómo extraer ADN de cualquier ser vivo". Universidad de Utah . Consultado el 30 de junio de 2022 .
- ^ Hu Q, Rosenfeld MG (2012). "Regulación epigenética de células madre embrionarias humanas". Frontiers in Genetics . 3 : 238. doi : 10.3389/fgene.2012.00238 . PMC 3488762 . PMID 23133442.
- ^ Klose RJ, Bird AP (febrero de 2006). "Metilación del ADN genómico: la marca y sus mediadores". Tendencias en ciencias bioquímicas . 31 (2): 89–97. doi :10.1016/j.tibs.2005.12.008. PMID 16403636.
- ^ Bird A (enero de 2002). "Patrones de metilación del ADN y memoria epigenética". Genes & Development . 16 (1): 6–21. doi : 10.1101/gad.947102 . PMID 11782440.
- ^ Walsh CP, Xu GL (2006). "Metilación de citosina y reparación del ADN". Metilación del ADN: mecanismos básicos . Temas actuales en microbiología e inmunología. Vol. 301. págs. 283–315. doi :10.1007/3-540-31390-7_11. ISBN 3-540-29114-8. Número de identificación personal 16570853.
- ^ Kriaucionis S, Heintz N (mayo de 2009). "La base nuclear del ADN 5-hidroximetilcitosina está presente en las neuronas de Purkinje y en el cerebro". Science . 324 (5929): 929–30. Bibcode :2009Sci...324..929K. doi :10.1126/science.1169786. PMC 3263819 . PMID 19372393.
- ^ Ratel D, Ravanat JL, Berger F, Wion D (marzo de 2006). "N6-metiladenina: la otra base metilada del ADN". BioEssays . 28 (3): 309–15. doi :10.1002/bies.20342. PMC 2754416 . PMID 16479578.
- ^ Gommers-Ampt JH, Van Leeuwen F, de Beer AL, Vliegenthart JF, Dizdaroglu M, Kowalak JA, Crain PF, Borst P (diciembre de 1993). "beta-D-glucosil-hidroximetiluracilo: una nueva base modificada presente en el ADN del protozoo parásito T. brucei". Cell . 75 (6): 1129–36. doi :10.1016/0092-8674(93)90322-H. hdl : 1874/5219 . PMID 8261512. S2CID 24801094.
- ^ Creado a partir de PDB 1JDG Archivado el 22 de septiembre de 2008 en Wayback Machine.
- ^ Douki T, Reynaud-Angelin A, Cadet J, Sage E (agosto de 2003). "Los fotoproductos de bipirimidina, en lugar de las lesiones oxidativas, son el principal tipo de daño del ADN implicado en el efecto genotóxico de la radiación solar UVA". Bioquímica . 42 (30): 9221–26. doi :10.1021/bi034593c. PMID 12885257.
- ^ Cadet J, Delatour T, Douki T, Gasparutto D, Pouget JP, Ravanat JL, Sauvaigo S (marzo de 1999). "Radicales hidroxilo y daño a las bases del ADN". Mutation Research . 424 (1–2): 9–21. Bibcode :1999MRFMM.424....9C. doi :10.1016/S0027-5107(99)00004-4. PMID 10064846.
- ^ Beckman KB, Ames BN (agosto de 1997). "Decaimiento oxidativo del ADN". The Journal of Biological Chemistry . 272 (32): 19633–36. doi : 10.1074/jbc.272.32.19633 . PMID 9289489.
- ^ Valerie K, Povirk LF (septiembre de 2003). "Regulación y mecanismos de reparación de roturas de doble cadena en mamíferos". Oncogene . 22 (37): 5792–812. doi : 10.1038/sj.onc.1206679 . PMID 12947387.
- ^ Johnson G (28 de diciembre de 2010). "Desenterrando tumores prehistóricos y debate". The New York Times . Archivado desde el original el 24 de junio de 2017.
Si viviéramos lo suficiente, tarde o temprano todos tendríamos cáncer.
- ^ Alberts B, Johnson A, Lewis J, et al. (2002). "Las causas prevenibles del cáncer". Biología molecular de la célula (4.ª ed.). Nueva York: Garland Science. ISBN 0-8153-4072-9Se puede esperar una cierta incidencia de
fondo irreducible del cáncer independientemente de las circunstancias: las mutaciones nunca se pueden evitar por completo, porque son una consecuencia ineludible de las limitaciones fundamentales en la precisión de la replicación del ADN, como se analiza en el Capítulo 5. Si un ser humano pudiera vivir lo suficiente, es inevitable que al menos una de sus células eventualmente acumulara un conjunto de mutaciones suficientes para que se desarrollara el cáncer.
- ^ Bernstein H, Payne CM, Bernstein C, Garewal H, Dvorak K (2008). "El cáncer y el envejecimiento como consecuencias de un daño no reparado del ADN". En Kimura H, Suzuki A (eds.). Nueva investigación sobre el daño del ADN . Nueva York: Nova Science Publishers. págs. 1–47. ISBN 978-1-60456-581-2Archivado desde el original el 25 de octubre de 2014.
- ^ Hoeijmakers JH (octubre de 2009). "Daños en el ADN, envejecimiento y cáncer". The New England Journal of Medicine . 361 (15): 1475–85. doi :10.1056/NEJMra0804615. PMID 19812404.
- ^ Freitas AA, de Magalhães JP (2011). "Una revisión y evaluación de la teoría del daño del ADN en el envejecimiento". Investigación sobre mutaciones . 728 (1–2): 12–22. Bibcode :2011MRRMR.728...12F. doi :10.1016/j.mrrev.2011.05.001. PMID 21600302.
- ^ Ferguson LR, Denny WA (septiembre de 1991). "La toxicología genética de las acridinas". Mutation Research . 258 (2): 123–60. doi :10.1016/0165-1110(91)90006-H. PMID 1881402.
- ^ Stephens TD, Bunde CJ, Fillmore BJ (junio de 2000). "Mecanismo de acción en la teratogénesis de la talidomida". Farmacología bioquímica . 59 (12): 1489–99. doi :10.1016/S0006-2952(99)00388-3. PMID 10799645.
- ^ Jeffrey AM (1985). "Modificación del ADN por carcinógenos químicos". Farmacología y terapéutica . 28 (2): 237–72. doi :10.1016/0163-7258(85)90013-0. PMID 3936066.
