Perfil de ADN

| Parte de una serie sobre |
| Ciencia forense |
|---|
.png/1280px-Teerahertz_near-field_array_for_%CE%BCm-scale_surface_imaging_(cropped).png) |
El perfil de ADN (también llamado huella genética o huella genética ) es el proceso de determinar las características del ácido desoxirribonucleico ( ADN ) de un individuo . El análisis de ADN destinado a identificar una especie, en lugar de un individuo, se denomina código de barras de ADN .
El perfil de ADN es una técnica forense en las investigaciones criminales que compara los perfiles de los sospechosos con las pruebas de ADN para evaluar la probabilidad de su participación en el crimen. [1] [2] También se utiliza en pruebas de paternidad , [3] para establecer la elegibilidad para la inmigración, [4] y en la investigación genealógica y médica. El perfil de ADN también se ha utilizado en el estudio de poblaciones animales y vegetales en los campos de la zoología, la botánica y la agricultura. [5]
Fondo

A partir de mediados de la década de 1970, los avances científicos permitieron el uso del ADN como material para la identificación de un individuo. La primera patente que cubría el uso directo de la variación del ADN con fines forenses (US5593832A [6] [7] ) fue presentada por Jeffrey Glassberg en 1983, basándose en el trabajo que había realizado mientras estaba en la Universidad Rockefeller de los Estados Unidos en 1981.
El genetista británico Sir Alec Jeffreys desarrolló de forma independiente un proceso de elaboración de perfiles de ADN en 1985 mientras trabajaba en el Departamento de Genética de la Universidad de Leicester . Jeffreys descubrió que un examinador de ADN podía establecer patrones en ADN desconocido. Estos patrones eran parte de los rasgos heredados que podían utilizarse para avanzar en el campo del análisis de relaciones. Estos descubrimientos condujeron al primer uso de la elaboración de perfiles de ADN en un caso penal. [8] [9] [10] [11]
El proceso, desarrollado por Jeffreys en colaboración con Peter Gill y Dave Werrett del Servicio de Ciencias Forenses (FSS), se utilizó por primera vez en el ámbito forense para resolver el asesinato de dos adolescentes que habían sido violadas y asesinadas en Narborough, Leicestershire, en 1983 y 1986. En la investigación del asesinato, dirigida por el detective David Baker, el ADN contenido en muestras de sangre obtenidas voluntariamente de unos 5.000 hombres locales que ayudaron voluntariamente a la policía de Leicestershire con la investigación, dio como resultado la exoneración de Richard Buckland, un sospechoso inicial que había confesado uno de los crímenes, y la posterior condena de Colin Pitchfork el 2 de enero de 1988. Pitchfork, un empleado de una panadería local, había obligado a su compañero de trabajo Ian Kelly a sustituirlo cuando proporcionó una muestra de sangre; Kelly luego utilizó un pasaporte falso para hacerse pasar por Pitchfork. Otro compañero de trabajo denunció el engaño a la policía. Pitchfork fue arrestado y su sangre fue enviada al laboratorio de Jeffreys para su procesamiento y elaboración de un perfil. El perfil de Pitchfork coincidía con el ADN dejado por el asesino, lo que confirmó la presencia de Pitchfork en ambas escenas del crimen; se declaró culpable de ambos asesinatos. [12] Después de algunos años, una empresa química llamada Imperial Chemical Industries (ICI) presentó el primer kit disponible comercialmente en el mundo. A pesar de ser un campo relativamente reciente, tuvo una influencia global significativa tanto en el sistema de justicia penal como en la sociedad. [13]

Aunque el 99,9% de las secuencias de ADN humano son las mismas en cada persona, una cantidad suficiente del ADN es diferente como para que sea posible distinguir a un individuo de otro, a menos que sean gemelos monocigóticos (idénticos) . [14] El perfil de ADN utiliza secuencias repetitivas que son altamente variables, [14] llamadas repeticiones en tándem de número variable (VNTR), en particular repeticiones en tándem cortas (STR), también conocidas como microsatélites y minisatélites . Los loci VNTR son similares entre individuos estrechamente relacionados, pero son tan variables que es poco probable que individuos no relacionados tengan los mismos VNTR.
Antes de los VNTR y los STR, personas como Jeffreys utilizaban un proceso llamado polimorfismo de longitud de fragmentos de restricción (RFLP, por sus siglas en inglés) . Este proceso utilizaba regularmente grandes porciones de ADN para analizar las diferencias entre dos muestras de ADN. El RFLP fue una de las primeras tecnologías utilizadas en la elaboración y el análisis de perfiles de ADN. Sin embargo, a medida que la tecnología evolucionó, surgieron nuevas tecnologías, como el STR, que reemplazaron a tecnologías más antiguas como el RFLP. [15]
La admisibilidad de las pruebas de ADN en los tribunales fue objeto de controversia en los Estados Unidos en los decenios de 1980 y 1990, pero desde entonces ha pasado a ser aceptada de forma más universal gracias a la mejora de las técnicas. [16]
Procesos de elaboración de perfiles
Extracción de ADN
Cuando se obtiene una muestra como sangre o saliva , el ADN es solo una pequeña parte de lo que está presente en la muestra. Antes de que el ADN pueda analizarse, debe extraerse de las células y purificarse. Hay muchas formas de lograr esto, pero todos los métodos siguen el mismo procedimiento básico. Las membranas celulares y nucleares deben romperse para permitir que el ADN esté libre en solución. Una vez que el ADN está libre, puede separarse de todos los demás componentes celulares. Después de que el ADN se haya separado en solución, los restos celulares restantes pueden eliminarse de la solución y descartarse, dejando solo ADN. Los métodos más comunes de extracción de ADN incluyen la extracción orgánica (también llamada extracción con fenol cloroformo ), [17] extracción Chelex y extracción en fase sólida . La extracción diferencial es una versión modificada de la extracción en la que el ADN de dos tipos diferentes de células se puede separar entre sí antes de purificarlo de la solución. Cada método de extracción funciona bien en el laboratorio, pero los analistas generalmente seleccionan su método preferido en función de factores como el costo, el tiempo involucrado, la cantidad de ADN obtenido y la calidad del ADN obtenido. [18]
Análisis RFLP

RFLP significa polimorfismo de longitud de fragmentos de restricción y, en términos de análisis de ADN, describe un método de prueba de ADN que utiliza enzimas de restricción para "cortar" el ADN en secuencias cortas y específicas en toda la muestra. Para comenzar el procesamiento en el laboratorio, la muestra primero debe pasar por un protocolo de extracción, que puede variar según el tipo de muestra o los procedimientos operativos estándar (SOP) del laboratorio. Una vez que el ADN se ha "extraído" de las células dentro de la muestra y se ha separado de los materiales celulares extraños y cualquier nucleasa que pueda degradar el ADN, la muestra se puede introducir en las enzimas de restricción deseadas para cortarla en fragmentos discernibles. Después de la digestión enzimática, se realiza un Southern Blot. Los Southern Blots son un método de separación basado en el tamaño que se realiza en un gel con sondas radiactivas o quimioluminiscentes. RFLP se puede realizar con sondas de un solo locus o de múltiples locus (sondas que se dirigen a una ubicación en el ADN o a múltiples ubicaciones en el ADN). La incorporación de sondas multilocus permitió un mayor poder de discriminación para el análisis, sin embargo, completar este proceso podría llevar desde varios días hasta una semana para una muestra debido a la gran cantidad de tiempo que requiere cada paso para la visualización de las sondas.
Análisis de la reacción en cadena de la polimerasa (PCR)
Esta técnica fue desarrollada en 1983 por Kary Mullis. Actualmente, la PCR es una técnica común e importante que se utiliza en los laboratorios de investigación médica y biológica para una variedad de aplicaciones. [19]
La PCR, o reacción en cadena de la polimerasa, es una técnica de biología molecular ampliamente utilizada para amplificar una secuencia de ADN específica.

La amplificación se consigue mediante una serie de tres pasos:
1- Desnaturalización : En este paso, el ADN se calienta a 95 °C para disociar los enlaces de hidrógeno entre los pares de bases complementarios del ADN de doble cadena.
2-Recocido : durante esta etapa, la reacción se enfría a 50-65 °C . Esto permite que los cebadores se adhieran a una ubicación específica en el ADN monocatenario mediante enlaces de hidrógeno.
3-Extensión : En este paso se utiliza habitualmente una ADN polimerasa termoestable, la Taq polimerasa. Esto se realiza a una temperatura de 72 °C . La ADN polimerasa añade nucleótidos en la dirección 5'-3' y sintetiza la cadena complementaria de la plantilla de ADN.
