Modelo cliente-servidor
Este artículo (algunas secciones) necesita citas adicionales para su verificación . ( marzo de 2024 ) |
{kind=link}
{kind=link}
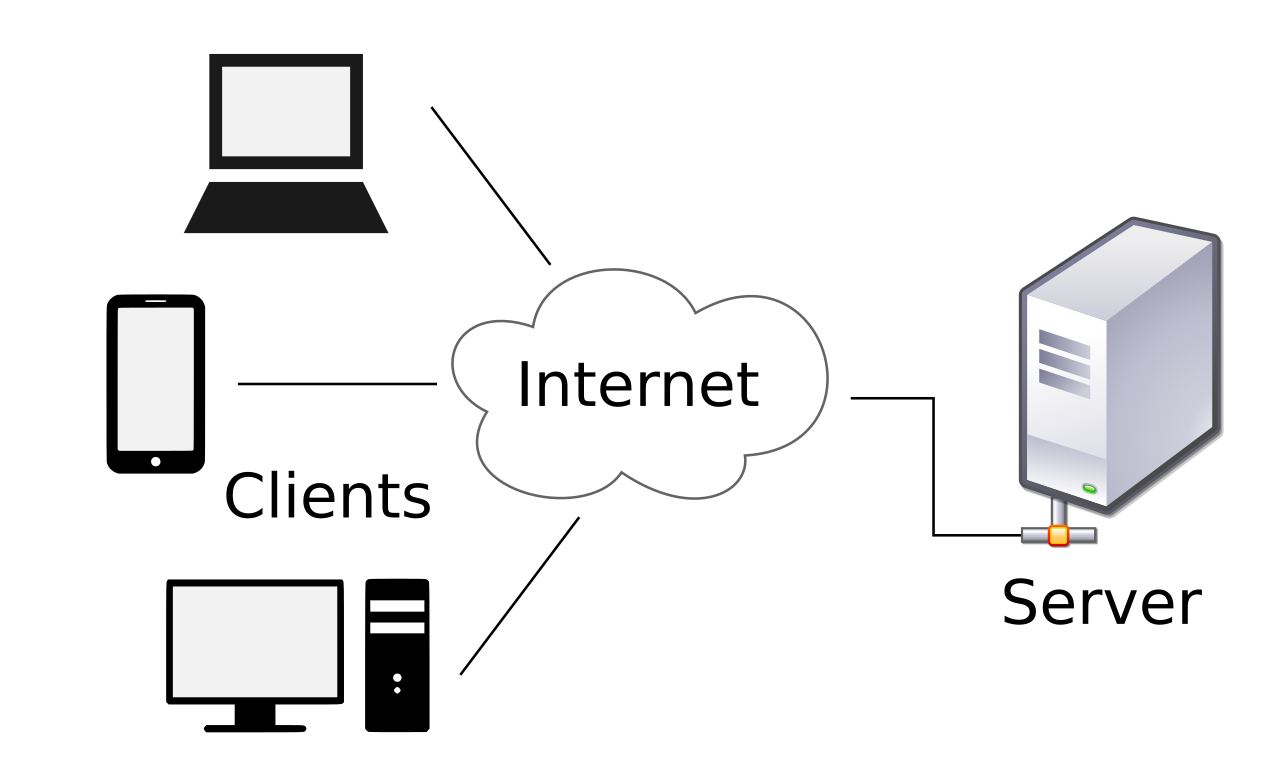
El modelo cliente-servidor es una estructura de aplicación distribuida que divide las tareas o cargas de trabajo entre los proveedores de un recurso o servicio, llamados servidores , y los solicitantes de servicios, llamados clientes . [1] A menudo, los clientes y los servidores se comunican a través de una red informática en hardware separado, pero tanto el cliente como el servidor pueden residir en el mismo sistema. Un host servidor ejecuta uno o más programas de servidor, que comparten sus recursos con los clientes. Un cliente normalmente no comparte ninguno de sus recursos, pero solicita contenido o servicio de un servidor. Los clientes, por lo tanto, inician sesiones de comunicación con los servidores, que esperan las solicitudes entrantes. Ejemplos de aplicaciones informáticas que utilizan el modelo cliente-servidor son el correo electrónico , la impresión en red y la World Wide Web .