- ^ Braña MF, Cacho M, Gradillas A, de Pascual-Teresa B, Ramos A (noviembre de 2001). "Intercaladores como fármacos anticancerígenos". Diseño farmacéutico actual . 7 (17): 1745–80. doi :10.2174/1381612013397113. PMID 11562309.
- ^ Venter JC, Adams MD, Myers EW, Li PW, Mural RJ, Sutton GG, et al. (febrero de 2001). "La secuencia del genoma humano". Science . 291 (5507): 1304–51. Bibcode :2001Sci...291.1304V. doi : 10.1126/science.1058040 . PMID 11181995.
- ^ Thanbichler M, Wang SC, Shapiro L (octubre de 2005). "El nucleoide bacteriano: una estructura altamente organizada y dinámica". Journal of Cellular Biochemistry . 96 (3): 506–21. doi : 10.1002/jcb.20519 . PMID 15988757.
- ^ Wolfsberg TG, McEntyre J, Schuler GD (febrero de 2001). "Guía para el borrador del genoma humano". Nature . 409 (6822): 824–26. Bibcode :2001Natur.409..824W. doi : 10.1038/35057000 . PMID 11236998.
- ^ Gregory TR (enero de 2005). "El enigma del valor C en plantas y animales: una revisión de paralelismos y un llamado a la colaboración". Anales de Botánica . 95 (1): 133–46. doi :10.1093/aob/mci009. PMC 4246714 . PMID 15596463.
- ^ Birney E, Stamatoyannopoulos JA , Dutta A, Guigó R, Gingeras TR, Margulies EH, et al. (junio de 2007). "Identificación y análisis de elementos funcionales en el 1% del genoma humano mediante el proyecto piloto ENCODE". Nature . 447 (7146): 799–816. Bibcode :2007Natur.447..799B. doi :10.1038/nature05874. PMC 2212820. PMID 17571346 .
- ^ Yin YW, Steitz TA. "RCSB PDB – 1MSW: Base estructural para la transición de la transcripción de iniciación a elongación en la ARN polimerasa T7". www.rcsb.org . Consultado el 27 de marzo de 2023 .
- ^ Pidoux AL, Allshire RC (marzo de 2005). "El papel de la heterocromatina en la función del centrómero". Philosophical Transactions of the Royal Society of London. Serie B, Ciencias Biológicas . 360 (1455): 569–79. doi :10.1098/rstb.2004.1611. PMC 1569473 . PMID 15905142.
- ^ Harrison PM, Hegyi H, Balasubramanian S, Luscombe NM, Bertone P, Echols N, Johnson T, Gerstein M (febrero de 2002). "Fósiles moleculares en el genoma humano: identificación y análisis de los pseudogenes en los cromosomas 21 y 22". Genome Research . 12 (2): 272–80. doi :10.1101/gr.207102. PMC 155275 . PMID 11827946.
- ^ Harrison PM, Gerstein M (mayo de 2002). "Estudio de genomas a través de los eones: familias de proteínas, pseudogenes y evolución del proteoma". Journal of Molecular Biology . 318 (5): 1155–74. doi :10.1016/S0022-2836(02)00109-2. PMID 12083509.
- ^ Albà M (2001). "ADN polimerasas replicativas". Genome Biology . 2 (1): REVIEWS3002. doi : 10.1186/gb-2001-2-1-reviews3002 . PMC 150442 . PMID 11178285.
- ^ Tani K, Nasu M (2010). "Funciones del ADN extracelular en los ecosistemas bacterianos". En Kikuchi Y, Rykova EY (eds.). Extracellular Nucleic Acids . Springer. págs. 25–38. ISBN 978-3-642-12616-1.
- ^ Vlassov VV, Laktionov PP, Rykova EY (julio de 2007). "Ácidos nucleicos extracelulares". BioEssays . 29 (7): 654–67. doi :10.1002/bies.20604. PMID 17563084. S2CID 32463239.
- ^ Finkel SE, Kolter R (noviembre de 2001). "El ADN como nutriente: un nuevo papel para los homólogos de genes de competencia bacteriana". Journal of Bacteriology . 183 (21): 6288–93. doi :10.1128/JB.183.21.6288-6293.2001. PMC 100116 . PMID 11591672.
- ^ Mulcahy H, Charron-Mazenod L, Lewenza S (noviembre de 2008). "El ADN extracelular forma quelatos de cationes e induce resistencia a antibióticos en biopelículas de Pseudomonas aeruginosa". PLOS Pathogens . 4 (11): e1000213. doi : 10.1371/journal.ppat.1000213 . PMC 2581603 . PMID 19023416.
- ^ Berne C, Kysela DT, Brun YV (agosto de 2010). "Un ADN extracelular bacteriano inhibe el asentamiento de células progenitoras móviles dentro de una biopelícula". Microbiología molecular . 77 (4): 815–29. doi :10.1111/j.1365-2958.2010.07267.x. PMC 2962764 . PMID 20598083.
- ^ Whitchurch CB, Tolker-Nielsen T, Ragas PC, Mattick JS (febrero de 2002). "ADN extracelular necesario para la formación de biopelículas bacterianas". Science . 295 (5559): 1487. doi :10.1126/science.295.5559.1487. PMID 11859186.
- ^ Hu W, Li L, Sharma S, Wang J, McHardy I, Lux R, Yang Z, He X, Gimzewski JK, Li Y, Shi W (2012). "El ADN construye y fortalece la matriz extracelular en las biopelículas de Myxococcus xanthus al interactuar con los exopolisacáridos". PLOS ONE . 7 (12): e51905. Bibcode :2012PLoSO...751905H. doi : 10.1371/journal.pone.0051905 . PMC 3530553 . PMID 23300576.
- ^ Hui L, Bianchi DW (febrero de 2013). "Avances recientes en la interrogación prenatal del genoma fetal humano". Tendencias en genética . 29 (2): 84–91. doi :10.1016/j.tig.2012.10.013. PMC 4378900 . PMID 23158400.
- ^ Foote AD, Thomsen PF, Sveegaard S, Wahlberg M, Kielgast J, Kyhn LA, et al. (2012). "Investigación del uso potencial del ADN ambiental (eDNA) para el monitoreo genético de mamíferos marinos". PLOS ONE . 7 (8): e41781. Bibcode :2012PLoSO...741781F. doi : 10.1371/journal.pone.0041781 . PMC 3430683 . PMID 22952587.