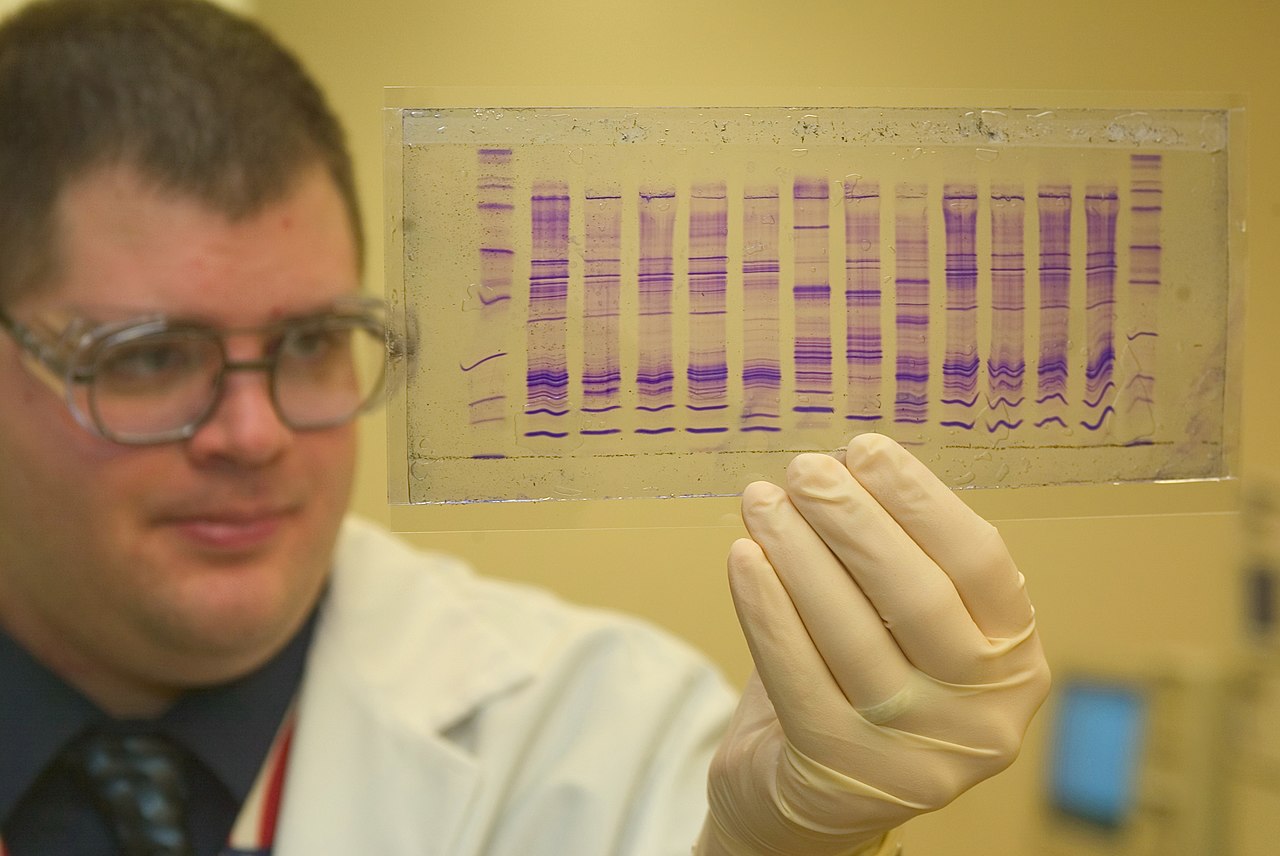
Análisis STR
_analysis.png/1280px-Short_Tandem_Repeat_(STR)_analysis.png)
El sistema de elaboración de perfiles de ADN utilizado hoy en día se basa en la reacción en cadena de la polimerasa (PCR) y utiliza secuencias simples. [9]
En cada país se utilizan distintos sistemas de análisis de ADN basados en STR. En América del Norte, los sistemas que amplifican los 20 loci centrales del CODIS [21] son casi universales, mientras que en el Reino Unido se utiliza el sistema de 17 loci de ADN y en Australia se utilizan 18 marcadores centrales. [22]
El verdadero poder del análisis STR reside en su poder estadístico de discriminación. Debido a que los 20 loci que se utilizan actualmente para la discriminación en CODIS están clasificados de forma independiente (tener una cierta cantidad de repeticiones en un locus no cambia la probabilidad de tener cualquier cantidad de repeticiones en cualquier otro locus), se puede aplicar la regla del producto para las probabilidades . Esto significa que, si alguien tiene el tipo de ADN de ABC, donde los tres loci eran independientes, entonces la probabilidad de que ese individuo tenga ese tipo de ADN es la probabilidad de tener el tipo A multiplicada por la probabilidad de tener el tipo B multiplicada por la probabilidad de tener el tipo C. Esto ha dado como resultado la capacidad de generar probabilidades de coincidencia de 1 en un quintillón (1x10 18 ) o más. [ se necesita más explicación ] Sin embargo, las búsquedas en bases de datos de ADN mostraron coincidencias de perfiles de ADN falsas mucho más frecuentes de lo esperado. [23]
Análisis del cromosoma Y
Debido a la herencia paterna, los haplotipos Y proporcionan información sobre la ascendencia genética de la población masculina. Para investigar esta historia poblacional y proporcionar estimaciones de frecuencias de haplotipos en casos criminales, se creó en 2000 la "base de datos de referencia de haplotipos Y (YHRD)" como recurso en línea. Actualmente comprende más de 300.000 haplotipos mínimos (8 locus) de poblaciones de todo el mundo. [24]
Análisis mitocondrial
El ADNmt se puede obtener de materiales como tallos de cabello y huesos y dientes viejos. [25] Mecanismo de control basado en el punto de interacción con los datos. Esto se puede determinar mediante la colocación de herramientas en la muestra. [26]
Problemas con las muestras de ADN forense
Cuando la gente piensa en el análisis de ADN, a menudo piensa en programas de televisión como NCIS o CSI , que muestran muestras de ADN que llegan a un laboratorio y se analizan instantáneamente, seguidas de la obtención de una fotografía del sospechoso en cuestión de minutos. Sin embargo, la realidad es bastante diferente y, a menudo, no se recogen muestras de ADN perfectas de la escena de un crimen. Las víctimas de homicidio con frecuencia quedan expuestas a duras condiciones antes de ser encontradas, y los objetos que se utilizan para cometer delitos a menudo han sido manipulados por más de una persona. Los dos problemas más frecuentes que encuentran los científicos forenses al analizar muestras de ADN son las muestras degradadas y las mezclas de ADN. [27]
ADN degradado
Antes de que existieran los métodos modernos de PCR, era casi imposible analizar muestras de ADN degradado. Métodos como el polimorfismo de longitud de fragmentos de restricción (RFLP), que fue la primera técnica utilizada para el análisis de ADN en la ciencia forense, requerían ADN de alto peso molecular en la muestra para obtener datos confiables. Sin embargo, el ADN de alto peso molecular falta en las muestras degradadas, ya que el ADN está demasiado fragmentado para realizar el RFLP con precisión. Fue solo cuando se inventaron las técnicas de reacción en cadena de la polimerasa que se pudo realizar el análisis de muestras de ADN degradado. La PCR multiplex en particular hizo posible aislar y amplificar los pequeños fragmentos de ADN que aún quedan en las muestras degradadas. Cuando se comparan los métodos de PCR multiplex con los métodos más antiguos como el RFLP, se puede ver una gran diferencia. La PCR multiplex puede amplificar teóricamente menos de 1 ng de ADN, pero el RFLP tenía que tener al menos 100 ng de ADN para poder realizar un análisis. [28]
ADN de plantilla baja
El ADN de baja plantilla puede ocurrir cuando hay menos de 0,1 ng ( [29] ) de ADN en una muestra. Esto puede conducir a más efectos estocásticos (eventos aleatorios) como la pérdida o la incorporación de alelos que pueden alterar la interpretación de un perfil de ADN. Estos efectos estocásticos pueden conducir a la amplificación desigual de los 2 alelos que provienen de un individuo heterocigoto. Es especialmente importante tener en cuenta el ADN de baja plantilla cuando se trata de una mezcla de muestras de ADN. Esto se debe a que para uno (o más) de los contribuyentes en la mezcla, es más probable que tengan menos de la cantidad óptima de ADN para que la reacción de PCR funcione correctamente. [30] Por lo tanto, se desarrollan umbrales estocásticos para la interpretación del perfil de ADN. El umbral estocástico es la altura mínima del pico (valor RFU), que se ve en un electroferograma donde se produce la pérdida. Si el valor de la altura del pico está por encima de este umbral, entonces es razonable asumir que no se ha producido la pérdida alélica. Por ejemplo, si solo se ve 1 pico para un locus particular en el electroferograma pero su altura de pico está por encima del umbral estocástico, entonces podemos asumir razonablemente que este individuo es homocigoto y no le falta su alelo asociado heterocigoto que de otra manera habría desaparecido debido a tener ADN de plantilla baja. La desaparición de alelos puede ocurrir cuando hay ADN de plantilla baja porque hay tan poco ADN para empezar que en este locus el contribuyente a la muestra de ADN (o mezcla) es un verdadero heterocigoto pero el otro alelo no se amplifica y, por lo tanto, se perdería. La incorporación de alelos [31] también puede ocurrir cuando hay ADN de plantilla baja porque a veces el pico tartamudeado puede amplificarse. El tartamudeo es un artefacto de la PCR. Durante la reacción de PCR, la ADN polimerasa entrará y agregará nucleótidos del cebador, pero todo este proceso es muy dinámico, lo que significa que la ADN polimerasa está constantemente uniendo, desprendiendo y luego volviendo a unirse. Por lo tanto, a veces la ADN polimerasa se unirá nuevamente en la repetición corta en tándem que se encuentra frente a ella, lo que genera una repetición corta en tándem que tiene una repetición menos que la plantilla. Durante la PCR, si la ADN polimerasa se une a un locus en stutter y comienza a amplificarlo para generar muchas copias, este producto de stutter aparecerá aleatoriamente en el electroferograma, lo que generará una inserción alélica.
Análisis MiniSTR
En los casos en que las muestras de ADN están degradadas, como si hay incendios intensos o todo lo que queda son fragmentos de huesos, las pruebas STR estándar en esas muestras pueden ser inadecuadas. Cuando las pruebas STR estándar se realizan en muestras altamente degradadas, los loci STR más grandes a menudo se eliminan y solo se obtienen perfiles de ADN parciales. Los perfiles de ADN parciales pueden ser una herramienta poderosa, pero la probabilidad de una coincidencia aleatoria es mayor que si se obtuviera un perfil completo. Un método que se ha desarrollado para analizar muestras de ADN degradadas es utilizar la tecnología miniSTR. En el nuevo enfoque, los cebadores están especialmente diseñados para unirse más cerca de la región STR. [32]
En las pruebas STR normales, los cebadores se unen a secuencias más largas que contienen la región STR dentro del segmento. Sin embargo, el análisis MiniSTR se dirige solo a la ubicación STR, lo que da como resultado un producto de ADN mucho más pequeño. [32]
Al colocar los cebadores más cerca de las regiones STR reales, hay una mayor probabilidad de que se produzca una amplificación exitosa de esta región. Ahora se puede producir una amplificación exitosa de esas regiones STR y se pueden obtener perfiles de ADN más completos. El éxito de que los productos de PCR más pequeños produzcan una mayor tasa de éxito con muestras altamente degradadas se informó por primera vez en 1995, cuando se utilizó la tecnología miniSTR para identificar a las víctimas del incendio de Waco. [33]
Mezclas de ADN
Las mezclas son otro problema común al que se enfrentan los científicos forenses cuando analizan muestras de ADN desconocidas o cuestionables. Una mezcla se define como una muestra de ADN que contiene dos o más contribuyentes individuales. [28] Esto puede ocurrir a menudo cuando se toma una muestra de ADN de un elemento que es manipulado por más de una persona o cuando una muestra contiene tanto el ADN de la víctima como el del agresor. La presencia de más de un individuo en una muestra de ADN puede dificultar la detección de perfiles individuales, y la interpretación de las mezclas debe ser realizada únicamente por personas altamente capacitadas. Las mezclas que contienen dos o tres individuos pueden interpretarse con dificultad. Las mezclas que contienen cuatro o más individuos son demasiado complicadas para obtener perfiles individuales. Un escenario común en el que a menudo se obtiene una mezcla es en el caso de agresión sexual. Se puede recolectar una muestra que contenga material de la víctima, las parejas sexuales consensuales de la víctima y el o los agresores. [34]
Las mezclas se pueden clasificar en tres categorías: tipo A, tipo B y tipo C. [35] Las mezclas de tipo A tienen alelos con alturas de pico similares en todas partes, por lo que no se puede distinguir a los contribuyentes entre sí. Las mezclas de tipo B se pueden deconvolucionar comparando las proporciones de altura de pico para determinar qué alelos se donaron juntos. Las mezclas de tipo C no se pueden interpretar de manera segura con la tecnología actual porque las muestras se vieron afectadas por la degradación del ADN o tenían una cantidad demasiado pequeña de ADN presente.
Al observar un electroferograma, es posible determinar el número de contribuyentes en mezclas menos complejas en función del número de picos ubicados en cada locus. En comparación con un perfil de fuente única, que solo tendrá uno o dos picos en cada locus, una mezcla es cuando hay tres o más picos en dos o más loci. [36] Si hay tres picos en un solo locus, entonces es posible tener un solo contribuyente que sea tri-alélico en ese locus. [37] Las mezclas de dos personas tendrán entre dos y cuatro picos en cada locus, y las mezclas de tres personas tendrán entre tres y seis picos en cada locus. Las mezclas se vuelven cada vez más difíciles de deconvolucionar a medida que aumenta el número de contribuyentes.