Rol de cliente y servidor
El componente servidor proporciona una función o servicio a uno o varios clientes, que inician solicitudes de dichos servicios. Los servidores se clasifican según los servicios que proporcionan. Por ejemplo, un servidor web sirve páginas web y un servidor de archivos sirve archivos de computadora . Un recurso compartido puede ser cualquiera de los componentes electrónicos y software de la computadora servidor, desde programas y datos hasta procesadores y dispositivos de almacenamiento . El uso compartido de recursos de un servidor constituye un servicio .
El hecho de que una computadora sea un cliente, un servidor o ambos depende de la naturaleza de la aplicación que requiere las funciones de servicio. Por ejemplo, una sola computadora puede ejecutar un servidor web y un software de servidor de archivos al mismo tiempo para proporcionar diferentes datos a clientes que realizan diferentes tipos de solicitudes. El software del cliente también puede comunicarse con el software del servidor dentro de la misma computadora. [2] La comunicación entre servidores, como la sincronización de datos, a veces se denomina comunicación entre servidores o comunicación de servidor a servidor .
Comunicación entre cliente y servidor
En general, un servicio es una abstracción de los recursos informáticos y el cliente no tiene que preocuparse por el rendimiento del servidor al cumplir la solicitud y entregar la respuesta. El cliente solo tiene que comprender la respuesta en función del protocolo de aplicación pertinente , es decir, el contenido y el formato de los datos para el servicio solicitado.
Los clientes y servidores intercambian mensajes en un patrón de mensajería de solicitud-respuesta . El cliente envía una solicitud y el servidor devuelve una respuesta. Este intercambio de mensajes es un ejemplo de comunicación entre procesos . Para comunicarse, las computadoras deben tener un lenguaje común y deben seguir reglas para que tanto el cliente como el servidor sepan qué esperar. El lenguaje y las reglas de comunicación se definen en un protocolo de comunicaciones . Todos los protocolos operan en la capa de aplicación . El protocolo de la capa de aplicación define los patrones básicos del diálogo. Para formalizar aún más el intercambio de datos, el servidor puede implementar una interfaz de programación de aplicaciones (API). [3] La API es una capa de abstracción para acceder a un servicio. Al restringir la comunicación a un formato de contenido específico , facilita el análisis . Al abstraer el acceso, facilita el intercambio de datos entre plataformas. [4]
Un servidor puede recibir solicitudes de muchos clientes distintos en un corto período de tiempo. Una computadora solo puede realizar una cantidad limitada de tareas en cualquier momento y depende de un sistema de programación para priorizar las solicitudes entrantes de los clientes y satisfacerlas. Para evitar el abuso y maximizar la disponibilidad , el software del servidor puede limitar la disponibilidad para los clientes. Los ataques de denegación de servicio están diseñados para explotar la obligación de un servidor de procesar solicitudes sobrecargándolo con tasas de solicitudes excesivas. Se debe aplicar cifrado si se va a comunicar información confidencial entre el cliente y el servidor.
Ejemplo
Cuando un cliente bancario accede a los servicios bancarios en línea con un navegador web (el cliente), el cliente inicia una solicitud al servidor web del banco. Las credenciales de inicio de sesión del cliente pueden almacenarse en una base de datos y el servidor web accede al servidor de base de datos como cliente. Un servidor de aplicaciones interpreta los datos devueltos aplicando la lógica empresarial del banco y proporciona el resultado al servidor web. Finalmente, el servidor web devuelve el resultado al navegador web del cliente para su visualización.
En cada paso de esta secuencia de intercambios de mensajes entre cliente y servidor, una computadora procesa una solicitud y devuelve datos. Este es el patrón de mensajería de solicitud-respuesta. Cuando se satisfacen todas las solicitudes, la secuencia está completa y el navegador web presenta los datos al cliente.
Este ejemplo ilustra un patrón de diseño aplicable al modelo cliente-servidor: separación de preocupaciones .