- ^ "Investigadores detectan animales terrestres utilizando ADN en cuerpos de agua cercanos".
- ^ Sandman K, Pereira SL, Reeve JN (diciembre de 1998). "Diversidad de proteínas cromosómicas procariotas y el origen del nucleosoma". Ciencias de la vida celular y molecular . 54 (12): 1350–64. doi :10.1007/s000180050259. PMC 11147202 . PMID 9893710. S2CID 21101836.
- ^ Dame RT (mayo de 2005). "El papel de las proteínas asociadas a nucleoides en la organización y compactación de la cromatina bacteriana". Microbiología molecular . 56 (4): 858–70. doi : 10.1111/j.1365-2958.2005.04598.x . PMID 15853876. S2CID 26965112.
- ^ Luger K, Mäder AW, Richmond RK, Sargent DF, Richmond TJ (septiembre de 1997). "Estructura cristalina de la partícula del núcleo del nucleosoma a una resolución de 2,8 A". Nature . 389 (6648): 251–60. Bibcode :1997Natur.389..251L. doi :10.1038/38444. PMID 9305837. S2CID 4328827.
- ^ Jenuwein T, Allis CD (agosto de 2001). "Translating the histone code" (PDF) . Science . 293 (5532): 1074–80. doi :10.1126/science.1063127. PMID 11498575. S2CID 1883924. Archivado (PDF) desde el original el 8 de agosto de 2017.
- ^ Ito T (2003). "Ensamblaje y remodelación de nucleosomas". Complejos proteicos que modifican la cromatina . Temas actuales en microbiología e inmunología. Vol. 274. págs. 1–22. doi :10.1007/978-3-642-55747-7_1. ISBN 978-3-540-44208-0. Número de identificación personal 12596902.
- ^ Thomas JO (agosto de 2001). "HMG1 y 2: proteínas de unión al ADN arquitectural". Biochemical Society Transactions . 29 (Pt 4): 395–401. doi :10.1042/BST0290395. PMID 11497996.
- ^ Grosschedl R, Giese K, Pagel J (marzo de 1994). "Proteínas del dominio HMG: elementos arquitectónicos en el ensamblaje de estructuras de nucleoproteínas". Tendencias en genética . 10 (3): 94–100. doi :10.1016/0168-9525(94)90232-1. PMID 8178371.
- ^ Iftode C, Daniely Y, Borowiec JA (1999). "Proteína de replicación A (RPA): la SSB eucariota". Critical Reviews in Biochemistry and Molecular Biology . 34 (3): 141–80. doi :10.1080/10409239991209255. PMID 10473346.
- ^ Beamer LJ, Pabo CO. «RCSB PDB – 1LMB: Estructura cristalina refinada de 1,8 Å del complejo represor-operador lambda». www.rcsb.org . Consultado el 27 de marzo de 2023 .
- ^ Myers LC, Kornberg RD (2000). "Mediador de la regulación transcripcional". Revisión anual de bioquímica . 69 : 729–49. doi :10.1146/annurev.biochem.69.1.729. PMID 10966474.
- ^ Spiegelman BM, Heinrich R (octubre de 2004). "Control biológico a través de coactivadores transcripcionales regulados". Cell . 119 (2): 157–67. doi : 10.1016/j.cell.2004.09.037 . PMID 15479634.
- ^ Li Z, Van Calcar S, Qu C, Cavenee WK, Zhang MQ, Ren B (julio de 2003). "Un papel regulador transcripcional global para c-Myc en células de linfoma de Burkitt". Actas de la Academia Nacional de Ciencias de los Estados Unidos de América . 100 (14): 8164–69. Bibcode :2003PNAS..100.8164L. doi : 10.1073/pnas.1332764100 . PMC 166200 . PMID 12808131.
- ^ Kostrewa D, Winkler FK. «RCSB PDB – 1RVA: unión de Mg2+ al sitio activo de la endonucleasa EcoRV: un estudio cristalográfico de complejos con sustrato y ADN producto a una resolución de 2 Å». www.rcsb.org . Consultado el 27 de marzo de 2023 .
- ^ Bickle TA, Krüger DH (junio de 1993). "Biología de la restricción del ADN". Microbiological Reviews . 57 (2): 434–50. doi :10.1128/MMBR.57.2.434-450.1993. PMC 372918 . PMID 8336674.
- ^ ab Doherty AJ, Suh SW (noviembre de 2000). "Conservación estructural y mecanicista en ligasas de ADN". Nucleic Acids Research . 28 (21): 4051–58. doi :10.1093/nar/28.21.4051. PMC 113121 . PMID 11058099.
- ^ Schoeffler AJ, Berger JM (diciembre de 2005). "Avances recientes en la comprensión de las relaciones estructura-función en el mecanismo de la topoisomerasa tipo II". Biochemical Society Transactions . 33 (Pt 6): 1465–70. doi :10.1042/BST20051465. PMID 16246147.
- ^ Tuteja N, Tuteja R (mayo de 2004). "Descifrando las helicasas de ADN. Motivo, estructura, mecanismo y función" (PDF) . Revista Europea de Bioquímica . 271 (10): 1849–63. doi : 10.1111/j.1432-1033.2004.04094.x . PMID 15128295.
- ^ Joyce CM, Steitz TA (noviembre de 1995). "Estructuras y funciones de la polimerasa: ¿variaciones sobre un tema?". Journal of Bacteriology . 177 (22): 6321–29. doi :10.1128/jb.177.22.6321-6329.1995. PMC 177480 . PMID 7592405.
- ^ Hubscher U, Maga G, Spadari S (2002). "ADN polimerasas eucariotas" (PDF) . Annual Review of Biochemistry . 71 : 133–63. doi :10.1146/annurev.biochem.71.090501.150041. PMID 12045093. S2CID 26171993. Archivado desde el original (PDF) el 26 de enero de 2021.
- ^ Johnson A, O'Donnell M (2005). "Replicasas de ADN celular: componentes y dinámica en la horquilla de replicación". Revisión anual de bioquímica . 74 : 283–315. doi :10.1146/annurev.biochem.73.011303.073859. PMID 15952889.
- ^ ab Tarrago-Litvak L, Andréola ML, Nevinsky GA, Sarih-Cottin L, Litvak S (mayo de 1994). "La transcriptasa inversa del VIH-1: de la enzimología a la intervención terapéutica". FASEB Journal . 8 (8): 497–503. doi : 10.1096/fasebj.8.8.7514143 . PMID 7514143. S2CID 39614573.