A medida que avanzan los métodos de detección en la elaboración de perfiles de ADN, los científicos forenses están viendo más muestras de ADN que contienen mezclas, ya que incluso el contribuyente más pequeño ahora puede detectarse mediante pruebas modernas. La facilidad con la que los científicos forenses interpenetran mezclas de ADN depende en gran medida de la proporción de ADN presente de cada individuo, las combinaciones de genotipos y la cantidad total de ADN amplificado. [38] La proporción de ADN es a menudo el aspecto más importante a considerar para determinar si una mezcla puede interpretarse. Por ejemplo, si una muestra de ADN tuviera dos contribuyentes, sería fácil interpretar perfiles individuales si la proporción de ADN aportado por una persona fuera mucho mayor que la de la segunda persona. Cuando una muestra tiene tres o más contribuyentes, se vuelve extremadamente difícil determinar perfiles individuales. Afortunadamente, los avances en la genotipificación probabilística pueden hacer posible ese tipo de determinación en el futuro. La genotipificación probabilística utiliza un software informático complejo para ejecutar miles de cálculos matemáticos para producir probabilidades estadísticas de genotipos individuales encontrados en una mezcla. [39]
Perfil de ADN en plantas:
El perfil de ADN de las plantas (huellas dactilares) es un método para identificar cultivares que utiliza técnicas de marcadores moleculares. Este método está ganando atención debido a los derechos de propiedad intelectual relacionados con el comercio (ADPIC) y el Convenio sobre la Diversidad Biológica (CDB). [40]
Ventajas del perfil de ADN vegetal:
La identificación, autenticación, distinción específica, detección de adulteración e identificación de fitoconstituyentes son posibles mediante la huella de ADN en plantas medicinales. [41]
Los marcadores basados en ADN son fundamentales para estas aplicaciones y determinan el futuro del estudio científico en farmacognosia. [41]
También ayuda a determinar los rasgos (como el tamaño de la semilla y el color de las hojas) que probablemente mejorarán la descendencia o no. [42]
Bases de datos de ADN
Una de las primeras aplicaciones de una base de datos de ADN fue la compilación de una Concordancia de ADN Mitocondrial, [43] preparada por Kevin WP Miller y John L. Dawson en la Universidad de Cambridge de 1996 a 1999 [44] a partir de datos recopilados como parte de la tesis doctoral de Miller. Ahora existen varias bases de datos de ADN en todo el mundo. Algunas son privadas, pero la mayoría de las bases de datos más grandes están controladas por el gobierno. Estados Unidos mantiene la base de datos de ADN más grande , con el Sistema de Índice de ADN Combinado (CODIS) que contiene más de 13 millones de registros a mayo de 2018. [45] El Reino Unido mantiene la Base de Datos Nacional de ADN (NDNAD), que es de tamaño similar, a pesar de la menor población del Reino Unido. El tamaño de esta base de datos y su tasa de crecimiento están preocupando a los grupos de libertades civiles en el Reino Unido, donde la policía tiene amplios poderes para tomar muestras y retenerlas incluso en caso de absolución. [46] La coalición conservadora-liberal demócrata abordó parcialmente estas preocupaciones con la parte 1 de la Ley de Protección de las Libertades de 2012 , en virtud de la cual las muestras de ADN deben eliminarse si los sospechosos son absueltos o no acusados, excepto en relación con ciertos delitos (en su mayoría graves o sexuales). El discurso público en torno a la introducción de técnicas forenses avanzadas (como la genealogía genética utilizando bases de datos genealógicos públicos y enfoques de fenotipado de ADN) ha sido limitado, inconexo, desenfocado y plantea cuestiones de privacidad y consentimiento que pueden justificar el establecimiento de protecciones legales adicionales. [47]
La Ley Patriota de los Estados Unidos ofrece un medio para que el gobierno estadounidense obtenga muestras de ADN de presuntos terroristas. La información de ADN de los delitos se recopila y se deposita en la base de datos CODIS , que es mantenida por el FBI . CODIS permite a los funcionarios encargados de hacer cumplir la ley analizar muestras de ADN de delitos para encontrar coincidencias dentro de la base de datos, lo que proporciona un medio para encontrar perfiles biológicos específicos asociados con la evidencia de ADN recopilada. [48]
Cuando se establece una coincidencia a partir de un banco de datos de ADN nacional para vincular una escena del crimen con un delincuente que ha proporcionado una muestra de ADN a una base de datos, ese vínculo se suele denominar coincidencia fría . Una coincidencia fría es útil para remitir a la agencia policial a un sospechoso específico, pero tiene menos valor probatorio que una coincidencia de ADN realizada fuera del banco de datos de ADN. [49]
Los agentes del FBI no pueden almacenar legalmente el ADN de una persona que no haya sido condenada por un delito. El ADN obtenido de un sospechoso que no haya sido condenado posteriormente debe eliminarse y no introducirse en la base de datos. En 1998, un hombre que residía en el Reino Unido fue detenido acusado de robo. Se le extrajo ADN y se analizó, y más tarde fue puesto en libertad. Nueve meses después, el ADN de este hombre se introdujo accidental e ilegalmente en la base de datos de ADN. El nuevo ADN se compara automáticamente con el ADN encontrado en casos sin resolver y, en este caso, se descubrió que este hombre coincidía con el ADN encontrado en un caso de violación y agresión un año antes. El gobierno lo procesó entonces por estos delitos. Durante el juicio se solicitó que se eliminara de la prueba la coincidencia de ADN porque se había introducido ilegalmente en la base de datos. La solicitud se llevó a cabo. [50] El ADN del autor, obtenido de las víctimas de violación, puede almacenarse durante años hasta que se encuentre una coincidencia. En 2014, para abordar este problema, el Congreso amplió un proyecto de ley que ayuda a los estados a lidiar con "una acumulación" de pruebas. [51]
Bases de datos de perfiles de ADN en plantas:
PID:
PIDS (Plant International DNA-fingerprinting System) es un sistema internacional de huellas de ADN de plantas basado en software libre y servidor web de código abierto.
Gestiona enormes cantidades de datos de huellas dactilares de ADN de microsatélites, realiza estudios genéticos y automatiza la recopilación, el almacenamiento y el mantenimiento al tiempo que reduce el error humano y aumenta la eficiencia.
El sistema puede adaptarse a las necesidades específicas del laboratorio, lo que lo convierte en una herramienta valiosa para los cultivadores de plantas, la ciencia forense y el reconocimiento de huellas dactilares humanas.
Realiza un seguimiento de los experimentos, estandariza los datos y promueve la comunicación entre bases de datos.
También ayuda con la regulación de la calidad de las variedades, la preservación de los derechos de las variedades y el uso de marcadores moleculares en el mejoramiento al proporcionar estadísticas de ubicación, fusión, comparación y funciones de análisis genético. [52]
Consideraciones a tener en cuenta al evaluar la evidencia de ADN
Cuando se utiliza RFLP , el riesgo teórico de una coincidencia es de 1 en 100 mil millones (100.000.000.000), aunque el riesgo práctico es en realidad de 1 en 1.000 porque los gemelos monocigóticos son el 0,2% de la población humana. [53] Además, la tasa de error de laboratorio es casi con certeza mayor que eso y los procedimientos de laboratorio reales a menudo no reflejan la teoría bajo la cual se calcularon las probabilidades de coincidencia. Por ejemplo, las probabilidades de coincidencia pueden calcularse en función de las probabilidades de que los marcadores en dos muestras tengan bandas exactamente en la misma ubicación, pero un trabajador de laboratorio puede concluir que los patrones de bandas similares pero no exactamente idénticos resultan de muestras genéticas idénticas con alguna imperfección en el gel de agarosa. Sin embargo, en ese caso, el trabajador de laboratorio aumenta el riesgo de coincidencia al expandir los criterios para declarar una coincidencia. Los estudios realizados en la década de 2000 citaron tasas de error relativamente altas, lo que puede ser motivo de preocupación. [54] En los primeros tiempos de la identificación genética, a veces no se disponía de los datos poblacionales necesarios para calcular con precisión una probabilidad de coincidencia. Entre 1992 y 1996, se establecieron límites arbitrarios y bajos para las probabilidades de coincidencia utilizadas en el análisis RFLP, en lugar de los más altos calculados teóricamente. [55]
Evidencia de relación genética
Es posible utilizar el perfil de ADN como prueba de parentesco genético, aunque la solidez de la prueba varía de débil a positiva. Las pruebas que no muestran ningún parentesco son absolutamente seguras. Además, mientras que casi todos los individuos tienen un conjunto único y distinto de genes, hay individuos extremadamente raros, conocidos como " quimeras ", que tienen al menos dos conjuntos diferentes de genes. Ha habido dos casos de perfiles de ADN que sugirieron falsamente que una madre no tenía parentesco con sus hijos. [56]
Prueba de ADN falsa
El análisis funcional de los genes y sus secuencias codificantes ( marcos de lectura abiertos [ORF]) normalmente requiere que se exprese cada ORF, se purifique la proteína codificada, se produzcan anticuerpos, se examinen los fenotipos, se determine la localización intracelular y se busquen interacciones con otras proteínas. [57] En un estudio realizado por la empresa de ciencias biológicas Nucleix y publicado en la revista Forensic Science International , los científicos descubrieron que se puede construir una muestra sintetizada in vitro de ADN que coincida con cualquier perfil genético deseado utilizando técnicas estándar de biología molecular sin obtener ningún tejido real de esa persona.
