Red de Hopfield
Una red de Hopfield (o memoria asociativa ) es una forma de red neuronal recurrente , o un sistema de vidrio de espín , que puede servir como una memoria direccionable por contenido . La red de Hopfield, llamada así por John Hopfield , consta de una sola capa de neuronas, donde cada neurona está conectada a todas las demás neuronas excepto a sí misma. Estas conexiones son bidireccionales y simétricas, lo que significa que el peso de la conexión de la neurona i a la neurona j es el mismo que el peso de la neurona j a la neurona i . Los patrones se recuerdan asociativamente fijando ciertas entradas y evolucionan dinámicamente la red para minimizar una función de energía, hacia estados mínimos de energía locales que corresponden a patrones almacenados. Los patrones se aprenden asociativamente (o se "almacenan") mediante un algoritmo de aprendizaje hebbiano .
Una de las características clave de las redes de Hopfield es su capacidad de recuperar patrones completos a partir de entradas parciales o ruidosas, lo que las hace robustas frente a datos incompletos o corruptos. Su conexión con la mecánica estadística, las redes recurrentes y la psicología cognitiva humana ha llevado a su aplicación en varios campos, entre ellos la física , la psicología , la neurociencia y la teoría y la práctica del aprendizaje automático.
Historia

Uno de los orígenes de la memoria asociativa es la psicología cognitiva humana , en concreto la memoria asociativa . Frank Rosenblatt estudió los "perceptrones de acoplamiento cruzado de bucle cerrado", que son redes de perceptrones de tres capas cuya capa intermedia contiene conexiones recurrentes que cambian según una regla de aprendizaje hebbiana . [1] : 73–75 [2] : Capítulo 19, 21
Otro modelo de memoria asociativa es aquel en el que la salida no vuelve a la entrada. (Taylor, 1956) propuso un modelo de este tipo entrenado mediante aprendizaje hebbiano. [3] Karl Steinbuch , que quería comprender el aprendizaje e inspirado al ver a sus hijos aprender, [4] publicó la Lernmatrix en 1961. [5] [6] Fue traducida al inglés en 1963. [7] Se realizó una investigación similar con el correlograma de (DJ Willshaw et al., 1969). [8] En ( Teuvo Kohonen , 1974) [9] se entrenó una memoria asociativa mediante descenso de gradiente.

Otro origen de la memoria asociativa fue la mecánica estadística . El modelo de Ising fue publicado en los años 1920 como un modelo de magnetismo, sin embargo estudiaba el equilibrio térmico, que no cambia con el tiempo. Roy J. Glauber en 1963 estudió el modelo de Ising evolucionando en el tiempo, como un proceso hacia el equilibrio térmico ( dinámica de Glauber ), añadiendo el componente del tiempo. [10]
El segundo componente que se añadió fue la adaptación al estímulo. Descrita independientemente por Kaoru Nakano en 1971 [11] [12] y Shun'ichi Amari en 1972 [13], propusieron modificar los pesos de un modelo de Ising mediante la regla de aprendizaje hebbiana como modelo de memoria asociativa. La misma idea fue publicada por William A. Little en 1974 [14], a quien Hopfield reconoció en su artículo de 1982.
Véase Carpenter (1989) [15] y Cowan (1990) [16] para una descripción técnica de algunos de estos primeros trabajos en memoria asociativa.
El modelo de Sherrington-Kirkpatrick del vidrio de espín, publicado en 1975, [17] es la red de Hopfield con inicialización aleatoria. Sherrington y Kirkpatrick descubrieron que es muy probable que la función de energía del modelo SK tenga muchos mínimos locales. En el artículo de 1982, Hopfield aplicó esta teoría recientemente desarrollada para estudiar la red de Hopfield con funciones de activación binarias. [18] En un artículo de 1984, la extendió a funciones de activación continua. [19] Se convirtió en un modelo estándar para el estudio de redes neuronales a través de la mecánica estadística. [20] [21]
Dimitry Krotov y Hopfield desarrollaron un avance importante en la capacidad de almacenamiento de memoria en 2016 [22] a través de un cambio en la dinámica de la red y la función de energía. Esta idea fue ampliada aún más por Demircigil y colaboradores en 2017. [23] La dinámica continua de los modelos de gran capacidad de memoria se desarrolló en una serie de artículos entre 2016 y 2020. [22] [24] [25] Las redes de Hopfield de gran capacidad de almacenamiento de memoria ahora se denominan memorias asociativas densas o redes de Hopfield modernas .
En 2024, John J. Hopfield y Geoffrey E. Hinton recibieron el premio Nobel de Física por sus contribuciones fundamentales al aprendizaje automático, como la red Hopfield.
Estructura

Las unidades en las redes de Hopfield son unidades de umbral binarias, es decir, las unidades solo toman dos valores diferentes para sus estados, y el valor está determinado por si la entrada de la unidad excede o no su umbral . Las redes de Hopfield discretas describen relaciones entre neuronas binarias (que se activan o no) . [18] En un momento determinado, el estado de la red neuronal se describe mediante un vector , que registra qué neuronas se activan en una palabra binaria de bits.




Las interacciones entre neuronas tienen unidades que suelen tomar valores de 1 o −1, y esta convención se utilizará a lo largo de este artículo. Sin embargo, otra literatura puede utilizar unidades que toman valores de 0 y 1. Estas interacciones se "aprenden" a través de la ley de asociación de Hebb , de modo que, para un determinado estado y nodos distintos




pero .

(Tenga en cuenta que la regla de aprendizaje hebbiana toma la forma cuando las unidades asumen valores en ).


Una vez que la red está entrenada, ya no evoluciona. Si se introduce un nuevo estado de neuronas en la red neuronal, la red actúa sobre las neuronas de tal manera que

- si
- si




donde es el valor umbral de la i-ésima neurona (que a menudo se toma como 0). [26] De esta manera, las redes de Hopfield tienen la capacidad de "recordar" estados almacenados en la matriz de interacción, porque si un nuevo estado se somete a la matriz de interacción, cada neurona cambiará hasta que coincida con el estado original (ver la sección Actualizaciones a continuación).
Las conexiones en una red Hopfield normalmente tienen las siguientes restricciones:
- (ninguna unidad tiene conexión consigo misma)
- (las conexiones son simétricas)


La restricción de que los pesos son simétricos garantiza que la función de energía disminuya monótonamente mientras sigue las reglas de activación. [27] Una red con pesos asimétricos puede exhibir algún comportamiento periódico o caótico; sin embargo, Hopfield encontró que este comportamiento está confinado a partes relativamente pequeñas del espacio de fase y no afecta la capacidad de la red para actuar como un sistema de memoria asociativa direccionable por contenido.
Hopfield también modeló redes neuronales para valores continuos, en las que la salida eléctrica de cada neurona no es binaria sino algún valor entre 0 y 1. [19] Descubrió que este tipo de red también era capaz de almacenar y reproducir estados memorizados.
Nótese que cada par de unidades i y j en una red de Hopfield tiene una conexión que se describe mediante el peso de conectividad . En este sentido, la red de Hopfield puede describirse formalmente como un grafo completo no dirigido , donde es un conjunto de neuronas McCulloch-Pitts y es una función que vincula pares de unidades a un valor real, el peso de conectividad.