- ^ Martinez E (diciembre de 2002). "Complejos multiproteicos en la transcripción génica eucariota". Biología molecular de plantas . 50 (6): 925–47. doi :10.1023/A:1021258713850. PMID 12516863. S2CID 24946189.
- ^ Thorpe JH, Gale BC, Teixeira SC, Cardin CJ. "RCSB PDB – 1M6G: Caracterización estructural de Holliday Junction TCGGTACCGA". www.rcsb.org . Consultado el 27 de marzo de 2023 .
- ^ Cremer T, Cremer C (abril de 2001). "Territorios cromosómicos, arquitectura nuclear y regulación génica en células de mamíferos". Nature Reviews Genetics . 2 (4): 292–301. doi :10.1038/35066075. PMID 11283701. S2CID 8547149.
- ^ Pál C, Papp B, Lercher MJ (mayo de 2006). "Una visión integrada de la evolución de las proteínas". Nature Reviews Genetics . 7 (5): 337–48. doi :10.1038/nrg1838. PMID 16619049. S2CID 23225873.
- ^ O'Driscoll M, Jeggo PA (enero de 2006). "El papel de la reparación de roturas de doble cadena: perspectivas de la genética humana". Nature Reviews Genetics . 7 (1): 45–54. doi :10.1038/nrg1746. PMID 16369571. S2CID 7779574.
- ^ Vispé S, Defais M (octubre de 1997). "Proteína Rad51 de mamíferos: un homólogo de RecA con funciones pleiotrópicas". Biochimie . 79 (9–10): 587–92. doi :10.1016/S0300-9084(97)82007-X. PMID 9466696.
- ^ Neale MJ, Keeney S (julio de 2006). "Aclaración de la mecánica del intercambio de cadenas de ADN en la recombinación meiótica". Nature . 442 (7099): 153–58. Bibcode :2006Natur.442..153N. doi :10.1038/nature04885. PMC 5607947 . PMID 16838012.
- ^ Dickman MJ, Ingleston SM, Sedelnikova SE, Rafferty JB, Lloyd RG, Grasby JA, Hornby DP (noviembre de 2002). "El resolvasoma RuvABC". Revista Europea de Bioquímica . 269 (22): 5492–501. doi : 10.1046/j.1432-1033.2002.03250.x . PMID 12423347. S2CID 39505263.
- ^ Joyce GF (julio de 2002). "La antigüedad de la evolución basada en el ARN". Nature . 418 (6894): 214–21. Bibcode :2002Natur.418..214J. doi :10.1038/418214a. PMID 12110897. S2CID 4331004.
- ^ Orgel LE (2004). "Química prebiótica y el origen del mundo del ARN". Critical Reviews in Biochemistry and Molecular Biology . 39 (2): 99–123. CiteSeerX 10.1.1.537.7679 . doi :10.1080/10409230490460765. PMID 15217990. S2CID 4939632.
- ^ Davenport RJ (mayo de 2001). "Ribozimas. Haciendo copias en el mundo del ARN". Science . 292 (5520): 1278a–1278. doi :10.1126/science.292.5520.1278a. PMID 11360970. S2CID 85976762.
- ^ Szathmáry E (abril de 1992). "¿Cuál es el tamaño óptimo del alfabeto genético?". Actas de la Academia Nacional de Ciencias de los Estados Unidos de América . 89 (7): 2614–18. Bibcode :1992PNAS...89.2614S. doi : 10.1073/pnas.89.7.2614 . PMC 48712 . PMID 1372984.
- ^ Lindahl T (abril de 1993). "Inestabilidad y desintegración de la estructura primaria del ADN". Nature . 362 (6422): 709–15. Bibcode :1993Natur.362..709L. doi :10.1038/362709a0. PMID 8469282. S2CID 4283694.
- ^ Vreeland RH, Rosenzweig WD, Powers DW (octubre de 2000). "Aislamiento de una bacteria halotolerante de 250 millones de años de antigüedad a partir de un cristal de sal primario". Nature . 407 (6806): 897–900. Bibcode :2000Natur.407..897V. doi :10.1038/35038060. PMID 11057666. S2CID 9879073.
- ^ Hebsgaard MB, Phillips MJ, Willerslev E (mayo de 2005). "ADN geológicamente antiguo: ¿hecho o artefacto?". Tendencias en microbiología . 13 (5): 212–20. doi :10.1016/j.tim.2005.03.010. PMID 15866038.
- ^ Nickle DC, Learn GH, Rain MW, Mullins JI, Mittler JE (enero de 2002). "ADN curiosamente moderno para una bacteria de "250 millones de años"". Journal of Molecular Evolution . 54 (1): 134–37. Bibcode :2002JMolE..54..134N. doi :10.1007/s00239-001-0025-x. PMID 11734907. S2CID 24740859.
- ^ Callahan MP, Smith KE, Cleaves HJ, Ruzicka J, Stern JC, Glavin DP, House CH, Dworkin JP (agosto de 2011). "Los meteoritos carbonáceos contienen una amplia gama de nucleobases extraterrestres". Actas de la Academia Nacional de Ciencias de los Estados Unidos de América . 108 (34): 13995–98. Bibcode :2011PNAS..10813995C. doi : 10.1073/pnas.1106493108 . PMC 3161613 . PMID 21836052.
- ^ Steigerwald J (8 de agosto de 2011). «Investigadores de la NASA: los bloques de construcción del ADN se pueden fabricar en el espacio». NASA . Archivado desde el original el 23 de junio de 2015. Consultado el 10 de agosto de 2011 .
- ^ ScienceDaily Staff (9 de agosto de 2011). «Los bloques de construcción del ADN se pueden fabricar en el espacio, según sugiere la evidencia de la NASA». ScienceDaily . Archivado desde el original el 5 de septiembre de 2011 . Consultado el 9 de agosto de 2011 .
- ^ Marlaire R (3 de marzo de 2015). «NASA Ames reproduce los componentes básicos de la vida en el laboratorio». NASA . Archivado desde el original el 5 de marzo de 2015. Consultado el 5 de marzo de 2015 .
- ^ Hunt K (17 de febrero de 2021). «Se ha secuenciado el ADN más antiguo del mundo de un mamut que vivió hace más de un millón de años». CNN News . Consultado el 17 de febrero de 2021 .