Pruebas de ADN en procesos penales
| Evidencia |
|---|
| Parte de la serie de leyes |
| Tipos de evidencia |
| Relevance |
| Authentication |
| Witnesses |
| Hearsay and exceptions |
| Other common law areas |
Búsqueda de ADN familiar
La búsqueda de ADN familiar (a veces denominada "ADN familiar" o "búsqueda en base de datos de ADN familiar") es la práctica de crear nuevas pistas de investigación en casos en los que la evidencia de ADN encontrada en la escena de un crimen (perfil forense) se parece mucho a la de un perfil de ADN existente (perfil del delincuente) en una base de datos de ADN estatal pero no hay una coincidencia exacta. [58] [59] Una vez que se han agotado todas las demás pistas, los investigadores pueden utilizar un software especialmente desarrollado para comparar el perfil forense con todos los perfiles tomados de la base de datos de ADN de un estado para generar una lista de aquellos delincuentes que ya están en la base de datos y que tienen más probabilidades de ser parientes muy cercanos del individuo cuyo ADN está en el perfil forense. [60]
La búsqueda en bases de datos de ADN familiar se utilizó por primera vez en una investigación que condujo a la condena de Jeffrey Gafoor por el asesinato de Lynette White en el Reino Unido el 4 de julio de 2003. Las pruebas de ADN coincidieron con las del sobrino de Gafoor, que a los 14 años aún no había nacido en el momento del asesinato en 1988. Se utilizó de nuevo en 2004 [61] para encontrar a un hombre que arrojó un ladrillo desde un puente de la autopista y atropelló a un conductor de camión, matándolo. El ADN encontrado en el ladrillo coincidía con el encontrado en la escena de un robo de coche más temprano ese día, pero no hubo coincidencias buenas en la base de datos nacional de ADN. Una búsqueda más amplia encontró una coincidencia parcial con un individuo; al ser interrogado, este hombre reveló que tenía un hermano, Craig Harman, que vivía muy cerca de la escena del crimen original. Harman presentó voluntariamente una muestra de ADN y confesó cuando coincidió con la muestra del ladrillo. [62] A partir de 2011, la búsqueda de bases de datos de ADN familiar no se realiza a nivel nacional en los Estados Unidos, donde los estados determinan cómo y cuándo realizar búsquedas familiares. La primera búsqueda de ADN familiar con una condena posterior en los Estados Unidos se llevó a cabo en Denver , Colorado, en 2008, utilizando un software desarrollado bajo el liderazgo del fiscal de distrito de Denver, Mitch Morrissey , y el director del laboratorio criminalístico del Departamento de Policía de Denver, Gregg LaBerge. [63] California fue el primer estado en implementar una política de búsqueda familiar bajo el entonces fiscal general Jerry Brown , quien luego se convirtió en gobernador. [64] En su papel de consultor del Grupo de trabajo de búsqueda familiar del Departamento de Justicia de California , se considera ampliamente que el ex fiscal del condado de Alameda , Rock Harmon, fue el catalizador en la adopción de la tecnología de búsqueda familiar en California. La técnica se utilizó para atrapar al asesino en serie de Los Ángeles conocido como " Grim Sleeper " en 2010. [65] No fue un testigo o informante el que alertó a las fuerzas del orden sobre la identidad del asesino en serie "Grim Sleeper", que había eludido a la policía durante más de dos décadas, sino el ADN del propio hijo del sospechoso. El hijo del sospechoso había sido arrestado y condenado por un delito grave de armas y se le había tomado una muestra de ADN el año anterior. Cuando su ADN se introdujo en la base de datos de delincuentes convictos, los detectives fueron alertados de una coincidencia parcial con la evidencia encontrada en las escenas del crimen de "Grim Sleeper". David Franklin Jr., también conocido como Grim Sleeper, fue acusado de diez cargos de asesinato y un cargo de intento de asesinato. [66] Más recientemente, el ADN familiar condujo al arresto de Elvis García, de 21 años, por cargos de agresión sexual y encarcelamiento injusto de una mujer en Santa Cruz en 2008. [67]En marzo de 2011, el gobernador de Virginia, Bob McDonnell, anunció que Virginia comenzaría a utilizar búsquedas de ADN familiar. [68]
En una conferencia de prensa en Virginia el 7 de marzo de 2011, en relación con el caso del violador de la Costa Este , el fiscal del condado de Prince William, Paul Ebert, y el detective de la policía del condado de Fairfax, John Kelly, dijeron que el caso se habría resuelto hace años si Virginia hubiera utilizado la búsqueda de ADN familiar. Aaron Thomas, el sospechoso del violador de la Costa Este, fue arrestado en relación con la violación de 17 mujeres desde Virginia hasta Rhode Island, pero no se utilizó ADN familiar en el caso. [69]
Los críticos de las búsquedas en bases de datos de ADN familiar argumentan que la técnica es una invasión de los derechos de un individuo bajo la Cuarta Enmienda . [70] Los defensores de la privacidad están pidiendo restricciones a las bases de datos de ADN, argumentando que la única forma justa de buscar posibles coincidencias de ADN con familiares de delincuentes o arrestados sería tener una base de datos de ADN para toda la población. [50] Algunos académicos han señalado que las preocupaciones de privacidad que rodean la búsqueda familiar son similares en algunos aspectos a otras técnicas de búsqueda policial, [71] y la mayoría ha concluido que la práctica es constitucional. [72] El Tribunal de Apelaciones del Noveno Circuito en Estados Unidos v. Pool (anulado por ser discutible) sugirió que esta práctica es algo análoga a un testigo que mira una fotografía de una persona y dice que se parece al perpetrador, lo que lleva a la policía a mostrarle al testigo fotos de individuos de aspecto similar, uno de los cuales es identificado como el perpetrador. [73]
Los críticos también afirman que la discriminación racial podría ocurrir debido a las pruebas de ADN familiares. En los Estados Unidos, las tasas de condenas de las minorías raciales son mucho más altas que las de la población en general. No está claro si esto se debe a la discriminación por parte de los agentes de policía y los tribunales, en lugar de a una simple tasa más alta de delitos entre las minorías. Las bases de datos basadas en arrestos, que se encuentran en la mayoría de los Estados Unidos, conducen a un nivel aún mayor de discriminación racial. Un arresto, a diferencia de una condena, depende mucho más de la discreción policial. [50]
Por ejemplo, los investigadores de la Fiscalía de Distrito de Denver identificaron con éxito a un sospechoso en un caso de robo de propiedad mediante una búsqueda de ADN familiar. En este ejemplo, la sangre del sospechoso que quedó en la escena del crimen se parecía mucho a la de un preso actual del Departamento de Correcciones de Colorado . [63]
Coincidencias parciales
Las coincidencias parciales de ADN son el resultado de búsquedas CODIS de rigurosidad moderada que producen una coincidencia potencial que comparte al menos un alelo en cada locus . [74] La coincidencia parcial no implica el uso de software de búsqueda familiar, como los que se utilizan en el Reino Unido y los Estados Unidos, o análisis Y-STR adicionales y, por lo tanto, a menudo pasa por alto las relaciones entre hermanos. La coincidencia parcial se ha utilizado para identificar sospechosos en varios casos en ambos países [75] y también se ha utilizado como una herramienta para exonerar a los acusados falsamente. Darryl Hunt fue condenado injustamente en relación con la violación y el asesinato de una joven en 1984 en Carolina del Norte . [76]
Recolección subrepticia de ADN
Las fuerzas policiales pueden recoger muestras de ADN sin el conocimiento del sospechoso y utilizarlas como prueba. La legalidad de esta práctica ha sido cuestionada en Australia . [77]
En los Estados Unidos , donde se ha aceptado, los tribunales suelen dictaminar que no hay expectativas de privacidad y citan el caso California v. Greenwood (1988), en el que la Corte Suprema sostuvo que la Cuarta Enmienda no prohíbe el registro y la incautación sin orden judicial de la basura que se deja para su recogida fuera del patio de una casa . Los críticos de esta práctica subrayan que esta analogía ignora que "la mayoría de las personas no tienen idea de que corren el riesgo de entregar su identidad genética a la policía si, por ejemplo, no destruyen una taza de café usada. Además, incluso si se dan cuenta, no hay forma de evitar abandonar el ADN de uno en público". [78]
La Corte Suprema de los Estados Unidos dictaminó en Maryland v. King (2013) que la toma de muestras de ADN de prisioneros arrestados por delitos graves es constitucional. [79] [80] [81]
En el Reino Unido , la Ley de Tejidos Humanos de 2004 prohíbe a los particulares recoger de forma encubierta muestras biológicas (cabello, uñas, etc.) para análisis de ADN, pero exime de la prohibición a las investigaciones médicas y criminales. [82]
Inglaterra y Gales
La prueba de un experto que ha comparado muestras de ADN debe ir acompañada de pruebas sobre las fuentes de las muestras y los procedimientos para obtener los perfiles de ADN. [83] El juez debe asegurarse de que el jurado comprenda la importancia de las coincidencias y las discordancias de ADN en los perfiles. El juez también debe asegurarse de que el jurado no confunda la probabilidad de coincidencia (la probabilidad de que una persona elegida al azar tenga un perfil de ADN coincidente con la muestra de la escena) con la probabilidad de que una persona con ADN coincidente cometiera el delito. En 1996, R v. Doheny [84]
Los jurados deben sopesar las pruebas contradictorias y corroborativas, utilizando su propio sentido común y no utilizando fórmulas matemáticas, como el teorema de Bayes , a fin de evitar "confusión, malentendidos y errores de juicio". [85]
Presentación y evaluación de evidencias de perfiles de ADN parciales o incompletos
En R v Bates , [86] Moore-Bick LJ dijo:
No vemos ninguna razón por la que no se deba admitir la prueba de ADN de perfil parcial, siempre que se informe al jurado de sus limitaciones inherentes y se le dé una explicación suficiente para que pueda evaluarla. Puede haber casos en los que la probabilidad de coincidencia en relación con todas las muestras analizadas sea tan grande que el juez considere que su valor probatorio es mínimo y decida excluir la prueba en el ejercicio de su discreción, pero esto no da lugar a ninguna nueva cuestión de principio y puede dejarse para que se decida caso por caso. Sin embargo, el hecho de que exista en el caso de todas las pruebas de perfil parcial la posibilidad de que un alelo "faltante" pueda exculpar al acusado por completo no proporciona motivos suficientes para rechazar dicha prueba. En muchos casos existe la posibilidad (al menos en teoría) de que exista una prueba que ayude al acusado y tal vez incluso lo exculpe por completo, pero eso no proporciona motivos para excluir la prueba pertinente que está disponible y es admisible de otro modo, aunque sí hace que sea importante garantizar que el jurado reciba suficiente información para que pueda evaluar esa prueba correctamente. [87]
Pruebas de ADN en Estados Unidos
Existen leyes estatales sobre perfiles de ADN en los 50 estados de los Estados Unidos . [88] Se puede encontrar información detallada sobre las leyes de bases de datos en cada estado en el sitio web de la Conferencia Nacional de Legislaturas Estatales . [89]
Desarrollo de ADN artificial
En agosto de 2009, científicos israelíes plantearon serias dudas sobre el uso del ADN por parte de las fuerzas del orden como método definitivo de identificación. En un artículo publicado en la revista Forensic Science International: Genetics , los investigadores israelíes demostraron que es posible fabricar ADN en un laboratorio, falsificando así las pruebas de ADN. Los científicos fabricaron muestras de saliva y sangre que originalmente contenían ADN de una persona distinta del supuesto donante de sangre y saliva. [90]
Los investigadores también demostraron que, utilizando una base de datos de ADN, es posible tomar información de un perfil y fabricar ADN que coincida con ella, y que esto se puede hacer sin acceso a ningún ADN real de la persona cuyo ADN están duplicando. Los oligonucleótidos de ADN sintéticos necesarios para el procedimiento son comunes en los laboratorios moleculares. [90]
El New York Times citó al autor principal, Daniel Frumkin, diciendo: "Se puede diseñar una escena del crimen... cualquier estudiante de biología podría hacerlo". [90] Frumkin perfeccionó una prueba que puede diferenciar muestras de ADN real de las falsas. Su prueba detectamodificaciones epigenéticas , en particular, la metilación del ADN . [91] El setenta por ciento del ADN en cualquier genoma humano está metilado, lo que significa que contiene modificaciones del grupo metilo dentro de un contexto de dinucleótido CpG . La metilación en la región promotora está asociada con el silenciamiento génico. El ADN sintético carece de esta modificación epigenética , lo que permite que la prueba distinga el ADN fabricado del ADN genuino. [90]
Se desconoce cuántos departamentos de policía, si es que hay alguno, utilizan actualmente la prueba. Ningún laboratorio policial ha anunciado públicamente que esté utilizando la nueva prueba para verificar los resultados de ADN. [92]
Los investigadores de la Universidad de Tokio integraron un esquema de replicación de ADN artificial con un sistema de expresión genética reconstruido y microcompartimentación utilizando únicamente materiales libres de células por primera vez. Se realizaron múltiples ciclos de dilución en serie en un sistema contenido en microgotas de agua en aceite. [93]
Posibilidades de realizar cambios intencionados en el ADN
En general, el ADN genómico artificial de este estudio, que siguió copiándose a sí mismo utilizando proteínas autocodificadas y mejoró su secuencia por sí solo, es un buen punto de partida para crear células artificiales más complejas. Al agregar los genes necesarios para la transcripción y la traducción al ADN genómico artificial, es posible que en el futuro sea posible crear células artificiales que puedan crecer por sí solas cuando se las alimenta con pequeñas moléculas como aminoácidos y nucleótidos. El uso de organismos vivos para fabricar cosas útiles, como medicamentos y alimentos, sería más estable y más fácil de controlar en estas células artificiales. [93]
El 7 de julio de 2008, la Sociedad Química Americana informó que unos químicos japoneses habían creado la primera molécula de ADN del mundo compuesta casi en su totalidad por componentes sintéticos.