Actualizando
La actualización de una unidad (nodo en el gráfico que simula la neurona artificial) en la red de Hopfield se realiza utilizando la siguiente regla:

dónde:
- es la fuerza del peso de la conexión de la unidad j a la unidad i (el peso de la conexión).
- es el estado de la unidad i.
- es el umbral de la unidad i.


Las actualizaciones en la red Hopfield se pueden realizar de dos maneras diferentes:
- Asíncrono : solo se actualiza una unidad a la vez. Esta unidad puede elegirse al azar o puede imponerse un orden predefinido desde el principio.
- Sincrónico : todas las unidades se actualizan al mismo tiempo. Esto requiere un reloj central en el sistema para mantener la sincronización. Algunos consideran que este método es menos realista, ya que no se observa un reloj global que influya en los sistemas biológicos o físicos análogos de interés.
Las neuronas "se atraen o se repelen entre sí" en el espacio de estados
El peso entre dos unidades tiene un gran impacto en los valores de las neuronas. Consideremos el peso de conexión entre dos neuronas i y j. Si , la regla de actualización implica que:

- Cuando , la contribución de j en la suma ponderada es positiva. Por lo tanto, j la atrae hacia su valor.
- Cuando , la contribución de j en la suma ponderada es negativa. Por lo tanto, j empuja hacia su valor.




Por lo tanto, los valores de las neuronas i y j convergerán si el peso entre ellas es positivo. De manera similar, divergirán si el peso es negativo.
Propiedades de convergencia de redes de Hopfield discretas y continuas
En su artículo de 1990 [28], Bruck estudió redes de Hopfield discretas y demostró un teorema de convergencia generalizado que se basa en la conexión entre la dinámica de la red y los cortes en el grafo asociado. Esta generalización cubrió tanto la dinámica asincrónica como la sincrónica y presentó pruebas elementales basadas en algoritmos voraces para el corte máximo en grafos. Un artículo posterior [29] investigó más a fondo el comportamiento de cualquier neurona en redes de Hopfield tanto de tiempo discreto como de tiempo continuo cuando la función de energía correspondiente se minimiza durante un proceso de optimización. Bruck demostró [28] que la neurona j cambia su estado si y solo si disminuye aún más el siguiente pseudocorte sesgado. La red de Hopfield discreta minimiza el siguiente pseudocorte sesgado [29] para la matriz de peso sináptico de la red de Hopfield.

donde y representa el conjunto de neuronas que son −1 y +1, respectivamente, en el momento . Para más detalles, consulte el artículo reciente. [29]



La red de Hopfield de tiempo discreto siempre minimiza exactamente el siguiente pseudocorte [28] [29]

La red de Hopfield de tiempo continuo siempre minimiza un límite superior para el siguiente corte ponderado [29]

donde es una función sigmoidea centrada en cero.

Por otra parte, la red compleja de Hopfield generalmente tiende a minimizar el llamado corte de sombra de la matriz de peso compleja de la red. [30]
Energía
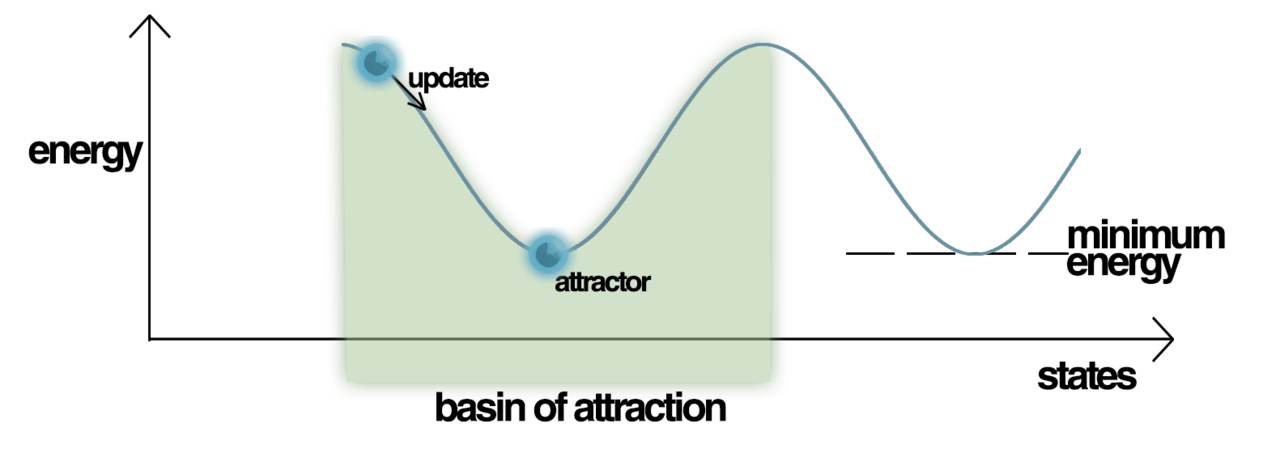
Las redes de Hopfield tienen un valor escalar asociado a cada estado de la red, denominado "energía", E , de la red, donde:

Esta cantidad se llama "energía" porque disminuye o permanece igual a medida que se actualizan las unidades de la red. Además, bajo actualizaciones repetidas, la red eventualmente convergerá a un estado que es un mínimo local en la función de energía (que se considera una función de Lyapunov ). [18] Por lo tanto, si un estado es un mínimo local en la función de energía, es un estado estable para la red. Tenga en cuenta que esta función de energía pertenece a una clase general de modelos en física bajo el nombre de modelos de Ising ; estos a su vez son un caso especial de redes de Markov , ya que la medida de probabilidad asociada , la medida de Gibbs , tiene la propiedad de Markov .
Red de Hopfield en optimización
Hopfield y Tank presentaron la aplicación de la red de Hopfield para resolver el problema clásico del viajante de comercio en 1985. [31] Desde entonces, la red de Hopfield se ha utilizado ampliamente para la optimización. La idea de utilizar la red de Hopfield en problemas de optimización es sencilla: si una función de costo restringida/sin restricciones se puede escribir en la forma de la función de energía de Hopfield E, entonces existe una red de Hopfield cuyos puntos de equilibrio representan soluciones al problema de optimización restringida/sin restricciones. Al minimizar la función de energía de Hopfield se minimiza la función objetivo y también se satisfacen las restricciones, ya que las restricciones están "incrustadas" en los pesos sinápticos de la red. Aunque incluir las restricciones de optimización en los pesos sinápticos de la mejor manera posible es una tarea desafiante, muchos problemas de optimización difíciles con restricciones en diferentes disciplinas se han convertido a la función de energía de Hopfield: sistemas de memoria asociativa, conversión de analógico a digital, problema de programación de talleres, asignación cuadrática y otros problemas NP-completos relacionados, problema de asignación de canales en redes inalámbricas, problema de enrutamiento de redes móviles ad-hoc, restauración de imágenes, identificación de sistemas, optimización combinatoria, etc., solo por nombrar algunos. Sin embargo, si bien es posible convertir problemas de optimización difíciles a funciones de energía de Hopfield, no garantiza la convergencia a una solución (incluso en tiempo exponencial). [32]
Inicialización y ejecución
La inicialización de las redes de Hopfield se realiza estableciendo los valores de las unidades en el patrón de inicio deseado. Luego se realizan actualizaciones repetidas hasta que la red converge a un patrón atractor. La convergencia generalmente está asegurada, ya que Hopfield demostró que los atractores de este sistema dinámico no lineal son estables, no periódicos o caóticos como en otros sistemas [ cita requerida ] . Por lo tanto, en el contexto de las redes de Hopfield, un patrón atractor es un estado estable final, un patrón que no puede cambiar ningún valor dentro de él bajo actualización [ cita requerida ] .
Capacitación
El entrenamiento de una red de Hopfield implica reducir la energía de los estados que la red debe "recordar". Esto permite que la red sirva como un sistema de memoria direccionable por contenido, es decir, la red convergerá a un estado "recordado" si se le proporciona solo una parte del estado. La red se puede utilizar para recuperarse de una entrada distorsionada al estado entrenado que sea más similar a esa entrada. Esto se llama memoria asociativa porque recupera recuerdos en función de la similitud. Por ejemplo, si entrenamos una red de Hopfield con cinco unidades de modo que el estado (1, −1, 1, −1, 1) sea un mínimo de energía, y le damos a la red el estado (1, −1, −1, −1, 1) convergerá a (1, −1, 1, −1, 1). Por lo tanto, la red está correctamente entrenada cuando la energía de los estados que la red debe recordar son mínimos locales. Tenga en cuenta que, a diferencia del entrenamiento del Perceptrón , los umbrales de las neuronas nunca se actualizan.
Reglas de aprendizaje
Existen varias reglas de aprendizaje diferentes que se pueden utilizar para almacenar información en la memoria de la red de Hopfield. Es deseable que una regla de aprendizaje tenga las dos propiedades siguientes:
- Local : una regla de aprendizaje es local si cada peso se actualiza utilizando la información disponible para las neuronas en cada lado de la conexión asociada con ese peso en particular.
- Incremental : Se pueden aprender nuevos patrones sin utilizar información de los patrones antiguos que también se han utilizado para el entrenamiento. Es decir, cuando se utiliza un nuevo patrón para el entrenamiento, los nuevos valores de los pesos dependen únicamente de los valores antiguos y del nuevo patrón. [33]
Estas propiedades son deseables, ya que una regla de aprendizaje que las satisfaga es biológicamente más plausible. Por ejemplo, dado que el cerebro humano siempre está aprendiendo nuevos conceptos, se puede razonar que el aprendizaje humano es incremental. Un sistema de aprendizaje que no fuera incremental generalmente se entrenaría solo una vez, con un lote enorme de datos de entrenamiento.
Regla de aprendizaje hebbiana para redes de Hopfield
La teoría hebbiana fue introducida por Donald Hebb en 1949 para explicar el "aprendizaje asociativo", en el que la activación simultánea de células neuronales conduce a aumentos pronunciados en la fuerza sináptica entre esas células. [34] A menudo se resume como "Las neuronas que se activan juntas se conectan entre sí. Las neuronas que se activan fuera de sincronía no se conectan".
La regla de Hebb es tanto local como incremental. Para las redes de Hopfield, se implementa de la siguiente manera al aprender patrones binarios:


donde representa el bit i del patrón .


Si los bits correspondientes a las neuronas i y j son iguales en patrón , entonces el producto será positivo. Esto, a su vez, tendrá un efecto positivo en el peso y los valores de i y j tenderán a ser iguales. Lo contrario sucede si los bits correspondientes a las neuronas i y j son diferentes.

Regla de aprendizaje de Storkey
Esta regla fue introducida por Amos Storkey en 1997 y es tanto local como incremental. Storkey también demostró que una red de Hopfield entrenada utilizando esta regla tiene una mayor capacidad que una red correspondiente entrenada utilizando la regla de Hebb. [35] Se dice que la matriz de pesos de una red neuronal atractora [ aclaración necesaria ] sigue la regla de aprendizaje de Storkey si obedece:

donde es una forma de campo local [33] en la neurona i.

Esta regla de aprendizaje es local, ya que las sinapsis toman en cuenta únicamente las neuronas que se encuentran a sus lados. La regla utiliza más información de los patrones y pesos que la regla hebbiana generalizada, debido al efecto del campo local.
Patrones espurios
Los patrones que la red utiliza para el entrenamiento (llamados estados de recuperación ) se convierten en atractores del sistema. Las actualizaciones repetidas eventualmente conducirían a la convergencia a uno de los estados de recuperación. Sin embargo, a veces la red convergerá a patrones espurios (distintos de los patrones de entrenamiento). [36] De hecho, la cantidad de patrones espurios puede ser exponencial en la cantidad de patrones almacenados, incluso si los patrones almacenados son ortogonales. [37] La energía en estos patrones espurios también es un mínimo local. Para cada patrón almacenado x, la negación -x también es un patrón espurio.
Un estado espurio también puede ser una combinación lineal de un número impar de estados de recuperación. Por ejemplo, al utilizar 3 patrones , se puede obtener el siguiente estado espurio:


No pueden existir patrones espurios que tengan un número par de estados, ya que podrían sumar cero [36]
Capacidad
La capacidad de red del modelo de red de Hopfield está determinada por la cantidad de neuronas y conexiones dentro de una red dada. Por lo tanto, la cantidad de recuerdos que se pueden almacenar depende de las neuronas y las conexiones. Además, se demostró que la precisión de recuperación entre vectores y nodos fue de 0,138 (aproximadamente se pueden recuperar 138 vectores del almacenamiento por cada 1000 nodos) (Hertz et al., 1991). Por lo tanto, es evidente que se producirán muchos errores si uno intenta almacenar una gran cantidad de vectores. Cuando el modelo de Hopfield no recupera el patrón correcto, es posible que se haya producido una intrusión, ya que los elementos semánticamente relacionados tienden a confundir al individuo y se produce el recuerdo del patrón incorrecto. Por lo tanto, se demuestra que el modelo de red de Hopfield confunde un elemento almacenado con el de otro al recuperarlo. Los recuerdos perfectos y la alta capacidad, >0,14, se pueden cargar en la red mediante el método de aprendizaje de Storkey; ETAM, [38] [39] Los experimentos de ETAM también se realizaron en. [40] Más tarde se idearon modelos posteriores inspirados en la red de Hopfield para aumentar el límite de almacenamiento y reducir la tasa de error de recuperación, y algunos de ellos fueron capaces de aprender de una sola vez . [41]
La capacidad de almacenamiento se puede expresar como donde es el número de neuronas en la red.