- ^ Callaway E (17 de febrero de 2021). «Los genomas de mamut de un millón de años rompen el récord del ADN antiguo más antiguo: los dientes preservados en el permafrost, de hasta 1,6 millones de años, identifican un nuevo tipo de mamut en Siberia». Nature . 590 (7847): 537–538. Bibcode :2021Natur.590..537C. doi : 10.1038/d41586-021-00436-x . ISSN 0028-0836. PMID 33597786.
- ^ Goff SP, Berg P (diciembre de 1976). "Construcción de virus híbridos que contienen segmentos de ADN de fagos SV40 y lambda y su propagación en células de mono cultivadas". Cell . 9 (4 PT 2): 695–705. doi :10.1016/0092-8674(76)90133-1. PMID 189942. S2CID 41788896.
- ^ Houdebine LM (2007). "Modelos animales transgénicos en la investigación biomédica". Revisiones y protocolos de descubrimiento y validación de objetivos . Métodos en biología molecular. Vol. 360. págs. 163–202. doi :10.1385/1-59745-165-7:163. ISBN. 978-1-59745-165-9. Número de identificación personal 17172731.
- ^ Daniell H, Dhingra A (abril de 2002). "Ingeniería multigénica: el amanecer de una nueva y emocionante era en biotecnología". Current Opinion in Biotechnology . 13 (2): 136–41. doi :10.1016/S0958-1669(02)00297-5. PMC 3481857 . PMID 11950565.
- ^ Job D (noviembre de 2002). "Biotecnología vegetal en la agricultura". Biochimie . 84 (11): 1105–10. doi :10.1016/S0300-9084(02)00013-5. PMID 12595138.
- ^ Curtis C, Hereward J (29 de agosto de 2017). «De la escena del crimen a la sala del tribunal: el viaje de una muestra de ADN». The Conversation . Archivado desde el original el 22 de octubre de 2017. Consultado el 22 de octubre de 2017 .
- ^ Collins A, Morton NE (junio de 1994). "Razones de verosimilitud para la identificación del ADN". Actas de la Academia Nacional de Ciencias de los Estados Unidos de América . 91 (13): 6007–11. Bibcode :1994PNAS...91.6007C. doi : 10.1073/pnas.91.13.6007 . PMC 44126 . PMID 8016106.
- ^ Weir BS, Triggs CM, Starling L, Stowell LI, Walsh KA, Buckleton J (marzo de 1997). "Interpretación de mezclas de ADN". Revista de Ciencias Forenses . 42 (2): 213–22. doi :10.1520/JFS14100J. PMID 9068179. S2CID 14511630.
- ^ Jeffreys AJ, Wilson V, Thein SL (1985). "Huellas dactilares" específicas de cada individuo del ADN humano". Nature . 316 (6023): 76–79. Bibcode :1985Natur.316...76J. doi : 10.1038/316076a0 . PMID 2989708. S2CID 4229883.
- ^ "Colin Pitchfork". 14 de diciembre de 2006. Archivado desde el original el 14 de diciembre de 2006. Consultado el 27 de marzo de 2023 .
- ^ "Identificación de ADN en incidentes con víctimas fatales en masa". Instituto Nacional de Justicia. Septiembre de 2006. Archivado desde el original el 12 de noviembre de 2006.
- ^ Pollack A (19 de junio de 2012). «Before Birth, Dad's ID» (Antes del nacimiento, identificación del padre). The New York Times . ISSN 0362-4331. Archivado desde el original el 24 de junio de 2017. Consultado el 27 de marzo de 2023 .
- ^ ab Breaker RR, Joyce GF (diciembre de 1994). "Una enzima de ADN que corta el ARN". Química y biología . 1 (4): 223–29. doi :10.1016/1074-5521(94)90014-0. PMID 9383394.
- ^ Chandra M, Sachdeva A, Silverman SK (octubre de 2009). "Hidrolisis de ADN específica de secuencia catalizada por ADN". Nature Chemical Biology . 5 (10): 718–20. doi :10.1038/nchembio.201. PMC 2746877 . PMID 19684594.
- ^ Carmi N, Shultz LA, Breaker RR (diciembre de 1996). "Selección in vitro de ADN autoescindible". Química y biología . 3 (12): 1039–46. doi : 10.1016/S1074-5521(96)90170-2 . PMID 9000012.
- ^ Torabi SF, Wu P, McGhee CE, Chen L, Hwang K, Zheng N, Cheng J, Lu Y (mayo de 2015). "Selección in vitro de una ADNzima específica de sodio y su aplicación en la detección intracelular". Actas de la Academia Nacional de Ciencias de los Estados Unidos de América . 112 (19): 5903–08. Bibcode :2015PNAS..112.5903T. doi : 10.1073/pnas.1420361112 . PMC 4434688 . PMID 25918425.
- ^ Baldi P , Brunak S (2001). Bioinformática: el enfoque del aprendizaje automático . MIT Press. ISBN 978-0-262-02506-5.OCLC 45951728 .
- ^ Gusfield D (15 de enero de 1997). Algoritmos sobre cadenas, árboles y secuencias: informática y biología computacional . Cambridge University Press . ISBN 978-0-521-58519-4.
- ^ Sjölander K (enero de 2004). "Inferencia filogenómica de la función molecular de las proteínas: avances y desafíos". Bioinformática . 20 (2): 170–79. CiteSeerX 10.1.1.412.943 . doi :10.1093/bioinformatics/bth021. PMID 14734307.
- ^ Mount DM (2004). Bioinformática: análisis de secuencias y genomas (2.ª ed.). Cold Spring Harbor, Nueva York: Cold Spring Harbor Laboratory Press. ISBN 0-87969-712-1.OCLC 55106399 .
- ^ Strong M (marzo de 2004). "Nanomáquinas proteicas". PLOS Biology . 2 (3): E73. doi : 10.1371/journal.pbio.0020073 . PMC 368168 . PMID 15024422. S2CID 13222080.
- ^ Rothemund PW (marzo de 2006). "Plegado de ADN para crear formas y patrones a escala nanométrica" (PDF) . Nature . 440 (7082): 297–302. Bibcode :2006Natur.440..297R. doi :10.1038/nature04586. PMID 16541064. S2CID 4316391.