Del lado del servidor
 | Esta sección necesita citas adicionales para su verificación . ( diciembre de 2016 ) |
El lado del servidor se refiere a los programas y operaciones que se ejecutan en el servidor . Esto contrasta con los programas y operaciones del lado del cliente que se ejecutan en el cliente . [5] (Ver más abajo)
Conceptos generales
El "software del lado del servidor" se refiere a una aplicación informática , como un servidor web , que se ejecuta en un hardware de servidor remoto , al que se puede acceder desde la computadora local , el teléfono inteligente u otro dispositivo de un usuario . Las operaciones se pueden realizar en el lado del servidor porque requieren acceso a información o funcionalidad que no está disponible en el cliente , o porque realizar dichas operaciones en el lado del cliente sería lento, poco confiable o inseguro .
Los programas cliente y servidor pueden ser programas de uso común, como servidores web y navegadores web gratuitos o comerciales , que se comunican entre sí mediante protocolos estandarizados . O bien, los programadores pueden escribir su propio servidor, cliente y protocolo de comunicación que solo se pueden utilizar entre sí.
Las operaciones del lado del servidor incluyen tanto las que se llevan a cabo en respuesta a solicitudes del cliente como las operaciones no orientadas al cliente, como las tareas de mantenimiento. [6] [7]
Seguridad informática
En un contexto de seguridad informática , las vulnerabilidades o ataques del lado del servidor se refieren a aquellos que ocurren en un sistema informático servidor, en lugar de en el lado del cliente, o entre ambos . Por ejemplo, un atacante podría explotar una vulnerabilidad de inyección SQL en una aplicación web para cambiar de forma maliciosa u obtener acceso no autorizado a los datos de la base de datos del servidor . Alternativamente, un atacante podría entrar en un sistema servidor utilizando vulnerabilidades en el sistema operativo subyacente y luego poder acceder a la base de datos y otros archivos de la misma manera que los administradores autorizados del servidor. [8] [9] [10]
Ejemplos
En el caso de proyectos de computación distribuida como SETI@home y Great Internet Mersenne Prime Search , mientras que la mayor parte de las operaciones ocurren en el lado del cliente, los servidores son responsables de coordinar a los clientes, enviarles datos para analizar, recibir y almacenar resultados, proporcionar funcionalidad de informes a los administradores del proyecto, etc. En el caso de una aplicación de usuario dependiente de Internet como Google Earth , mientras que la consulta y visualización de datos de mapas se realiza en el lado del cliente, el servidor es responsable del almacenamiento permanente de los datos de mapas, resolver las consultas de los usuarios en datos de mapas para ser devueltos al cliente, etc.
En el contexto de la World Wide Web , los lenguajes de computadora del lado del servidor que se encuentran comúnmente incluyen: [5]
Sin embargo, las aplicaciones y servicios web se pueden implementar en casi cualquier lenguaje, siempre que puedan devolver datos a navegadores web basados en estándares (posiblemente a través de programas intermediarios) en formatos que puedan utilizar.
Lado del cliente
| Esta sección necesita citas adicionales para su verificación . ( diciembre de 2016 ) |
El lado del cliente se refiere a las operaciones que realiza el cliente en una red informática .
Conceptos generales
Por lo general, un cliente es una aplicación informática , como un navegador web , que se ejecuta en la computadora local , el teléfono inteligente u otro dispositivo de un usuario y se conecta a un servidor según sea necesario. Las operaciones se pueden realizar del lado del cliente porque requieren acceso a información o funcionalidad que está disponible en el cliente pero no en el servidor, porque el usuario necesita observar las operaciones o proporcionar información, o porque el servidor carece de la capacidad de procesamiento para realizar las operaciones de manera oportuna para todos los clientes a los que sirve. Además, si el cliente puede realizar las operaciones sin enviar datos a través de la red, pueden llevar menos tiempo, utilizar menos ancho de banda y generar un menor riesgo de seguridad .
Cuando el servidor sirve datos de una manera comúnmente utilizada, por ejemplo, según protocolos estándar como HTTP o FTP , los usuarios pueden elegir entre varios programas cliente (por ejemplo, la mayoría de los navegadores web modernos pueden solicitar y recibir datos utilizando tanto HTTP como FTP). En el caso de aplicaciones más especializadas, los programadores pueden escribir su propio servidor, cliente y protocolo de comunicaciones que solo se pueden utilizar entre sí.