Memoria humana
La red de Hopfield es un modelo para el aprendizaje y la recuperación asociativa humana. [42] [43] Explica la memoria asociativa mediante la incorporación de vectores de memoria. Los vectores de memoria se pueden utilizar ligeramente, y esto provocaría la recuperación del vector más similar en la red. Sin embargo, descubriremos que debido a este proceso, pueden ocurrir intrusiones. En la memoria asociativa para la red de Hopfield, hay dos tipos de operaciones: autoasociación y heteroasociación. La primera es cuando un vector se asocia consigo mismo, y la segunda es cuando dos vectores diferentes se asocian en el almacenamiento. Además, ambos tipos de operaciones son posibles de almacenar dentro de una sola matriz de memoria, pero solo si esa matriz de representación dada no es una u otra de las operaciones, sino más bien la combinación (autoasociativa y heteroasociativa) de las dos.
El modelo de red de Hopfield utiliza la misma regla de aprendizaje que la regla de aprendizaje de Hebb (1949) , que caracterizaba el aprendizaje como resultado del fortalecimiento de los pesos en casos de actividad neuronal.
Rizzuto y Kahana (2001) pudieron demostrar que el modelo de red neuronal puede explicar la repetición en la precisión de la evocación al incorporar un algoritmo de aprendizaje probabilístico. Durante el proceso de recuperación, no se produce aprendizaje. Como resultado, los pesos de la red permanecen fijos, lo que demuestra que el modelo puede cambiar de una etapa de aprendizaje a una etapa de evocación. Al agregar la deriva contextual, pudieron demostrar el olvido rápido que ocurre en un modelo de Hopfield durante una tarea de evocación con señales. La red completa contribuye al cambio en la activación de cualquier nodo individual.
La regla dinámica de McCulloch y Pitts (1943), que describe el comportamiento de las neuronas, lo hace de una manera que muestra cómo las activaciones de múltiples neuronas se relacionan con la activación de la tasa de disparo de una nueva neurona, y cómo los pesos de las neuronas fortalecen las conexiones sinápticas entre la nueva neurona activada (y las que la activaron). Hopfield usaría la regla dinámica de McCulloch-Pitts para mostrar cómo es posible la recuperación en la red de Hopfield. Sin embargo, Hopfield lo haría de manera repetitiva. Hopfield usaría una función de activación no lineal, en lugar de una función lineal. Esto crearía la regla dinámica de Hopfield y con esto, Hopfield pudo mostrar que con la función de activación no lineal, la regla dinámica siempre modificará los valores del vector de estado en la dirección de uno de los patrones almacenados.
Memoria asociativa densa o red de Hopfield moderna
Las redes de Hopfield [18] [19] son redes neuronales recurrentes con trayectorias dinámicas que convergen a estados atractores de punto fijo y se describen mediante una función de energía. El estado de cada neurona del modelo se define mediante una variable dependiente del tiempo , que puede elegirse como discreta o continua. Un modelo completo describe las matemáticas de cómo el estado futuro de actividad de cada neurona depende de la actividad presente o previa conocida de todas las neuronas.


En el modelo original de Hopfield de memoria asociativa, [18] las variables eran binarias y la dinámica se describía mediante una actualización del estado de las neuronas una a una. Se definió una función de energía cuadrática en la , y la dinámica consistía en cambiar la actividad de cada neurona individual solo si al hacerlo se reducía la energía total del sistema. Esta misma idea se extendió al caso de ser una variable continua que representa la salida de la neurona , y ser una función monótona de una corriente de entrada. La dinámica se expresó como un conjunto de ecuaciones diferenciales de primer orden para las que la "energía" del sistema siempre disminuía. [19] La energía en el caso continuo tiene un término que es cuadrático en la (como en el modelo binario), y un segundo término que depende de la función de ganancia (la función de activación de la neurona). Si bien tienen muchas propiedades deseables de la memoria asociativa, ambos sistemas clásicos sufren de una pequeña capacidad de almacenamiento de memoria, que escala linealmente con el número de características de entrada. [18] Por el contrario, al aumentar el número de parámetros en el modelo de modo que no solo haya interacciones por pares sino también de orden superior entre las neuronas, se puede aumentar la capacidad de almacenamiento de la memoria. [44] [45]

Las memorias asociativas densas [22] (también conocidas como las modernas redes de Hopfield [24] ) son generalizaciones de las redes de Hopfield clásicas que rompen la relación de escala lineal entre el número de características de entrada y el número de memorias almacenadas. Esto se logra introduciendo no linealidades más fuertes (ya sea en la función de energía o en las funciones de activación de las neuronas) que conducen a una capacidad de almacenamiento de memoria superlineal [22] (incluso exponencial [23] ) en función del número de neuronas de características, lo que en efecto aumenta el orden de las interacciones entre las neuronas. [44] [45] La red aún requiere una cantidad suficiente de neuronas ocultas. [25]
La idea teórica clave detrás de las redes de memoria asociativa densa es utilizar una función de energía y una regla de actualización que tiene un pico más pronunciado alrededor de las memorias almacenadas en el espacio de las configuraciones de las neuronas en comparación con el modelo clásico, [22] como se demuestra cuando las interacciones de orden superior y los paisajes de energía posteriores se modelan explícitamente. [45]
Variables discretas
Un ejemplo simple [22] de la red de Hopfield moderna se puede escribir en términos de variables binarias que representan el estado activo e inactivo de la neurona modelo . En esta fórmula, los pesos representan la matriz de vectores de memoria (el índice enumera diferentes memorias y el índice enumera el contenido de cada memoria correspondiente a la neurona característica -ésima), y la función es una función no lineal de rápido crecimiento. La regla de actualización para neuronas individuales (en el caso asincrónico) se puede escribir en la siguiente forma que establece que para calcular el estado actualizado de la neurona -ésima, la red compara dos energías: la energía de la red con la neurona -ésima en el estado ON y la energía de la red con la neurona -ésima en el estado OFF, dados los estados de la neurona restante. El estado actualizado de la neurona -ésima selecciona el estado que tiene la energía más baja de las dos. [22]







![{\displaystyle V_{i}^{(t+1)}=Signo{\bigg [}\suma \límites _{\mu =1}^{N_{\text{mem}}}{\bigg (}F{\Big (}\xi _{\mu i}+\suma \límites _{j\neq i}\xi _{\mu j}V_{j}^{(t)}{\Big )}-F{\Big (}-\xi _{\mu i}+\suma \límites _{j\neq i}\xi _{\mu j}V_{j}^{(t)}{\Big )}{\bigg )}{\bigg ]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1f610dc9c7b006debf54cab514e242c9dbc1ac72)
En el caso límite cuando la función de energía no lineal es cuadrática, estas ecuaciones se reducen a la función de energía familiar y la regla de actualización para la red binaria clásica de Hopfield. [18]

La capacidad de almacenamiento de memoria de estas redes se puede calcular para patrones binarios aleatorios. Para la función de energía de potencia, el número máximo de memorias que se pueden almacenar y recuperar de esta red sin errores está dado por [22]. Para una función de energía exponencial, la capacidad de almacenamiento de memoria es exponencial en el número de neuronas características [23].