- ^ Andersen ES, Dong M, Nielsen MM, Jahn K, Subramani R, Mamdouh W, Golas MM, Sander B, Stark H, Oliveira CL, Pedersen JS, Birkedal V, Besenbacher F, Gothelf KV, Kjems J (mayo de 2009). "Autoensamblaje de una caja de ADN a nanoescala con tapa controlable". Naturaleza . 459 (7243): 73–76. Código Bib :2009Natur.459...73A. doi : 10.1038/naturaleza07971. hdl : 11858/00-001M-0000-0010-9362-B . PMID 19424153. S2CID 4430815.
- ^ Ishitsuka Y, Ha T (mayo de 2009). "Nanotecnología del ADN: una nanomáquina en funcionamiento". Nature Nanotechnology . 4 (5): 281–82. Bibcode :2009NatNa...4..281I. doi :10.1038/nnano.2009.101. PMID 19421208.
- ^ Aldaye FA, Palmer AL, Sleiman HF (septiembre de 2008). "Ensamblaje de materiales con ADN como guía". Science . 321 (5897): 1795–99. Bibcode :2008Sci...321.1795A. doi :10.1126/science.1154533. PMID 18818351. S2CID 2755388.
- ^ Dunn MR, Jimenez RM, Chaput JC (2017). "Análisis del descubrimiento y la tecnología de aptámeros". Nature Reviews Chemistry . 1 (10). doi :10.1038/s41570-017-0076 . Consultado el 30 de junio de 2022 .
- ^ Wray GA (2002). "Datación de ramas del árbol de la vida mediante ADN". Genome Biology . 3 (1): REVIEWS0001. doi : 10.1186/gb-2001-3-1-reviews0001 . PMC 150454 . PMID 11806830.
- ^ Panda D, Molla KA, Baig MJ, Swain A, Behera D, Dash M (mayo de 2018). "El ADN como dispositivo de almacenamiento de información digital: ¿esperanza o exageración?". 3 Biotech . 8 (5): 239. doi :10.1007/s13205-018-1246-7. PMC 5935598 . PMID 29744271.
- ^ Akram F, Haq IU, Ali H, Laghari AT (octubre de 2018). "Tendencias para almacenar datos digitales en ADN: una descripción general". Molecular Biology Reports . 45 (5): 1479–1490. doi :10.1007/s11033-018-4280-y. PMID 30073589. S2CID 51905843.
- ^ Miescher F (1871). "Ueber die chemische Zusammensetzung der Eiterzellen" [Sobre la composición química de las células de pus]. Medicinisch-chemische Untersuchungen (en alemán). 4 : 441–60.
[pag. 456]
Ich habe mich daher später mit meinen Versuchen an die ganzen Kerne gehalten, die Trennung der Körper, die ich einstweilen ohne weiteres Präjudiz als lösliches und unlösliches Nuclein bezeichnen will, einem günstigeren Material überlassend.
(Por lo tanto, en mis experimentos me limité posteriormente al núcleo entero, dejando a un material más favorable la separación de las sustancias, que por el momento, sin mayor prejuicio, designaré como material nuclear soluble e insoluble ("Nucleína"). )
- ^ Dahm R (enero de 2008). "Descubrimiento del ADN: Friedrich Miescher y los primeros años de la investigación sobre ácidos nucleicos". Human Genetics . 122 (6): 565–81. doi :10.1007/s00439-007-0433-0. PMID 17901982. S2CID 915930.
- ^ Ver:
- Kossel A (1879). "Ueber Nucleïn der Hefe" [Sobre la nucleína en la levadura]. Zeitschrift für psychologische Chemie (en alemán). 3 : 284–91.
- Kossel A (1880). "Ueber Nucleïn der Hefe II" [Sobre la nucleína en la levadura, Parte 2]. Zeitschrift für psychologische Chemie (en alemán). 4 : 290–95.
- Kossel A (1881). "Ueber die Verbreitung des Hypoxanthins im Thier- und Pflanzenreich" [Sobre la distribución de las hipoxantinas en los reinos animal y vegetal]. Zeitschrift für psychologische Chemie (en alemán). 5 : 267–71.
- Kossel A (1881). Untersuchungen über die Nucleine und ihre Spaltungsprodukte [ Investigaciones sobre la nucleína y sus productos de escisión ] (en alemán). Estrasburgo, Alemania: KJ Trübner. pag. 19.
- Kossel A (1882). "Ueber Xanthin und Hypoxanthin" [Sobre xantina e hipoxantina]. Zeitschrift für fisiologische Chemie . 6 : 422–31.
- Albrect Kossel (1883) "Zur Chemie des Zellkerns" Archivado el 17 de noviembre de 2017 en Wayback Machine (Sobre la química del núcleo celular), Zeitschrift für psychologische Chemie , 7 : 7–22.
- Kossel A (1886). "Weitere Beiträge zur Chemie des Zellkerns" [Otras contribuciones a la química del núcleo celular]. Zeitschrift für Physiologische Chemie (en alemán). 10 : 248–64.
En la pág. 264, Kossel observó proféticamente: Der Erforschung der quantum Verhältnisse der vier stickstoffreichen Basen, der Abhängigkeit ihrer Menge von den psychologischen Zuständen der Zelle, verspricht wichtige Aufschlüsse über die elementaren psychologisch-chemischen Vorgänge. (El estudio de las relaciones cuantitativas de las cuatro bases nitrogenadas —[y] de la dependencia de su cantidad de los estados fisiológicos de la célula—promete importantes conocimientos sobre los procesos fisiológico-químicos fundamentales.)
- ^ Jones ME (septiembre de 1953). "Albrecht Kossel, una semblanza biográfica". The Yale Journal of Biology and Medicine . 26 (1): 80–97. PMC 2599350 . PMID 13103145.
- ^ Levene PA, Jacobs WA (1909). "Super Inosinsäure". Berichte der Deutschen Chemischen Gesellschaft (en alemán). 42 : 1198–203. doi :10.1002/cber.190904201196.
- ^ Levene PA, Jacobs WA (1909). "Über die Hefe-Nucleinsäure". Berichte der Deutschen Chemischen Gesellschaft (en alemán). 42 (2): 2474–78. doi :10.1002/cber.190904202148.
- ^ Levene P (1919). "La estructura del ácido nucleico de la levadura". J Biol Chem . 40 (2): 415–24. doi : 10.1016/S0021-9258(18)87254-4 .