Los programas que se ejecutan en la computadora local de un usuario sin enviar ni recibir datos a través de una red no se consideran clientes y, por lo tanto, las operaciones de dichos programas no se denominarían operaciones del lado del cliente.
Seguridad informática
En un contexto de seguridad informática , las vulnerabilidades o ataques del lado del cliente se refieren a aquellos que ocurren en el sistema informático del cliente/usuario, en lugar de en el lado del servidor , o entre ambos . Por ejemplo, si un servidor contuviera un archivo o mensaje cifrado que solo pudiera descifrarse utilizando una clave alojada en el sistema informático del usuario, un ataque del lado del cliente normalmente sería la única oportunidad que tendría un atacante de obtener acceso al contenido descifrado. Por ejemplo, el atacante podría hacer que se instale malware en el sistema del cliente, lo que le permitiría ver la pantalla del usuario, registrar las pulsaciones de teclas del usuario y robar copias de las claves de cifrado del usuario, etc. Alternativamente, un atacante podría emplear vulnerabilidades de secuencias de comandos entre sitios para ejecutar código malicioso en el sistema del cliente sin necesidad de instalar ningún malware residente de forma permanente. [8] [9] [10]
Ejemplos
Los proyectos de computación distribuida como SETI@home y Great Internet Mersenne Prime Search, así como las aplicaciones que dependen de Internet como Google Earth , se basan principalmente en operaciones del lado del cliente. Inician una conexión con el servidor (ya sea en respuesta a una consulta del usuario, como en Google Earth, o de manera automática, como en SETI@home) y solicitan algunos datos. El servidor selecciona un conjunto de datos (una operación del lado del servidor ) y lo envía de vuelta al cliente. A continuación, el cliente analiza los datos (una operación del lado del cliente) y, cuando el análisis está completo, se los muestra al usuario (como en Google Earth) y/o transmite los resultados de los cálculos de vuelta al servidor (como en SETI@home).
En el contexto de la World Wide Web , los lenguajes informáticos más comunes que se evalúan o ejecutan en el lado del cliente incluyen: [5]
Historia temprana
Una forma temprana de arquitectura cliente-servidor es la entrada de trabajo remota , que data al menos de OS/360 (anunciado en 1964), donde la solicitud era ejecutar un trabajo y la respuesta era la salida.
Al formular el modelo cliente-servidor en los años 1960 y 1970, los científicos informáticos que construyeron ARPANET (en el Stanford Research Institute ) utilizaron los términos host-servidor (o host servidor ) y host-usuario (o host-usuario ), y estos aparecen en los primeros documentos RFC 5 [11] y RFC 4. [12] Este uso continuó en Xerox PARC a mediados de los años 1970.
Un contexto en el que los investigadores utilizaron estos términos fue en el diseño de un lenguaje de programación de redes informáticas llamado Decode-Encode Language (DEL). [11] El propósito de este lenguaje era aceptar comandos de una computadora (el host del usuario), que devolvería informes de estado al usuario a medida que codificaba los comandos en paquetes de red. Otra computadora con capacidad DEL, el host del servidor, recibía los paquetes, los decodificaba y devolvía datos formateados al host del usuario. Un programa DEL en el host del usuario recibía los resultados para presentarlos al usuario. Esta es una transacción cliente-servidor. El desarrollo de DEL estaba recién comenzando en 1969, el año en que el Departamento de Defensa de los Estados Unidos estableció ARPANET (predecesor de Internet ).
Cliente-host y servidor-host
Cliente-host y servidor-host tienen significados sutilmente diferentes a cliente y servidor . Un host es cualquier computadora conectada a una red. Mientras que las palabras servidor y cliente pueden referirse a una computadora o a un programa de computadora, servidor-host y cliente-host siempre se refieren a computadoras. El host es una computadora versátil y multifunción; los clientes y servidores son simplemente programas que se ejecutan en un host. En el modelo cliente-servidor, es más probable que un servidor se dedique a la tarea de servir.