Un factor de transcripción artificial basado en nanopartículas para la regulación genética:
Nano Script es un factor de transcripción artificial basado en nanopartículas que se supone que replica la estructura y la función de los factores de transcripción. Sobre nanopartículas de oro, se adhirieron péptidos funcionales y moléculas diminutas denominadas factores de transcripción sintéticos, que imitan los diversos dominios de los factores de transcripción, para crear Nano Script. Demostramos que Nano Script se localiza en el núcleo y comienza la transcripción de un plásmido reportero en una cantidad más de 15 veces mayor. Además, Nano Script puede transcribir con éxito genes específicos en ADN endógeno de una manera no viral. [94]
Se fijaron cuidadosamente tres fluoróforos diferentes (rojo, verde y azul) en la superficie de la varilla de ADN para proporcionar información espacial y crear un código de barras a escala nanométrica. La microscopía de fluorescencia de reflexión interna total y epifluorescencia descifró de manera confiable la información espacial entre fluoróforos. Al mover los tres fluoróforos en la varilla de ADN, este código de barras a escala nanométrica creó 216 patrones de fluorescencia. [95]
Casos
- En 1986, Richard Buckland fue exonerado , a pesar de haber admitido la violación y asesinato de una adolescente cerca de Leicester , la ciudad donde se desarrolló por primera vez el perfil de ADN. Este fue el primer uso de la huella de ADN en una investigación criminal, y el primero en demostrar la inocencia de un sospechoso. [96] Al año siguiente, Colin Pitchfork fue identificado como el autor del mismo asesinato, además de otro, utilizando las mismas técnicas que habían exculpado a Buckland. [97]
- En 1987, la huella genética se utilizó por primera vez en un tribunal penal de Estados Unidos en el juicio de un hombre acusado de tener relaciones sexuales ilícitas con una adolescente de 14 años con discapacidad mental que dio a luz a un bebé. [98]
- En 1987, el violador de Florida Tommie Lee Andrews fue la primera persona en los Estados Unidos en ser condenada como resultado de pruebas de ADN, por violar a una mujer durante un robo ; fue declarado culpable el 6 de noviembre de 1987 y sentenciado a 22 años de prisión. [99] [100]
- En 1990, el violento asesinato de un joven estudiante en Brno fue el primer caso criminal en Checoslovaquia resuelto con pruebas de ADN, y el asesino fue condenado a 23 años de prisión. [101] [102]
- En 1992, el ADN de un árbol de palo verde se utilizó para condenar a Mark Alan Bogan por asesinato. Se encontró que el ADN de las vainas de semillas de un árbol en la escena del crimen coincidía con el de las vainas de semillas encontradas en la camioneta de Bogan. Este es el primer caso de ADN de planta admitido en un caso penal. [103] [104] [105]
- En 1994, la afirmación de que Anna Anderson era la Gran Duquesa Anastasia Nikolaevna de Rusia fue puesta a prueba después de su muerte utilizando muestras de su tejido que habían sido almacenadas en un hospital de Charlottesville después de un procedimiento médico. El tejido fue analizado mediante huellas dactilares de ADN y demostró que no tenía ninguna relación con los Romanov . [106]
- En 1994, Earl Washington, Jr. , de Virginia, vio conmutada su sentencia de muerte por cadena perpetua una semana antes de la fecha prevista de su ejecución basándose en pruebas de ADN. Recibió un indulto total en 2000 gracias a pruebas más avanzadas. [107]
- En 1999, Raymond Easton, un hombre discapacitado de Swindon (Inglaterra), fue arrestado y detenido durante siete horas en relación con un robo. Fue puesto en libertad debido a una coincidencia de ADN inexacta. Su ADN se había conservado en el expediente después de un incidente doméstico no relacionado algún tiempo antes. [108]
- En 2000, Frank Lee Smith resultó inocente gracias a un análisis de ADN del asesinato de una niña de ocho años, tras pasar catorce años en el corredor de la muerte en Florida (Estados Unidos). Sin embargo, había muerto de cáncer justo antes de que se demostrara su inocencia. [109] En vista de ello, el gobernador del estado de Florida ordenó que, en el futuro, cualquier preso condenado a muerte que se declarara inocente se sometiera a un análisis de ADN. [107]
- En mayo de 2000, Gordon Graham asesinó a Paul Gault en su casa de Lisburn , Irlanda del Norte. Graham fue condenado por el asesinato cuando se encontró su ADN en una bolsa de deporte dejada en la casa como parte de una elaborada estratagema para sugerir que el asesinato se produjo después de que un robo hubiera salido mal. Graham estaba teniendo una aventura con la esposa de la víctima en el momento del asesinato. Fue la primera vez que se utilizó ADN de bajo número de copias en Irlanda del Norte. [110]
- En 2001, Wayne Butler fue condenado por el asesinato de Celia Douty . Fue el primer asesinato en Australia que se resolvió mediante un análisis de ADN. [111] [112]
- En 2002, el cuerpo de James Hanratty , ahorcado en 1962 por el "asesinato A6", fue exhumado y se analizaron muestras de ADN del cuerpo y de miembros de su familia. Los resultados convencieron a los jueces del Tribunal de Apelación de que la culpabilidad de Hanratty, que había sido enérgicamente cuestionada por los activistas, estaba probada "más allá de toda duda". [113] Paul Foot y algunos otros activistas siguieron creyendo en la inocencia de Hanratty y argumentaron que la evidencia de ADN podría haber sido contaminada, señalando que las pequeñas muestras de ADN de prendas de vestir, guardadas en un laboratorio policial durante más de 40 años "en condiciones que no satisfacen los estándares probatorios modernos", habían tenido que ser sometidas a técnicas de amplificación muy nuevas para obtener un perfil genético. [114] Sin embargo, no se encontró ADN que no fuera el de Hanratty en la evidencia analizada, contrariamente a lo que se habría esperado si la evidencia hubiera estado efectivamente contaminada. [115]
- En agosto de 2002, Annalisa Vicentini fue asesinada a tiros en Toscana . El camarero Peter Hamkin, de 23 años, fue detenido en Merseyside en marzo de 2003 en virtud de una orden de extradición vista en el Juzgado de Magistrados de Bow Street en Londres para determinar si debía ser llevado a Italia para enfrentarse a un cargo de asesinato. El ADN "probó" que él le había disparado, pero fue absuelto con otras pruebas. [116]
- En 2003, el galés Jeffrey Gafoor fue condenado por el asesinato de Lynette White en 1988 , cuando la evidencia de la escena del crimen recolectada 12 años antes fue reexaminada utilizando técnicas STR , lo que resultó en una coincidencia con su sobrino. [117]
- En junio de 2003, gracias a nuevas pruebas de ADN, Dennis Halstead, John Kogut y John Restivo ganaron un nuevo juicio por su condena por asesinato, sus condenas fueron revocadas y fueron liberados. [118]
- En 2004, las pruebas de ADN arrojaron nueva luz sobre la misteriosa desaparición en 1912 de Bobby Dunbar , un niño de cuatro años que desapareció durante un viaje de pesca. Supuestamente fue encontrado vivo ocho meses después bajo la custodia de William Cantwell Walters, pero otra mujer afirmó que el niño era su hijo, Bruce Anderson, a quien había confiado la custodia de Walters. Los tribunales desestimaron su afirmación y condenaron a Walters por el secuestro . El niño fue criado y conocido como Bobby Dunbar durante el resto de su vida. Sin embargo, las pruebas de ADN realizadas al hijo y al sobrino de Dunbar revelaron que los dos no estaban relacionados, estableciendo así que el niño encontrado en 1912 no era Bobby Dunbar, cuyo verdadero destino sigue siendo desconocido. [119]
- En 2005, Gary Leiterman fue condenado por el asesinato en 1969 de Jane Mixer, una estudiante de derecho de la Universidad de Michigan , después de que el ADN encontrado en las medias de Mixer coincidiera con el de Leiterman. El ADN en una gota de sangre en la mano de Mixer coincidió con el de John Ruelas, que tenía solo cuatro años en 1969 y nunca se lo relacionó con el caso de ninguna otra manera. La defensa de Leiterman argumentó sin éxito que la coincidencia inexplicable de la mancha de sangre con Ruelas apuntaba a una contaminación cruzada y planteaba dudas sobre la fiabilidad de la identificación de Leiterman por parte del laboratorio. [120] [121]
- En noviembre de 2008, Anthony Curcio fue arrestado por planear uno de los robos de vehículos blindados más elaborados de la historia. Las pruebas de ADN vincularon a Curcio con el crimen. [122]
- En marzo de 2009, Sean Hodgson —condenado por el asesinato en 1979 de Teresa De Simone , de 22 años, en su coche en Southampton— fue puesto en libertad después de que las pruebas demostraran que el ADN de la escena no era suyo. Más tarde se comparó con el ADN recuperado del cuerpo exhumado de David Lace. Lace había confesado previamente el crimen, pero los detectives no le creyeron . Cumplió condena en prisión por otros delitos cometidos al mismo tiempo que el asesinato y luego se suicidó en 1988. [123]
- En 2012, se descubrió por accidente un caso de bebés intercambiados, muchas décadas antes. Después de realizar pruebas de ADN con otros fines, Alice Collins Plebuch fue informada de que su ascendencia parecía incluir un componente judío asquenazí significativo , a pesar de la creencia en su familia de que eran de ascendencia predominantemente irlandesa . El perfil del genoma de Plebuch sugirió que incluía componentes distintivos e inesperados asociados con las poblaciones asquenazí, de Oriente Medio y de Europa del Este . Esto llevó a Plebuch a realizar una investigación exhaustiva, después de la cual concluyó que su padre había sido intercambiado (posiblemente accidentalmente) con otro bebé poco después del nacimiento. Plebuch también pudo identificar a los antepasados biológicos de su padre. [124] [125]
- En 2016, Anthea Ring, abandonada cuando era bebé, pudo utilizar una muestra de ADN y una base de datos de coincidencias de ADN para descubrir la identidad y las raíces de su madre fallecida en el condado de Mayo , Irlanda. Posteriormente, se utilizó una prueba forense desarrollada recientemente para capturar ADN de la saliva dejada en sellos y sobres viejos por su supuesto padre, descubierta mediante una minuciosa investigación genealógica. El ADN de las primeras tres muestras estaba demasiado degradado para ser utilizado. Sin embargo, en la cuarta, se encontró ADN más que suficiente. La prueba, que tiene un grado de precisión aceptable en los tribunales del Reino Unido, demostró que un hombre llamado Patrick Coyne era su padre biológico. [126] [127]
- En 2018, la niña Buckskin (un cuerpo encontrado en 1981 en Ohio ) fue identificada como Marcia King de Arkansas utilizando técnicas genealógicas de ADN [128]
- En 2018, Joseph James DeAngelo fue arrestado como el principal sospechoso del asesinato del Golden State utilizando técnicas de ADN y genealogía. [129]
- En 2018, William Earl Talbott II fue arrestado como sospechoso de los asesinatos de Jay Cook y Tanya Van Cuylenborg en 1987 con la ayuda de pruebas de ADN genealógico . El mismo genetista genético que ayudó en este caso también ayudó a la policía con otros 18 arrestos en 2018. [130]
- En 2018, con el uso de las capacidades biométricas mejoradas del Sistema de Identificación de Próxima Generación, el FBI comparó la huella digital de un sospechoso llamado Timothy David Nelson y lo arrestó 20 años después de la presunta agresión sexual . [131]
Pruebas de ADN como prueba para demostrar derechos de sucesión a títulos británicos
Se han utilizado pruebas de ADN para establecer el derecho de sucesión a los títulos británicos. [132]
Casos:
Véase también
Referencias
- ^ ab "El momento Eureka que llevó al descubrimiento de la huella genética". The Guardian . 24 de mayo de 2009. Archivado desde el original el 26 de abril de 2021 . Consultado el 11 de diciembre de 2016 .