Variables continuas
Las redes de Hopfield modernas o memorias asociativas densas se pueden entender mejor en variables continuas y tiempo continuo. [24] [25] Considere la arquitectura de red, que se muestra en la Fig. 1, y las ecuaciones para la evolución de los estados de las neuronas [25]
| ( 1 ) |

donde las corrientes de las neuronas características se denotan por , y las corrientes de las neuronas de memoria se denotan por ( representa neuronas ocultas). No hay conexiones sinápticas entre las neuronas características o las neuronas de memoria. Una matriz denota la fuerza de las sinapsis de una neurona característica a la neurona de memoria . Se supone que las sinapsis son simétricas, de modo que el mismo valor caracteriza una sinapsis física diferente de la neurona de memoria a la neurona característica . Las salidas de las neuronas de memoria y las neuronas características se denotan por y , que son funciones no lineales de las corrientes correspondientes. En general, estas salidas pueden depender de las corrientes de todas las neuronas en esa capa de modo que y . Es conveniente definir estas funciones de activación como derivadas de las funciones lagrangianas para los dos grupos de neuronas.








| ( 2 ) |

De esta manera, la forma específica de las ecuaciones para los estados de las neuronas queda completamente definida una vez que se especifican las funciones lagrangianas. Finalmente, las constantes de tiempo para los dos grupos de neuronas se denotan por y , es la corriente de entrada a la red que puede ser impulsada por los datos presentados.




Los sistemas generales de ecuaciones diferenciales no lineales pueden tener muchos comportamientos complicados que pueden depender de la elección de las no linealidades y las condiciones iniciales. Sin embargo, para las redes de Hopfield, este no es el caso: las trayectorias dinámicas siempre convergen a un estado atractor de punto fijo. Esta propiedad se logra porque estas ecuaciones están diseñadas específicamente para que tengan una función de energía subyacente [25].
| ( 3 ) |
![{\displaystyle E(t)={\Big [}\suma \límites _{i=1}^{N_{f}}(x_{i}-I_{i})g_{i}-L_{x}{\Big ]}+{\Big [}\suma \límites _{\mu =1}^{N_{h}}h_{\mu }f_{\mu }-L_{h}{\Big ]}-\suma \límites _{\mu ,i}f_{\mu }\xi _{\mu i}g_{i}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/49e7d96e213a43700492bcdcc56832be110a2f0d)
Los términos agrupados entre corchetes representan una transformada de Legendre de la función lagrangiana con respecto a los estados de las neuronas. Si las matrices hessianas de las funciones lagrangianas son semidefinidas positivas, se garantiza que la función de energía decrecerá en la trayectoria dinámica [25].
| ( 4 ) |

Esta propiedad permite demostrar que el sistema de ecuaciones dinámicas que describe la evolución temporal de las actividades de las neuronas alcanzará eventualmente un estado atractor de punto fijo.
En ciertas situaciones se puede asumir que la dinámica de las neuronas ocultas se equilibra en una escala de tiempo mucho más rápida en comparación con las neuronas características, . En este caso, la solución de estado estable de la segunda ecuación en el sistema ( 1 ) se puede utilizar para expresar las corrientes de las unidades ocultas a través de las salidas de las neuronas características. Esto hace posible reducir la teoría general ( 1 ) a una teoría efectiva solo para neuronas características. Las reglas de actualización efectivas resultantes y las energías para varias elecciones comunes de las funciones lagrangianas se muestran en la Fig.2. En el caso de la función lagrangiana exponencial de suma logarítmica, la regla de actualización (si se aplica una vez) para los estados de las neuronas características es el mecanismo de atención [24] comúnmente utilizado en muchos sistemas de IA modernos (ver Ref. [25] para la derivación de este resultado a partir de la formulación de tiempo continuo).

Relación con la red clásica de Hopfield con variables continuas
La formulación clásica de las redes de Hopfield continuas [19] puede entenderse [25] como un caso límite especial de las redes de Hopfield modernas con una capa oculta. Las redes de Hopfield continuas para neuronas con respuesta graduada se describen típicamente [19] mediante las ecuaciones dinámicas
| ( 5 ) |

y la función energética
| ( 6 ) |

donde , y es la inversa de la función de activación . Este modelo es un límite especial de la clase de modelos que se denomina modelos A, [25] con la siguiente elección de las funciones lagrangianas



| ( 7 ) |

que, según la definición ( 2 ), conduce a las funciones de activación
| ( 8 ) |

Si integramos las neuronas ocultas, el sistema de ecuaciones ( 1 ) se reduce a las ecuaciones de las neuronas características ( 5 ) con , y la expresión general para la energía ( 3 ) se reduce a la energía efectiva

| ( 9 ) |

Mientras que los dos primeros términos en la ecuación ( 6 ) son los mismos que aquellos en la ecuación ( 9 ), los terceros términos parecen superficialmente diferentes. En la ecuación ( 9 ) es una transformada de Legendre del Lagrangiano para las neuronas características, mientras que en ( 6 ) el tercer término es una integral de la función de activación inversa. Sin embargo, estas dos expresiones son de hecho equivalentes, ya que las derivadas de una función y su transformada de Legendre son funciones inversas entre sí. La forma más fácil de ver que estos dos términos son iguales explícitamente es diferenciar cada uno con respecto a . Los resultados de estas diferenciaciones para ambas expresiones son iguales a . Por lo tanto, las dos expresiones son iguales hasta una constante aditiva. Esto completa la prueba [25] de que la Red de Hopfield clásica con estados continuos [19] es un caso límite especial de la red de Hopfield moderna ( 1 ) con energía ( 3 ).