- ^ Cohen JS, Portugal FH (1974). "La búsqueda de la estructura química del ADN" (PDF) . Connecticut Medicine . 38 (10): 551–52, 554–57. PMID 4609088.
- ^ Koltsov propuso que la información genética de una célula estaba codificada en una larga cadena de aminoácidos. Véase:
- Koltsov HK (12 de diciembre de 1927). Физико-химические основы морфологии [ Las bases físico-químicas de la morfología ] (Habla). Tercera reunión de zoólogos, anatomistas e histólogos de toda la Unión (en ruso). Leningrado, URSS
- Reimpreso en: Koltsov HK (1928). "Физико-химические основы морфологии" [Las bases físico-químicas de la morfología]. Успехи экспериментальной биологии (Avances en biología experimental) serie B (en ruso). 7 (1): ?.
- Reimpreso en alemán como: Koltzoff NK (1928). "Physikalisch-chemische Grundlagen der Morphologie" [Las bases físico-químicas de la morfología]. Biologisches Zentralblatt (en alemán). 48 (6): 345–69.
- En 1934, Koltsov sostuvo que las proteínas que contienen la información genética de una célula se replican. Véase: Koltzoff N (octubre de 1934). "La estructura de los cromosomas en las glándulas salivales de Drosophila". Science . 80 (2075): 312–13. Bibcode :1934Sci....80..312K. doi :10.1126/science.80.2075.312. PMID 17769043.
De la página 313: "Creo que el tamaño de los cromosomas en las glándulas salivales [de Drosophila] está determinado por la multiplicación de
genonemas
. Con este término designo el hilo axial del cromosoma, en el que los genetistas ubican la combinación lineal de genes; … En el cromosoma normal normalmente hay un solo genoma; antes de la división celular, este genoma se ha dividido en dos hebras".
- ^ Soyfer VN (septiembre de 2001). "Las consecuencias de la dictadura política para la ciencia rusa". Nature Reviews Genetics . 2 (9): 723–29. doi :10.1038/35088598. PMID 11533721. S2CID 46277758.
- ^ Griffith F (enero de 1928). "La importancia de los tipos de neumococo". The Journal of Hygiene . 27 (2): 113–59. doi :10.1017/S0022172400031879. PMC 2167760 . PMID 20474956.
- ^ Lorenz MG, Wackernagel W (septiembre de 1994). "Transferencia de genes bacterianos mediante transformación genética natural en el medio ambiente". Microbiological Reviews . 58 (3): 563–602. doi :10.1128/MMBR.58.3.563-602.1994. PMC 372978 . PMID 7968924.
- ^ Brachet J (1933). "Recherches sur la synthese de l'acide thymonucleique colgante le development de l'oeuf d'Oursin". Archives de Biologie (en italiano). 44 : 519–76.
- ^ Burian R (1994). "Embriología citoquímica de Jean Brachet: ¿Conexiones con la renovación de la biología en Francia?" (PDF) . En Debru C, Gayon J, Picard JF (eds.). Les sciences biologiques et médicales en France 1920-1950 . Cahiers pour l'histoire de la recherche. vol. 2. París: Ediciones CNRS. págs. 207-20.
- ^ Ver:
- Astbury WT, Bell FO (1938). "Algunos desarrollos recientes en el estudio de proteínas y estructuras relacionadas con rayos X" (PDF) . Simposios de Cold Spring Harbor sobre biología cuantitativa . 6 : 109–21. doi :10.1101/sqb.1938.006.01.013. Archivado desde el original (PDF) el 14 de julio de 2014.
- Astbury WT (1947). «Estudios de ácidos nucleicos mediante rayos X». Simposios de la Sociedad de Biología Experimental (1): 66–76. PMID 20257017. Archivado desde el original el 5 de julio de 2014.
- ^ Avery OT, Macleod CM, McCarty M (febrero de 1944). "Estudios sobre la naturaleza química de la sustancia que induce la transformación de los tipos de neumococo: inducción de la transformación por una fracción de ácido desoxirribonucleico aislada del neumococo tipo III". The Journal of Experimental Medicine . 79 (2): 137–158. doi :10.1084/jem.79.2.137. PMC 2135445 . PMID 19871359.
- ^ Chargaff E (junio de 1950). "Especificidad química de los ácidos nucleicos y mecanismo de su degradación enzimática". Experientia . 6 (6): 201–209. doi :10.1007/BF02173653. PMID 15421335. S2CID 2522535.
- ^ Kresge N, Simoni RD, Hill RL (junio de 2005). "Las reglas de Chargaff: el trabajo de Erwin Chargaff". Journal of Biological Chemistry . 280 (24): 172–174. doi : 10.1016/S0021-9258(20)61522-8 .
- ^ Hershey AD, Chase M (mayo de 1952). "Funciones independientes de la proteína viral y el ácido nucleico en el crecimiento del bacteriófago". The Journal of General Physiology . 36 (1): 39–56. doi :10.1085/jgp.36.1.39. PMC 2147348 . PMID 12981234.
- ^ "Imágenes e ilustraciones: fotografía cristalográfica de timonucleato de sodio, tipo B. "Foto 51." Mayo de 1952". scarc.library.oregonstate.edu . Consultado el 18 de mayo de 2023 .
- ^ Schwartz J (2008). En busca del gen: de Darwin al ADN . Cambridge, Mass.: Harvard University Press. ISBN 978-0-674-02670-4.
- ^ Pauling L, Corey RB (febrero de 1953). "Una estructura propuesta para los ácidos nucleicos". Actas de la Academia Nacional de Ciencias de los Estados Unidos de América . 39 (2): 84–97. Bibcode :1953PNAS...39...84P. doi : 10.1073/pnas.39.2.84 . PMC 1063734 . PMID 16578429.
- ^ Regis E (2009). ¿Qué es la vida?: investigación de la naturaleza de la vida en la era de la biología sintética . Oxford: Oxford University Press . pág. 52. ISBN. 978-0-19-538341-6.
- ^ "La doble hélice del ADN: 50 años". Archivos de la revista Nature . Archivado desde el original el 5 de abril de 2015.
- ^ "Imagen original de difracción de rayos X". Biblioteca Estatal de Oregón. Archivado desde el original el 30 de enero de 2009. Consultado el 6 de febrero de 2011 .
- ^ Burakoff M (25 de abril de 2023). "El papel de Rosalind Franklin en el descubrimiento del ADN adquiere un nuevo giro". AP News . Consultado el 25 de abril de 2023 .