- ^ Murphy E (13 de octubre de 2017). "Tipificación forense de ADN". Revista anual de criminología . 1 : 497–515. doi :10.1146/annurev-criminol-032317-092127. ISSN 2572-4568.
- ^ Petersen, K., J. Manual de tecnologías de vigilancia . 3.ª edición. Boca Raton, FL. CRC Press, 2012. pág. 815.
- ^ "El momento 'eureka' de un pionero del ADN". BBC . 9 de septiembre de 2009. Archivado desde el original el 22 de agosto de 2017 . Consultado el 14 de octubre de 2011 .
- ^ Chambers GK, Curtis C, Millar CD, Huynen L, Lambert DM (febrero de 2014). "Huellas de ADN en zoología: pasado, presente, futuro". Genética investigativa . 5 (1): 3. doi : 10.1186/2041-2223-5-3 . PMC 3909909 . PMID 24490906.
- ^ "Espacenet - Datos bibliográficos". worldwide.espacenet.com . Consultado el 22 de agosto de 2022 .
- ^ "US5593832.pdf" (PDF) . docs.google.com . Consultado el 22 de agosto de 2022 .
- ^ Wickenheiser, Ray A. (12 de julio de 2019). "Genealogía forense, bioética y el caso del Asesino de Golden State". Ciencia Forense Internacional. Sinergia . 1 : 114–125. doi :10.1016/j.fsisyn.2019.07.003. PMC 7219171. PMID 32411963 .
- ^ ab Tautz D (1989). "Hipervariabilidad de secuencias simples como fuente general de marcadores de ADN polimórficos". Nucleic Acids Research . 17 (16): 6463–6471. doi :10.1093/nar/17.16.6463. PMC 318341 . PMID 2780284.
- ^ US 5766847, Jäckle, Herbert & Tautz, Diethard, "Proceso para analizar polimorfismos de longitud en regiones de ADN", publicado el 16 de junio de 1998, asignado a Max-Planck-Gesellschaft zur Forderung der Wissenschaften
- ^ Jeffreys AJ (noviembre de 2013). "El hombre detrás de las huellas de ADN: una entrevista con el profesor Sir Alec Jeffreys". Genética investigativa . 4 (1): 21. doi : 10.1186/2041-2223-4-21 . PMC 3831583 . PMID 24245655.
- ^ Evans C (2007) [1998]. El libro de casos de detección forense: cómo la ciencia resolvió 100 de los crímenes más desconcertantes del mundo (2.ª ed.). Nueva York: Berkeley Books. págs. 86–89. ISBN 978-1440620539.
- ^ "Perfiles de ADN: una descripción general | Temas de ScienceDirect" www.sciencedirect.com . Consultado el 24 de septiembre de 2023 .
- ^ ab "Uso del ADN en la identificación". Accessexcellence.org. Archivado desde el original el 26 de abril de 2008. Consultado el 3 de abril de 2010 .
- ^ Marks, Kathy (junio de 2009). "Nueva tecnología de ADN para casos sin resolver". Law & Order . 57 (6): 36–38, 40–41, 43. ProQuest 1074789441 – vía Criminal Justice (ProQuest).
- ^ Roth, Andrea (2020). "Capítulo 13: Admisibilidad de la evidencia de ADN en la corte" (PDF) . Facultad de Derecho de la Universidad de California en Berkeley . Consultado el 25 de marzo de 2023 .
Las formas originales de análisis e interpretación de ADN forense utilizadas en la década de 1980 y principios de la de 1990 fueron objeto de muchas críticas durante las "Guerras del ADN", cuya historia ha sido contada hábilmente por otros (Kaye, 2010; Lynch et al., 2008; véase el capítulo 1). Pero estas técnicas anteriores han sido reemplazadas en el análisis de ADN forense por la tipificación de alelos discretos STR basada en PCR. Los tribunales ahora aceptan universalmente como generalmente confiables tanto el proceso de PCR para la amplificación de ADN como el sistema basado en STR para identificar y comparar alelos (Kaye, 2010, págs. 190-191).
- ^ "Extracción de fenol-cloroformo: descripción general | Temas de ScienceDirect" www.sciencedirect.com . Consultado el 28 de octubre de 2023 .
- ^ Butler JM (2005). Tipificación forense de ADN: biología, tecnología y genética de los marcadores STR (2.ª ed.). Ámsterdam: Elsevier Academic Press. ISBN 978-0080470610.OCLC 123448124 .
- ^ Rahman, Md. Tahminur; Uddin, Muhammed Salah; Sultana, Razia; Moue, Arumina; Setu, Muntahina (6 de febrero de 2013). "Reacción en cadena de la polimerasa (PCR): una breve reseña". Revista de la Facultad de Medicina Moderna de Anwer Khan . 4 (1): 30–36. doi : 10.3329/akmmcj.v4i1.13682 . ISSN 2304-5701.
- ^ Imagen de Mikael Häggström, MD, utilizando la siguiente imagen fuente: Figura 1 - disponible bajo licencia: Creative Commons Attribution 4.0 International", del siguiente artículo: Roberta Sitnik, Margareth Afonso Torres, Nydia Strachman Bacal, João Renato Rebello Pinho (2006). "Usando PCR para el monitoreo molecular del quimerismo post-trasplante". Einstein (Sao Paulo) . 4 (2).
{{cite journal}}: CS1 maint: multiple names: authors list (link) - ^ "Sistema de índice de ADN combinado (CODIS)". Oficina Federal de Investigaciones . Archivado desde el original el 29 de abril de 2017. Consultado el 20 de abril de 2017 .
- ^ Curtis C, Hereward J (29 de agosto de 2017). «De la escena del crimen a la sala del tribunal: el viaje de una muestra de ADN». The Conversastion . Archivado desde el original el 25 de julio de 2018. Consultado el 14 de octubre de 2017 .
- ^ Felch J, et al. (20 de julio de 2008). "El FBI se resiste al escrutinio de las 'coincidencias'". Los Angeles Times . pp. P8. Archivado desde el original el 11 de agosto de 2011 . Consultado el 18 de marzo de 2010 .
- ^ "Base de datos de referencia del haplotipo Y". Archivado desde el original el 23 de febrero de 2021 . Consultado el 19 de abril de 2020 .
- ^ Ravikumar D, Gurunathan D, Gayathri R, Priya VV, Geetha RV (1 de enero de 2018). "Perfil de ADN de Streptococcus mutans en niños con y sin manchas dentales negras: un análisis de reacción en cadena de la polimerasa". Revista de investigación dental . 15 (5): 334–339. doi : 10.4103/1735-3327.240472 . PMC 6134728 . PMID 30233653.
- ^ Kashyap VK (2004). "Tecnologías de elaboración de perfiles de ADN en el análisis forense" (PDF) . Revista Internacional de Genética Humana . 4 (1). doi : 10.31901/24566330.2004/04.01.02 . Archivado (PDF) del original el 6 de junio de 2021. Consultado el 6 de junio de 2021 .
- ^ Bieber FR, Buckleton JS, Budowle B, Butler JM, Coble MD (agosto de 2016). "Evaluación de la evidencia de mezcla de ADN forense: protocolo para la evaluación, interpretación y cálculos estadísticos utilizando la probabilidad combinada de inclusión". BMC Genetics . 17 (1): 125. doi : 10.1186/s12863-016-0429-7 . PMC 5007818 . PMID 27580588.
- ^ ab Butler J (2001). "Capítulo 7". Tipificación forense de ADN . Academic Press. págs. 99–115.
- ^ Butler, John M. (2005). Tipificación forense de ADN: biología, tecnología y genética de los marcadores STR (2.ª ed.). Ámsterdam: Elsevier Academic Press. pp. 68, 167–168. ISBN 978-0-12-147952-7.
- ^ Butler, John M. (2015). Temas avanzados en la tipificación forense del ADN: interpretación . Oxford, Inglaterra: Academic Press. pp. 159–161. ISBN 978-0-12-405213-0.
- ^ Gittelson, S; Steffen, CR; Coble, MD (julio de 2016). "ADN de plantilla baja: ¿un único análisis de ADN o dos réplicas?". Forensic Science International . 264 : 139–45. doi :10.1016/j.forsciint.2016.04.012. PMC 5225751 . PMID 27131143.
- ^ ab Coble MD, Butler JM (enero de 2005). "Caracterización de nuevos loci miniSTR para ayudar al análisis de ADN degradado" (PDF) . Journal of Forensic Sciences . 50 (1): 43–53. doi :10.1520/JFS2004216. PMID 15830996. Archivado (PDF) del original el 7 de septiembre de 2017 . Consultado el 24 de noviembre de 2018 .
- ^ Whitaker JP, Clayton TM, Urquhart AJ, Millican ES, Downes TJ, Kimpton CP, Gill P (abril de 1995). "Tipificación de cuerpos de un desastre masivo mediante repetición en tándem corta: alta tasa de éxito y patrones de amplificación característicos en muestras altamente degradadas". BioTechniques . 18 (4): 670–677. PMID 7598902.
- ^ Weir BS, Triggs CM, Starling L, Stowell LI, Walsh KA, Buckleton J (marzo de 1997). «Interpretación de mezclas de ADN» (PDF) . Journal of Forensic Sciences . 42 (2): 213–222. doi :10.1520/JFS14100J. PMID 9068179. Archivado (PDF) del original el 29 de abril de 2020. Consultado el 25 de octubre de 2018 .
- ^ Butler, John M. (2015). Temas avanzados en tipificación forense de ADN: interpretación . Oxford, Inglaterra: Academic Press. p. 140. ISBN 978-0-12-405213-0.
- ^ Butler, John M. (2015). Temas avanzados en tipificación forense de ADN: interpretación . Oxford, Inglaterra: Academic Press. p. 134. ISBN 978-0-12-405213-0.
- ^ "Patrones trialélicos". strbase.nist.gov . Instituto Nacional de Estándares y Tecnología . Consultado el 6 de diciembre de 2022 .
- ^ Butler J (2001). "Capítulo 7". Tipificación forense de ADN . Academic Press. págs. 99–119.
- ^ Laboratorio de la Policía Estatal de Indiana. "Introducción a los índices STRmix y Likelifood" (PDF) . In.gov . Archivado (PDF) del original el 25 de octubre de 2018 . Consultado el 25 de octubre de 2018 .
- ^ "Huellas de ADN de plantas: una visión general".
- ^ ab "Aplicación de la huella de ADN para la identificación de plantas" (PDF) .
- ^ "Huellas de ADN en programas de genética agrícola".