Formulación general de la red de Hopfield moderna


Las redes neuronales biológicas tienen un alto grado de heterogeneidad en términos de diferentes tipos de células. Esta sección describe un modelo matemático de una red de Hopfield moderna completamente conectada asumiendo el grado extremo de heterogeneidad: cada neurona es diferente. [46] Específicamente, se describe una función de energía y las ecuaciones dinámicas correspondientes asumiendo que cada neurona tiene su propia función de activación y escala de tiempo cinético. Se supone que la red está completamente conectada, de modo que cada neurona está conectada a todas las demás neuronas utilizando una matriz simétrica de pesos , índices y enumera diferentes neuronas en la red, consulte la Figura 3. La forma más fácil de formular matemáticamente este problema es definir la arquitectura a través de una función lagrangiana que depende de las actividades de todas las neuronas en la red. La función de activación para cada neurona se define como una derivada parcial de la lagrangiana con respecto a la actividad de esa neurona.



| ( 10 ) |

Desde una perspectiva biológica, se puede pensar en la función de activación como una salida axonal de la neurona . En el caso más simple, cuando la función de Lagrangian es aditiva para diferentes neuronas, esta definición da como resultado una activación que es una función no lineal de la actividad de esa neurona. Para las funciones de Lagrangian no aditivas, esta función de activación puede depender de las actividades de un grupo de neuronas. Por ejemplo, puede contener normalización contrastiva (softmax) o divisiva. Las ecuaciones dinámicas que describen la evolución temporal de una neurona dada se dan en [46].

| ( 11 ) |

Esta ecuación pertenece a la clase de modelos denominados modelos de tasa de disparo en neurociencia. Cada neurona recoge las salidas axónicas de todas las neuronas, las pondera con los coeficientes sinápticos y produce su propia actividad dependiente del tiempo . La evolución temporal tiene una constante de tiempo que, en general, puede ser diferente para cada neurona. Esta red tiene una función energética global [46]



| ( 12 ) |

donde los dos primeros términos representan la transformada de Legendre de la función de Lagrange con respecto a las corrientes de las neuronas . La derivada temporal de esta función de energía se puede calcular sobre las trayectorias dinámicas que conducen a (ver [46] para más detalles)
| ( 13 ) |

El último signo de desigualdad se cumple siempre que la matriz (o su parte simétrica) sea semidefinida positiva. Si, además de esto, la función de energía está acotada por debajo, se garantiza que las ecuaciones dinámicas no lineales convergerán a un estado atractor de punto fijo. La ventaja de formular esta red en términos de las funciones lagrangianas es que permite experimentar fácilmente con diferentes opciones de funciones de activación y diferentes disposiciones arquitectónicas de neuronas. Para todas esas opciones flexibles, las condiciones de convergencia están determinadas por las propiedades de la matriz y la existencia de la cota inferior de la función de energía.



Red de memoria asociativa jerárquica
Las neuronas se pueden organizar en capas de modo que cada neurona en una capa dada tenga la misma función de activación y la misma escala de tiempo dinámica. Si suponemos que no hay conexiones horizontales entre las neuronas dentro de la capa (conexiones laterales) y no hay conexiones de capa saltada, la red general completamente conectada ( 11 ), ( 12 ) se reduce a la arquitectura mostrada en la Fig.4. Tiene capas de neuronas conectadas recurrentemente con los estados descritos por variables continuas y las funciones de activación , el índice enumera las capas de la red y el índice enumera las neuronas individuales en esa capa. Las funciones de activación pueden depender de las actividades de todas las neuronas en la capa. Cada capa puede tener un número diferente de neuronas . Estas neuronas están conectadas recurrentemente con las neuronas en las capas anteriores y posteriores. Las matrices de pesos que conectan neuronas en capas se denotan por (el orden de los índices superiores para los pesos es el mismo que el orden de los índices inferiores, en el ejemplo anterior esto significa que el índice enumera neuronas en la capa , y el índice enumera neuronas en la capa ). Los pesos de avance y los pesos de retroalimentación son iguales. Las ecuaciones dinámicas para los estados de las neuronas se pueden escribir como [46]








| ( 14 ) |

con condiciones de contorno
| ( 15 ) |

La principal diferencia entre estas ecuaciones y las de las redes feedforward convencionales es la presencia del segundo término, que es responsable de la retroalimentación de las capas superiores. Estas señales de arriba hacia abajo ayudan a las neuronas de las capas inferiores a decidir su respuesta a los estímulos presentados. Siguiendo la receta general, es conveniente introducir una función lagrangiana para la -ésima capa oculta, que depende de las actividades de todas las neuronas de esa capa. [46] Las funciones de activación en esa capa se pueden definir como derivadas parciales de la función lagrangiana.