- ^ Anthes E (25 de abril de 2023). «Descifrando el papel de Rosalind Franklin en el descubrimiento del ADN, 70 años después: los historiadores han debatido durante mucho tiempo el papel que desempeñó la Dra. Franklin en la identificación de la doble hélice. Un nuevo ensayo de opinión sostiene que ella fue una «contribuyente igualitaria»». The New York Times . Archivado desde el original el 25 de abril de 2023. Consultado el 26 de abril de 2023 .
- ^ Cobb M, Comfort N (25 de abril de 2023). "Lo que Rosalind Franklin realmente contribuyó al descubrimiento de la estructura del ADN: Franklin no fue una víctima en la forma en que se resolvió la doble hélice del ADN. Una carta pasada por alto y un artículo de noticias inédito, ambos escritos en 1953, revelan que ella era una participante igualitaria". Nature . 616 (7958): 657–660. Bibcode :2023Natur.616..657C. doi : 10.1038/d41586-023-01313-5 . PMID 37100935. S2CID 258314143.
- ^ "El Premio Nobel de Fisiología o Medicina 1962". Nobelprize.org .
- ^ Maddox B (enero de 2003). "La doble hélice y la 'heroína agraviada'" (PDF) . Nature . 421 (6921): 407–08. Bibcode :2003Natur.421..407M. doi : 10.1038/nature01399 . PMID 12540909. S2CID 4428347. Archivado (PDF) desde el original el 17 de octubre de 2016.
- ^ Crick FH (1955). A Note for the RNA Tie Club (PDF) (Discurso). Cambridge, Inglaterra. Archivado desde el original (PDF) el 1 de octubre de 2008.
- ^ Meselson M, Stahl FW (julio de 1958). "La replicación del ADN en Escherichia coli". Actas de la Academia Nacional de Ciencias de los Estados Unidos de América . 44 (7): 671–82. Bibcode :1958PNAS...44..671M. doi : 10.1073/pnas.44.7.671 . PMC 528642 . PMID 16590258.
- ^ "El Premio Nobel de Fisiología o Medicina 1968". Nobelprize.org .
- ^ Pray L (2008). "Descubrimiento de la estructura y función del ADN: Watson y Crick". Nature Education . 1 (1): 100.
- ^ Panneerchelvam S, Norazmi MN (2003). "Perfiles y bases de datos de ADN forense". Revista Malaya de Ciencias Médicas . 10 (2): 20–26. PMC 3561883 . PMID 23386793.
Lectura adicional
- Berry A, Watson J (2003). ADN: el secreto de la vida. Nueva York: Alfred A. Knopf. ISBN 0-375-41546-7.
- Calladine CR, Drew HR, Luisi BF, Travers AA (2003). Entender el ADN: la molécula y cómo funciona . Ámsterdam: Elsevier Academic Press. ISBN 0-12-155089-3.
- Carina D, Clayton J (2003). 50 años de ADN. Basingstoke: Palgrave Macmillan. ISBN 1-4039-1479-6.
- Judson HF (1979). El octavo día de la creación: creadores de la revolución en biología (2.ª ed.). Cold Spring Harbor Laboratory Press. ISBN 0-671-22540-5.
- Olby RC (1994). El camino hacia la doble hélice: el descubrimiento del ADN . Nueva York: Dover Publications. ISBN 0-486-68117-3.Publicado por primera vez en octubre de 1974 por MacMillan, con prólogo de Francis Crick; el libro de texto definitivo sobre ADN, revisado en 1994 con una posdata de nueve páginas.
- Olby R (enero de 2003). «Debut silencioso de la doble hélice». Nature . 421 (6921): 402–05. Bibcode :2003Natur.421..402O. doi : 10.1038/nature01397 . PMID 12540907.
- Olby RC (2009). Francis Crick: una biografía . Plainview, Nueva York: Cold Spring Harbor Laboratory Press. ISBN 978-0-87969-798-3.
- Micklas D (2003). Ciencia del ADN: un primer curso . Cold Spring Harbor Press. ISBN 978-0-87969-636-8.
- Ridley M (2006). Francis Crick: descubridor del código genético . Ashland, OH: Eminent Lives, Atlas Books. ISBN 0-06-082333-X.
- Rosenfeld I (2010). ADN: una guía gráfica de la molécula que sacudió al mundo . Columbia University Press. ISBN 978-0-231-14271-7.
- Schultz M, Cannon Z (2009). La materia de la vida: una guía gráfica sobre genética y ADN . Hill y Wang. ISBN 978-0-8090-8947-5.
- Stent GS , Watson J (1980). La doble hélice: un relato personal del descubrimiento de la estructura del ADN . Nueva York: Norton. ISBN 0-393-95075-1.
- Watson J (2004). ADN: El secreto de la vida . Random House. ISBN 978-0-09-945184-6.
- Wilkins M (2003). El tercer hombre de la doble hélice. La autobiografía de Maurice Wilkins . Cambridge, Inglaterra: University Press. ISBN 0-19-860665-6.
Enlaces externos
- Predicción del sitio de unión del ADN en proteínas
- El ADN, el juego de la doble hélice Del sitio web oficial del Premio Nobel
- ADN bajo microscopio electrónico
- Centro de aprendizaje de ADN de Dolan
- Doble Hélice: 50 años de ADN y Naturaleza
- ADN de la proteopedia
- Proteopedia Formas de ADN
- Explorador de hilos de ENCODE Página de inicio de ENCODE en Nature
- Doble hélice 1953–2003 Centro Nacional de Educación en Biotecnología
- Módulos de educación genética para docentes: Guía de estudio sobre el ADN desde el principio
- Molécula del mes de PDB ADN
- "Se ha encontrado una pista sobre la química de la herencia". The New York Times , junio de 1953. Primera cobertura periodística estadounidense del descubrimiento de la estructura del ADN
- El ADN desde el principio Otro sitio del Centro de aprendizaje de ADN sobre el ADN, los genes y la herencia desde Mendel hasta el proyecto del genoma humano.
- El registro de documentos personales de Francis Crick, 1938-2007, en la Biblioteca de Colecciones Especiales de Mandeville, Universidad de California, San Diego
- Carta manuscrita de siete páginas que Crick envió a su hijo Michael, de 12 años, en 1953, en la que describía la estructura del ADN. Véase La medalla de Crick se subasta, Nature, 5 de abril de 2013.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