- ^ Miller K. "Concordancia del ADN mitocondrial". Universidad de Cambridge – Antropología biológica. Archivado desde el original el 22 de enero de 2003.
- ^ Miller KW, Dawson JL, Hagelberg E (1996). "Una concordancia de sustituciones de nucleótidos en el primer y segundo segmento hipervariable de la región de control del mtADN humano". Revista Internacional de Medicina Legal . 109 (3): 107–113. doi :10.1007/bf01369668. PMID 8956982. S2CID 19215033.
- ^ "CODIS – Sistema Nacional de Índice de ADN". Fbi.gov. Archivado desde el original el 6 de marzo de 2010. Consultado el 3 de abril de 2010 .
- ^ "Restricciones al uso y destrucción de huellas dactilares y muestras". Wikicrimeline.co.uk. 1 de septiembre de 2009. Archivado desde el original el 23 de febrero de 2007. Consultado el 3 de abril de 2010 .
- ^ Curtis C, Hereward J, Mangelsdorf M, Hussey K, Devereux J (julio de 2019). "Protección de la confianza en la genética médica en la nueva era de la ciencia forense" (PDF) . Genética en Medicina . 21 (7): 1483–1485. doi :10.1038/s41436-018-0396-7. PMC 6752261 . PMID 30559376. Archivado (PDF) del original el 25 de octubre de 2021 . Consultado el 22 de septiembre de 2019 .
- ^ Price-Livingston S (5 de junio de 2003). "Disposiciones sobre pruebas de ADN en la Ley Patriota". Asamblea General de Connecticut . Archivado desde el original el 29 de julio de 2020. Consultado el 18 de enero de 2018 .
- ^ Goos L, Rose JD. DNA: A Practical Guide. Toronto: Carswell Publications . Archivado desde el original el 5 de junio de 2019. Consultado el 5 de junio de 2019 .
- ^ abc Cole SA (1 de agosto de 2007). «Double Helix Jeopardy». IEEE Spectrum . Archivado desde el original el 29 de septiembre de 2019. Consultado el 6 de junio de 2019 .
- ^ "El Congreso aprueba un proyecto de ley para reducir la acumulación de pruebas de violación". Associated Press. Archivado desde el original el 30 de julio de 2020. Consultado el 18 de septiembre de 2014 .
- ^ Jiang, Bin; Zhao, Yikun; Yi, Hongmei; Huo, Yongxue; Wu, haotiano; Ren, Jie; Ge, Jianrong; Zhao, Jiuran; Wang, Fengge (30 de marzo de 2020). "PIDS: un sistema de gestión de bases de datos de huellas dactilares de ADN vegetal fácil de usar". Genes . 11 (4): 373. doi : 10.3390/genes11040373 . ISSN 2073-4425. PMC 7230844 . PMID 32235513.
- ^ Schiller J (2010). Mapeo genómico para determinar la susceptibilidad a enfermedades . CreateSpace . ISBN 978-1453735435.
- ^ Walsh NP (27 de enero de 2002). «Temor a resultados falsos en las pruebas de ADN». The Observer . Archivado desde el original el 25 de octubre de 2021.
- ^ Comité del Consejo Nacional de Investigación (EE. UU.) sobre Ciencia Forense del ADN: Una actualización (1996). La evaluación de la evidencia forense del ADN. Washington, DC: National Academy Press. doi :10.17226/5141. ISBN 978-0309053952. PMID 25121324. Archivado desde el original el 30 de agosto de 2008.
- ^ "Dos mujeres no tienen el ADN de sus hijos como corresponde". Abcnews.go.com. 15 de agosto de 2006. Archivado desde el original el 28 de octubre de 2013. Consultado el 3 de abril de 2010 .
- ^ Hartley JL, Temple GF, Brasch MA (noviembre de 2000). "Clonación de ADN mediante recombinación específica de sitio in vitro". Genome Research . 10 (11): 1788–1795. doi :10.1101/gr.143000. PMC 310948 . PMID 11076863.
- ^ Diamond D (12 de abril de 2011). "Buscando en el árbol genealógico de ADN para resolver crímenes". HuffPost Denver (Blog). The Huffington Post. Archivado desde el original el 14 de abril de 2011. Consultado el 17 de abril de 2011 .
- ^ Bieber FR, Brenner CH, Lazer D (junio de 2006). "Genética humana. Encontrar criminales a través del ADN de sus familiares". Science . 312 (5778): 1315–1316. doi : 10.1126/science.1122655 . PMID 16690817. S2CID 85134694.

- ^ Staff. «Las búsquedas familiares permiten a las fuerzas del orden identificar a los delincuentes a través de sus familiares». DNA Forensics . Reino Unido: pionero en búsquedas familiares. Archivado desde el original el 7 de noviembre de 2010 . Consultado el 7 de diciembre de 2015 .
- ^ Bhattacharya S (20 de abril de 2004). "Asesino condenado gracias al ADN de un familiar". Daily News. New Scientist . Archivado desde el original el 8 de diciembre de 2015. Consultado el 17 de abril de 2011 .
- ^ Greely HT, Riordan DP, Garrison NA, Mountain JL (verano de 2006). "Lazos familiares: el uso de bases de datos de ADN de delincuentes para atrapar a los parientes de los delincuentes" (PDF) . Simposio. The Journal of Law, Medicine & Ethics . 34 (2): 248–262. doi :10.1111/j.1748-720x.2006.00031.x. PMID 16789947. S2CID 1718295. Archivado (PDF) desde el original el 8 de diciembre de 2015. Consultado el 8 de diciembre de 2015 .
- ^ ab Pankratz H (17 de abril de 2011). "Denver usa 'pruebas de ADN familiar' para resolver robos de autos". The Denver Post . Archivado desde el original el 19 de octubre de 2012.
- ^ Steinhaur J (9 de julio de 2010). "Los fanáticos del arresto de 'Grim Sleeper' debaten sobre el uso del ADN". The New York Times . Archivado desde el original el 25 de octubre de 2021. Consultado el 17 de abril de 2011 .
- ^ Dolan M. "Una nueva pista en la búsqueda de ADN" (PDF) . LA Times . Archivado desde el original (PDF) el 2 de diciembre de 2010 . Consultado el 17 de abril de 2011 .
- ^ "Una nueva técnica de ADN llevó a la policía al 'sombrío asesino en serie' y 'cambiará la forma de actuar de la policía en Estados Unidos'". ABC News . Archivado desde el original el 30 de julio de 2020.
- ^ Dolan M (15 de marzo de 2011). "La búsqueda de ADN familiar utilizada en el caso Grim Sleeper conduce al arresto de un delincuente sexual de Santa Cruz". LA Times . Archivado desde el original el 21 de marzo de 2011. Consultado el 17 de abril de 2011 .
- ^ Helderman R. "McDonnell aprueba el ADN familiar para la lucha contra el crimen en el Departamento de Asuntos de los Veteranos". The Washington Post . Archivado desde el original el 25 de octubre de 2021. Consultado el 17 de abril de 2011 .
- ^ Christoffersen J, Barakat M. "Se buscan otras víctimas de sospechoso de violación en la Costa Este". Associated Press. Archivado desde el original el 28 de junio de 2011. Consultado el 25 de mayo de 2011 .
- ^ Murphy EA (2009). "Relative Doubt: Familial Searches of DNA Databases" (PDF) . Michigan Law Review . 109 : 291–348. Archivado desde el original (PDF) el 1 de diciembre de 2010.
- ^ Suter S (2010). "All in The Family: Privacy and DNA Familial Searching" (PDF) . Harvard Journal of Law and Technology . 23 : 328. Archivado desde el original (PDF) el 7 de junio de 2011.
- ^ Kaye, David H., (2013). "Los detectives de la genealogía: un análisis constitucional de la búsqueda familiar", American Criminal Law Review, vol. 51, núm. 1, 109-163, 2013.
- ^ "US v. Pool" (PDF) . Pool 621F .3d 1213 . Archivado desde el original (PDF) el 27 de abril de 2011.
- ^ "Cómo encontrar criminales mediante pruebas de ADN a sus familiares" Boletín técnico, Chromosomal Laboratories, Inc., consultado el 22 de abril de 2011.
- ^ "Recursos de ADN del fiscal de distrito de Denver". Archivado desde el original el 24 de marzo de 2011. Consultado el 20 de abril de 2011 .
- ^ "Darryl Hunt". El Proyecto Inocencia . Archivado desde el original el 28 de agosto de 2007.
- ^ Easteal PW, Easteal S (3 de noviembre de 2017). "El uso forense de los perfiles de ADN". Instituto Australiano de Criminología . Archivado desde el original el 19 de febrero de 2019. Consultado el 18 de febrero de 2019 .
- ^ Harmon A (3 de abril de 2008). "Los abogados luchan contra las muestras de ADN obtenidas a escondidas". The New York Times . Archivado desde el original el 25 de octubre de 2021.
- ^ "La Corte Suprema de Estados Unidos permite la toma de muestras de ADN de prisioneros". UPI. Archivado desde el original el 10 de junio de 2013. Consultado el 3 de junio de 2013 .
- ^ "Corte Suprema de los Estados Unidos – Resumen: Maryland v. King, Certiorari ante la Corte de Apelaciones de Maryland" (PDF) . Archivado (PDF) del original el 24 de agosto de 2017 . Consultado el 27 de junio de 2017 .
- ^ Samuels JE, Davies EH, Pope DB (junio de 2013). Recolección de ADN en el momento del arresto: políticas, prácticas e implicaciones (PDF) . Justice Policy Center (Informe). Washington, DC: Urban Institute . Archivado desde el original (PDF) el 22 de octubre de 2015.
- ^ "Ley de tejidos humanos de 2004". Reino Unido. Archivado desde el original el 6 de marzo de 2008. Consultado el 7 de abril de 2017 .
{{cite web}}: CS1 maint: bot: original URL status unknown (link) - ^ R contra Loveridge , EWCA Crim 734 (2001).
- ^ R v. Doheny [1996] EWCA Crim 728, [1997] 1 Cr App R 369 (31 de julio de 1996), Tribunal de Apelaciones
- ^ R v. Adams [1997] EWCA Crim 2474 (16 de octubre de 1997), Tribunal de Apelaciones
- ^ R v Bates [2006] EWCA Crim 1395 (7 de julio de 2006), Tribunal de Apelaciones
- ^ "Perfiles de ADN de WikiCrimeLine". Wikicrimeline.co.uk. Archivado desde el original el 22 de octubre de 2010. Consultado el 3 de abril de 2010 .
- ^ "Genelex: el sitio de pruebas de paternidad por ADN". Healthanddna.com. 6 de enero de 1996. Archivado desde el original el 29 de diciembre de 2010. Consultado el 3 de abril de 2010 .
- ^ "Base de datos de ciencia forense: búsqueda por estado". NCSL.org. Archivado desde el original el 11 de noviembre de 2018. Consultado el 21 de marzo de 2019 .
- ^ abcd Pollack A (18 de agosto de 2009). «Los científicos demuestran que las pruebas de ADN pueden fabricarse». The New York Times . Archivado desde el original el 25 de octubre de 2021. Consultado el 1 de abril de 2010 .
- ^ Rana AK (2018). "Investigación criminal a través del análisis de metilación del ADN: métodos y aplicaciones en la ciencia forense". Revista egipcia de ciencias forenses . 8 . doi : 10.1186/s41935-018-0042-1 .