| ( 16 ) |

Con estas definiciones la función de energía (Lyapunov) viene dada por [46]
| ( 17 ) |
![{\displaystyle E=\suma \límites _{A=1}^{N_{\text{capa}}}{\Big [}\suma \límites _{i=1}^{N_{A}}x_{i}^{A}g_{i}^{A}-L^{A}{\Big ]}-\suma \límites _{A=1}^{N_{\text{capa}}-1}\suma \límites _{i=1}^{N_{A+1}}\suma \límites _{j=1}^{N_{A}}g_{i}^{A+1}\xi _{ij}^{(A+1,A)}g_{j}^{A}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/087774b10637a0e122dd10a4f8e5893df2aca372)
Si las funciones de Lagrange, o equivalentemente las funciones de activación, se eligen de tal manera que las hessianas de cada capa sean semidefinidas positivas y la energía total esté acotada desde abajo, se garantiza que este sistema convergerá a un estado atractor de punto fijo. La derivada temporal de esta función de energía está dada por [46]
| ( 18 ) |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Por lo tanto, la red jerárquica en capas es en realidad una red de atractores con una función de energía global. Esta red se describe mediante un conjunto jerárquico de pesos sinápticos que se pueden aprender para cada problema específico.
Véase también
- Memoria asociativa (desambiguación)
- Memoria autoasociativa
- Máquina de Boltzmann : similar a una red de Hopfield, pero que utiliza muestreo de Gibbs recocido en lugar de descenso de gradiente
- Modelo de sistemas dinámicos de la cognición
- Modelo de Ising
- Teoría hebbiana
Referencias
- ^ F. Rosenblatt, "Generalización perceptual sobre grupos de transformación", págs. 63-100 en Sistemas autoorganizados: Actas de una conferencia interdisciplinaria, 5 y 6 de mayo de 1959. Editado por Marshall C. Yovitz y Scott Cameron. Londres, Nueva York, [etc.], Pergamon Press, 1960. ix, 322 págs.
- ^ Rosenblatt, Frank (15 de marzo de 1961). DTIC AD0256582: PRINCIPIOS DE LA NEURODINÁMICA. PERCEPTRONES Y TEORÍA DE LOS MECANISMOS CEREBRALES. Centro de Información Técnica de Defensa.
- ^ WK Taylor, 1956. Simulación eléctrica de algunas actividades funcionales del sistema nervioso . Teoría de la información 3, EC Cherry (ed.), págs. 314-328. Londres: Butterworths.
- ^ Elogio: 1917 Karl Steinbuch 2005. , por Bernard Widrow, Reiner Hartenstein, Robert Hecht-Nielsen, IEEE Computational Intelligence Society. página 5. Agosto de 2005.
- ^ Steinbuch, K. (1 de enero de 1961). "Die Lernmatrix". Kybernetik (en alemán). 1 (1): 36–45. doi :10.1007/BF00293853. ISSN 1432-0770.
- ^ Steinbuch, Karl (1961). Automat und Mensch: über menschliche und maschinelle Intelligenz. Berlín: Springer. ISBN 978-3-642-53168-2.OL 27019478M .
- ^ Steinbuch, K.; Piske, UAW (diciembre de 1963). "Matrices de aprendizaje y sus aplicaciones". IEEE Transactions on Electronic Computers . EC-12 (6): 846–862. doi :10.1109/PGEC.1963.263588. ISSN 0367-7508.
- ^ Willshaw, DJ; Buneman, OP; Longuet-Higgins, HC (junio de 1969). "Memoria asociativa no holográfica". Nature . 222 (5197): 960–962. Código Bibliográfico :1969Natur.222..960W. doi :10.1038/222960a0. ISSN 0028-0836. PMID 5789326.
- ^ Kohonen, T. (abril de 1974). "Un principio de memoria asociativa adaptativa". IEEE Transactions on Computers . C-23 (4): 444–445. doi :10.1109/TC.1974.223960. ISSN 0018-9340.
- ^ Glauber, Roy J. (febrero de 1963). "Roy J. Glauber "Estadísticas dependientes del tiempo del modelo de Ising"". Journal of Mathematical Physics . 4 (2): 294–307. doi :10.1063/1.1703954 . Consultado el 21 de marzo de 2021 .
- ^ Nakano, Kaoru (1971). "Proceso de aprendizaje en un modelo de memoria asociativa". Reconocimiento de patrones y aprendizaje automático . pp. 172–186. doi :10.1007/978-1-4615-7566-5_15. ISBN 978-1-4615-7568-9.
- ^ Nakano, Kaoru (1972). "Asociatron: un modelo de memoria asociativa". IEEE Transactions on Systems, Man, and Cybernetics . SMC-2 (3): 380–388. doi :10.1109/TSMC.1972.4309133.
- ^ Amari, Shun-Ichi (1972). "Aprendizaje de patrones y secuencias de patrones mediante redes autoorganizadas de elementos umbral". IEEE Transactions . C (21): 1197–1206.
- ^ Little, WA (1974). "La existencia de estados persistentes en el cerebro". Ciencias biológicas matemáticas . 19 (1–2): 101–120. doi :10.1016/0025-5564(74)90031-5.
- ^ Carpenter, Gail A (1989-01-01). "Modelos de redes neuronales para el reconocimiento de patrones y la memoria asociativa". Redes neuronales . 2 (4): 243–257. doi :10.1016/0893-6080(89)90035-X. ISSN 0893-6080.
- ^ Cowan, Jack D. (enero de 1990). "Discusión: McCulloch-Pitts y redes neuronales relacionadas de 1943 a 1989". Boletín de biología matemática . 52 (1–2): 73–97. doi :10.1007/BF02459569. ISSN 0092-8240.
- ^ Sherrington, David; Kirkpatrick, Scott (29 de diciembre de 1975). "Modelo resoluble de un vidrio de espín". Physical Review Letters . 35 (26): 1792–1796. Código Bibliográfico :1975PhRvL..35.1792S. doi :10.1103/PhysRevLett.35.1792. ISSN 0031-9007.
- ^ abcdefg Hopfield, JJ (1982). "Redes neuronales y sistemas físicos con capacidades computacionales colectivas emergentes". Actas de la Academia Nacional de Ciencias . 79 (8): 2554–2558. Bibcode :1982PNAS...79.2554H. doi : 10.1073/pnas.79.8.2554 . PMC 346238 . PMID 6953413.
- ^ abcdefg Hopfield, JJ (1984). "Las neuronas con respuesta graduada tienen propiedades computacionales colectivas como las de las neuronas de dos estados". Actas de la Academia Nacional de Ciencias . 81 (10): 3088–3092. Bibcode :1984PNAS...81.3088H. doi : 10.1073/pnas.81.10.3088 . PMC 345226 . PMID 6587342.
- ^ Engel, A.; Broeck, C. van den (2001). Mecánica estadística del aprendizaje . Cambridge, Reino Unido; Nueva York, NY: Cambridge University Press. ISBN 978-0-521-77307-2.
- ^ Seung, HS; Sompolinsky, H.; Tishby, N. (1 de abril de 1992). "Mecánica estadística del aprendizaje a partir de ejemplos". Physical Review A . 45 (8): 6056–6091. Bibcode :1992PhRvA..45.6056S. doi :10.1103/PhysRevA.45.6056. PMID 9907706.
- ^ abcdefghij Krotov, Dmitry; Hopfield, John (2016). "Memoria asociativa densa para el reconocimiento de patrones". Sistemas de procesamiento de información neuronal . 29 : 1172–1180. arXiv : 1606.01164 .
- ^ abcd Mete, Demircigil; et al. (2017). "Sobre un modelo de memoria asociativa con gran capacidad de almacenamiento". Journal of Statistical Physics . 168 (2): 288–299. arXiv : 1702.01929 . Bibcode :2017JSP...168..288D. doi :10.1007/s10955-017-1806-y. S2CID 119317128.