- ^ Frumkin D, Wasserstrom A, Davidson A, Grafit A (febrero de 2010). "Authentication of forensic DNA samples" (Autenticación de muestras de ADN forense). Forensic Science International. Genetics (Genética) . 4 (2): 95–103. CiteSeerX 10.1.1.179.2718 . doi :10.1016/j.fsigen.2009.06.009. PMID 20129467. Archivado desde el original el 19 de agosto de 2014. Consultado el 3 de abril de 2010 .
- ^ ab Genomics, Front Line; Mobley, Immy (22 de noviembre de 2021). "¿El uso de ADN genómico artificial es el futuro? - Front Line Genomics". Front Line Genomics: cómo hacer llegar los beneficios de la genómica a los pacientes con mayor rapidez . Consultado el 9 de octubre de 2022 .
- ^ Patel, Sahishnu; Jung, Dongju; Yin, Perry T.; Carlton, Peter; Yamamoto, Makoto; Bando, Toshikazu; Sugiyama, Hiroshi; Lee, Ki-Bum (20 de agosto de 2014). "NanoScript: un factor de transcripción artificial basado en nanopartículas para una regulación génica eficaz". ACS Nano . 8 (9): 8959–8967. doi :10.1021/nn501589f. ISSN 1936-0851. PMC 4174092 . PMID 25133310.
- ^ Qi, Hao; Huang, Guoyou; Han, Yulong; Zhang, Xiaohui; Li, Yuhui; Pingguan-Murphy, Belinda; Lu, Tian Jian; Xu, Feng; Wang, Lin (1 de junio de 2015). "Ingeniería de máquinas artificiales a partir de materiales de ADN diseñables para aplicaciones biomédicas". Ingeniería de tejidos. Parte B, Revisiones . 21 (3): 288–297. doi :10.1089/ten.teb.2014.0494. ISSN 1937-3368. PMC 4442581 . PMID 25547514.
- ^ "El momento 'eureka' de un pionero del ADN". BBC News . 9 de septiembre de 2009. Archivado desde el original el 22 de agosto de 2017 . Consultado el 1 de abril de 2010 .
- ^ Joseph Wambaugh, The Blooding (Nueva York, Nueva York: A Perigord Press Book, 1989), 369.
- ^ Joseph Wambaugh, The Blooding (Nueva York, Nueva York: A Perigord Press Book, 1989), 316.
- ^ "Gene Technology". Txtwriter.com. 6 de noviembre de 1987. pág. 14. Archivado desde el original el 27 de noviembre de 2002. Consultado el 3 de abril de 2010 .
- ^ "frontline: the case for innocence: the dna revolution: state and federal dna database laws examination" (en inglés). Pbs.org. Archivado desde el original el 19 de marzo de 2011. Consultado el 3 de abril de 2010 .
- ^ "Jak usvědčit vraha omilostněného prezidentem?" (en checo). Radio Checa . 29 de enero de 2020. Archivado desde el original el 11 de abril de 2021 . Consultado el 24 de agosto de 2020 .
- ^ Jedlička M. «Milan Lubas, agresor sexual y asesino». Traducido por Vršovský P. Kriminalistika.eu. Archivado desde el original el 30 de diciembre de 2020. Consultado el 24 de agosto de 2020 .
- ^ "Tribunal de Apelaciones de Arizona: Denegación de la moción de Bogan para revertir su condena y sentencia" (PDF) . Fiscalía de Denver: www.denverda.org. 11 de abril de 2005. Archivado desde el original (PDF) el 24 de julio de 2011. Consultado el 21 de abril de 2011 .
- ^ "Análisis forense del ADN: las angiospermas como testigos de la acusación". Proyecto Genoma Humano. Archivado desde el original el 29 de abril de 2011. Consultado el 21 de abril de 2011 .
- ^ "Crime Scene Botanicals". Botanical Society of America. Archivado desde el original el 22 de diciembre de 2008. Consultado el 21 de abril de 2011 .
- ^ Gill P, Ivanov PL, Kimpton C, Piercy R, Benson N, Tully G, et al. (febrero de 1994). "Identificación de los restos de la familia Romanov mediante análisis de ADN". Nature Genetics . 6 (2): 130–135. doi :10.1038/ng0294-130. PMID 8162066. S2CID 33557869.
- ^ ab Murnaghan I (28 de diciembre de 2012). «Famous Trials and DNA Testing; Earl Washington Jr». Explorar ADN . Archivado desde el original el 3 de noviembre de 2014. Consultado el 13 de noviembre de 2014 .
- ^ Jeffries S (8 de octubre de 2006). "Suspect Nation". The Guardian . Londres. Archivado desde el original el 25 de octubre de 2021 . Consultado el 1 de abril de 2010 .
- ^ "Frank Lee Smith". Facultad de Derecho de la Universidad de Michigan, Registro Nacional de Exoneraciones . Junio de 2012. Archivado desde el original el 29 de noviembre de 2014. Consultado el 13 de noviembre de 2014 .
- ^ Stephen G (17 de febrero de 2008). "¿Libertad en la bolsa para el asesino Graham?". Belfasttelegraph.co.uk. Archivado desde el original el 17 de octubre de 2012. Consultado el 19 de junio de 2010 .
- ↑ Dutter B (19 de junio de 2001). «18 años después, un hombre es encarcelado por el asesinato de un británico en el 'paraíso'». The Telegraph . Londres. Archivado desde el original el 7 de diciembre de 2008 . Consultado el 17 de junio de 2008 .
- ^ McCutcheon P (8 de septiembre de 2004). «Las pruebas de ADN pueden no ser infalibles: expertos». Australian Broadcasting Corporation . Archivado desde el original el 11 de febrero de 2009. Consultado el 17 de junio de 2008 .
- ^ Joshua Rozenberg, "El ADN prueba la culpabilidad de Hanratty 'más allá de toda duda'", Daily Telegraph , Londres, 11 de mayo de 2002.
- ^ Steele (23 de junio de 2001). "Los abogados de Hanratty rechazan la 'culpa' del ADN". Daily Telegraph . Londres, Reino Unido. Archivado desde el original el 11 de octubre de 2018.
- ^ "Hanratty: El ADN condenatorio". BBC News . 10 de mayo de 2002. Archivado desde el original el 28 de febrero de 2009 . Consultado el 22 de agosto de 2011 .
- ^ "Reclamo de identidad errónea por asesinato". BBC News . 15 de febrero de 2003. Archivado desde el original el 21 de agosto de 2017 . Consultado el 1 de abril de 2010 .
- ^ Sekar S. "Caso Lynette White: cómo los forenses atraparon al hombre del celofán". Lifeloom.com. Archivado desde el original el 25 de noviembre de 2010. Consultado el 3 de abril de 2010 .
- ^ "Dennis Halstead". Registro Nacional de Exoneraciones, Facultad de Derecho de la Universidad de Michigan . 18 de abril de 2014. Archivado desde el original el 2 de abril de 2015. Consultado el 12 de enero de 2015 .
- ^ Breed AG (5 de mayo de 2004). «El ADN exculpa a un hombre de la condena por secuestro en 1914». USA Today . Associated Press . Archivado desde el original el 14 de septiembre de 2012.
- ^ "Caso de asesinato de Jane Mixer". CBS News . Archivado desde el original el 17 de septiembre de 2008. Consultado el 24 de marzo de 2007 .
- ^ "impugnación de la condena de Leiterman por el asesinato de Mixer". www.garyisinnocent.org . Archivado desde el original el 22 de diciembre de 2016.
- ^ Doughery P. "DB Tuber". Enlace histórico. Archivado desde el original el 5 de diciembre de 2014. Consultado el 30 de noviembre de 2014 .
- ^ Booth J. «La policía señala a David Lace como el verdadero asesino de Teresa De Simone». The Times . Archivado desde el original el 25 de octubre de 2021. Consultado el 20 de noviembre de 2015 .
- ^ "¿Quién era ella? Una prueba de ADN reveló nuevos misterios". The Washington Post . Archivado desde el original el 6 de junio de 2018. Consultado el 9 de abril de 2018 .
- ^ "Pensé que era irlandés, hasta que me hice una prueba de ADN". The Irish Times . Archivado desde el original el 9 de abril de 2018. Consultado el 9 de abril de 2018 .
- ^ "¿Quiénes eran mis padres y por qué me dejaron morir en una ladera?". BBC News . Archivado desde el original el 18 de mayo de 2018. Consultado el 21 de julio de 2018 .
- ^ "El ADN vivo permite cerrar la búsqueda de un padre biológico". ADN vivo . 19 de marzo de 2018. Archivado desde el original el 10 de abril de 2018 . Consultado el 9 de abril de 2018 .
- ^ "Caso de "Buckskin Girl": descubrimiento de ADN permite identificar a víctima de asesinato en 1981". CBS News . 12 de abril de 2018. Archivado desde el original el 22 de junio de 2018 . Consultado el 19 de mayo de 2018 .
- ^ Zhang S (17 de abril de 2018). «Cómo un sitio web de genealogía condujo al supuesto asesino de Golden State». The Atlantic . Archivado desde el original el 28 de abril de 2018. Consultado el 19 de mayo de 2018 .
- ^ Michaeli Y (16 de noviembre de 2018). "Para resolver casos sin resolver, todo lo que se necesita es ADN de la escena del crimen, un sitio de genealogía e Internet de alta velocidad". Haaretz . Archivado desde el original el 6 de diciembre de 2018. Consultado el 6 de diciembre de 2018 .
- ^ "La tecnología de huellas dactilares ayuda a resolver un caso sin resolver". Oficina Federal de Investigaciones . Consultado el 18 de septiembre de 2022 .
- ^ "Sentencia en el asunto de la Baronetía de Pringle de Stichill" (PDF) . 20 de junio de 2016. Archivado (PDF) del original el 23 de enero de 2017 . Consultado el 26 de octubre de 2017 .
Lectura adicional
- Kaye DH (2010). La doble hélice y la ley de la evidencia. Cambridge, MA: Harvard University Press. ISBN 978-0674035881.OCLC 318876881 .
- Koerner BI (13 de octubre de 2015). «Family Ties: Your Relatives' DNA Could Turn You Into a Suspect» (artículo) . Wired . pp. 35–38. ISSN 1059-1028 . Consultado el 6 de junio de 2019 .
- Dunning, Brian (1 de marzo de 2022). «Skeptoid #821: Ciencia (pseudo) forense». Skeptoid . Consultado el 15 de mayo de 2022 .
Enlaces externos
- McKie R (24 de mayo de 2009). "El momento eureka que condujo al descubrimiento de la huella genética". The Observer . Londres.
- Ciencia forense, estadísticas y derecho: blog que sigue los avances científicos y legales relacionados con el perfil de ADN forense
- Crea una huella de ADN – PBS.org
- Simulación in silico de técnicas de biología molecular: un lugar para aprender técnicas de mecanografía mediante simulación
- Bases de datos nacionales de ADN en la UE
- The Innocence Record Archivado el 13 de septiembre de 2019 en Wayback Machine , Winston & Strawn LLP/The Innocence Project
- Dando sentido a los atrasos en materia de ADN, 2012: mitos frente a realidad Departamento de Justicia de los Estados Unidos
- "Dar sentido a la genética forense". Sense about Science . 25 de enero de 2017. Consultado el 19 de abril de 2020 .




{kind=link}
.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
_analysis.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}