- ^ abcde Ramsauer, Hubert; et al. (2021). "Las redes de Hopfield son todo lo que necesitas". Conferencia internacional sobre representaciones de aprendizaje . arXiv : 2008.02217 .
- ^ abcdefghijk Krotov, Dmitry; Hopfield, John (2021). "Gran problema de memoria asociativa en neurobiología y aprendizaje automático". Conferencia internacional sobre representaciones de aprendizaje . arXiv : 2008.06996 .
- ^ Hopfield, JJ (1982). "Redes neuronales y sistemas físicos con capacidades computacionales colectivas emergentes". Actas de la Academia Nacional de Ciencias . 79 (8): 2554–2558. Bibcode :1982PNAS...79.2554H. doi : 10.1073/pnas.79.8.2554 . PMC 346238 . PMID 6953413.
- ^ MacKay, David JC (2003). "42. Redes de Hopfield". Teoría de la información, inferencia y algoritmos de aprendizaje . Cambridge University Press . pág. 508. ISBN. 978-0521642989
Esta prueba de convergencia depende fundamentalmente del hecho de que las conexiones de la red de Hopfield sean
simétricas.
También depende de que las actualizaciones se realicen de forma asincrónica.
- ^ abc Bruck, J. (octubre de 1990). "Sobre las propiedades de convergencia del modelo de Hopfield". Proc. IEEE . 78 (10): 1579–85. doi :10.1109/5.58341.
- ^ abcde Uykan, Z. (septiembre de 2020). "Sobre el principio de funcionamiento de las redes neuronales de Hopfield y su equivalencia con GADIA en optimización". IEEE Transactions on Neural Networks and Learning Systems . 31 (9): 3294–3304. doi :10.1109/TNNLS.2019.2940920. PMID 31603804. S2CID 204331533.
- ^ Uykan, Z. (marzo de 2021). "Minimización/maximización de cortes de sombra y redes neuronales complejas de Hopfield". IEEE Transactions on Neural Networks and Learning Systems . 32 (3): 1096–1109. doi : 10.1109/TNNLS.2020.2980237 . PMID 32310787. S2CID 216047831.
- ^ Hopfield, JJ; Tank, DW (1985). "Cálculo neuronal de decisiones en problemas de optimización". Cibernética biológica . 52 (3): 141–6. doi :10.1007/BF00339943. PMID 4027280. S2CID 36483354.
- ^ Bruck, Jehoshua; Goodman, Joseph W (1 de junio de 1990). "Sobre el poder de las redes neuronales para resolver problemas difíciles". Journal of Complexity . 6 (2): 129–135. doi :10.1016/0885-064X(90)90001-T. ISSN 0885-064X.
- ^ ab Storkey, AJ; Valabregue, R. (1999). "Las cuencas de atracción de una nueva regla de aprendizaje de Hopfield". Redes neuronales . 12 (6): 869–876. CiteSeerX 10.1.1.19.4681 . doi :10.1016/S0893-6080(99)00038-6. PMID 12662662.
- ^ Hebb 1949
- ^ Storkey, Amos (1997). "Aumento de la capacidad de una red Hopfield sin sacrificar la funcionalidad". Redes neuronales artificiales – ICANN'97 . Apuntes de clase en informática. Vol. 1327. Springer. págs. 451–6. CiteSeerX 10.1.1.33.103 . doi :10.1007/BFb0020196. ISBN. 978-3-540-69620-9.
- ^ de Hertz 1991
- ^ Bruck, J.; Roychowdhury, VP (1990). "Sobre el número de recuerdos espurios en el modelo de Hopfield (red neuronal)". IEEE Transactions on Information Theory . 36 (2): 393–397. doi :10.1109/18.52486.
- ^ Liou, C.-Y.; Lin, S.-L. (2006). "Carga de memoria finita en neuronas peludas" (PDF) . Natural Computing . 5 (1): 15–42. doi :10.1007/s11047-004-5490-x. S2CID 35025761.
- ^ Liou, C.-Y.; Yuan, S.-K. (1999). "Memoria asociativa tolerante a errores". Cibernética biológica . 81 (4): 331–342. doi :10.1007/s004220050566. PMID 10541936. S2CID 6168346.
- ^ Yuan, S.-K. (junio de 1997). Expansión de las cuencas de atracción de la memoria asociativa (tesis de maestría). Universidad Nacional de Taiwán. 991010725609704786.
- ^ ABOUDIB, Ala; GRIPON, Vincent; JIANG, Xiaoran (2014). "Un estudio de algoritmos de recuperación de mensajes dispersos en redes de grupos neuronales". COGNITIVE 2014: La 6.ª Conferencia Internacional sobre Tecnologías y Aplicaciones Cognitivas Avanzadas . págs. 140–6. arXiv : 1308.4506 . Código Bibliográfico :2013arXiv1308.4506A.
- ^ Amit, DJ (1992). Modelado de la función cerebral: el mundo de las redes neuronales atractoras. Cambridge University Press. ISBN 978-0-521-42124-9.
- ^ Rolls, Edmund T. (2016). Corteza cerebral: principios de funcionamiento. Oxford University Press. ISBN 978-0-19-878485-2.
- ^ ab Horn, D; Usher, M (1988). "Capacidades de modelos de memoria multiconectados". J. Phys. Francia . 49 (3): 389–395. doi :10.1051/jphys:01988004903038900.
- ^ abc Burns, Thomas; Fukai, Tomoki (2023). "Redes de Hopfield simples". Conferencia internacional sobre representaciones del aprendizaje . 11 . arXiv : 2305.05179 .
- ^ abcdefghi Krotov, Dmitry (2021). "Memoria asociativa jerárquica". arXiv : 2107.06446 [cs.NE].
- Hebb, DO (2005) [1949]. La organización del comportamiento: una teoría neuropsicológica. Psychology Press. ISBN 978-1-135-63190-1.
- Hertz, John A. (2018) [1991]. Introducción a la teoría de la computación neuronal. CRC Press. ISBN 978-0-429-96821-1.
- McCulloch, WS; Pitts, WH (1943). "Un cálculo lógico de las ideas inmanentes en la actividad nerviosa". Boletín de biofísica matemática . 5 (4): 115–133. doi :10.1007/BF02478259.
- Polyn, SM; Kahana, MJ (2008). "Búsqueda de memoria y representación neuronal del contexto". Tendencias en Ciencias Cognitivas . 12 (1): 24–30. doi :10.1016/j.tics.2007.10.010. PMC 2839453 . PMID 18069046.
- Rizzuto, DS; Kahana, MJ (2001). "Un modelo de red neuronal autoasociativa de aprendizaje por pares asociados". Computación neuronal . 13 (9): 2075–2092. CiteSeerX 10.1.1.45.7929 . doi :10.1162/089976601750399317. PMID 11516358. S2CID 7675117.
- Kruse, Rudolf; Borgelt, cristiano; Klawonn, Frank; Moewes, cristiano; Steinbrecher, Matías; Celebrado, Pascal (2013). Inteligencia computacional: una introducción metodológica. Saltador. ISBN 978-1-4471-5013-8.
Enlaces externos
- Rojas, Raul (12 de julio de 1996). "13. El modelo de Hopfield" (PDF) . Redes neuronales: una introducción sistemática. Springer. ISBN 978-3-540-60505-8.
- Red Hopfield Javascript
- El problema del viajante Archivado el 30 de mayo de 2015 en Wayback Machine – Applet de JAVA de red neuronal de Hopfield
- Hopfield, John (2007). "Red de Hopfield". Scholarpedia . 2 (5): 1977. Bibcode :2007SchpJ...2.1977H. doi : 10.4249/scholarpedia.1977 .
- "No te olvides de los recuerdos asociativos". The Gradient . 7 de noviembre de 2020 . Consultado el 27 de septiembre de 2024 .
- Fletcher, Tristan. "Aprendizaje de redes de Hopfield mediante variables latentes deterministas" (PDF) (Tutorial). Archivado desde el original (PDF) el 5 de octubre de 2011.