Un uso temprano de la palabra cliente aparece en "Separating Data from Function in a Distributed File System", un artículo de 1978 de los científicos informáticos de Xerox PARC Howard Sturgis, James Mitchell y Jay Israel. Los autores tienen cuidado de definir el término para los lectores y explican que lo utilizan para distinguir entre el usuario y el nodo de red del usuario (el cliente). [13] En 1992, la palabra servidor había entrado en el lenguaje general. [14] [15]
Computación centralizada
El modelo cliente-servidor no dicta que los hosts servidores deben tener más recursos que los hosts cliente. Más bien, permite que cualquier computadora de propósito general extienda sus capacidades utilizando los recursos compartidos de otros hosts. La computación centralizada , sin embargo, asigna específicamente una gran cantidad de recursos a una pequeña cantidad de computadoras. Cuanto más computación se descarga de los hosts cliente a las computadoras centrales, más simples pueden ser los hosts cliente. [16] Depende en gran medida de los recursos de red (servidores e infraestructura) para la computación y el almacenamiento. Un nodo sin disco carga incluso su sistema operativo desde la red, y una terminal de computadora no tiene sistema operativo en absoluto; es solo una interfaz de entrada/salida al servidor. Por el contrario, un cliente rico , como una computadora personal , tiene muchos recursos y no depende de un servidor para funciones esenciales.
A medida que los microordenadores disminuyeron de precio y aumentaron de potencia desde la década de 1980 hasta finales de la década de 1990, muchas organizaciones hicieron la transición de la computación desde servidores centralizados, como mainframes y miniordenadores , a clientes enriquecidos. [17] Esto permitió un dominio mayor y más individualizado sobre los recursos informáticos, pero complicó la gestión de la tecnología de la información . [16] [18] [19] Durante la década de 2000, las aplicaciones web maduraron lo suficiente como para rivalizar con el software de aplicación desarrollado para una microarquitectura específica . Esta maduración, el almacenamiento masivo más asequible y el advenimiento de la arquitectura orientada a servicios fueron algunos de los factores que dieron lugar a la tendencia de la computación en la nube de la década de 2010. [20] [ verificación fallida ]
Comparación con la arquitectura peer-to-peer
Además del modelo cliente-servidor, las aplicaciones de computación distribuida a menudo utilizan la arquitectura de aplicaciones peer-to-peer (P2P).
En el modelo cliente-servidor, el servidor suele estar diseñado para funcionar como un sistema centralizado que presta servicio a muchos clientes. Los requisitos de potencia informática, memoria y almacenamiento de un servidor deben ajustarse adecuadamente a la carga de trabajo prevista. A menudo se emplean sistemas de equilibrio de carga y conmutación por error para ampliar el servidor más allá de una única máquina física. [21] [22]
El equilibrio de carga se define como la distribución metódica y eficiente del tráfico de la red o de las aplicaciones entre varios servidores de una granja de servidores. Cada equilibrador de carga se ubica entre los dispositivos cliente y los servidores back-end, y recibe y distribuye las solicitudes entrantes a cualquier servidor disponible capaz de responderlas.
En una red peer-to-peer , dos o más computadoras ( peers ) agrupan sus recursos y se comunican en un sistema descentralizado . Los peers son nodos coiguales o equipotentes en una red no jerárquica. A diferencia de los clientes en una red cliente-servidor o cliente-cola-cliente , los peers se comunican entre sí directamente. [ cita requerida ] En las redes peer-to-peer, un algoritmo en el protocolo de comunicaciones peer-to-peer equilibra la carga , e incluso los peers con recursos modestos pueden ayudar a compartir la carga. [ cita requerida ] Si un nodo deja de estar disponible, sus recursos compartidos permanecen disponibles mientras otros peers los ofrezcan. Idealmente, un peer no necesita lograr alta disponibilidad porque otros peers redundantes compensan cualquier tiempo de inactividad de los recursos ; a medida que cambia la disponibilidad y la capacidad de carga de los peers, el protocolo redirecciona las solicitudes.
Tanto el cliente-servidor como el maestro-esclavo se consideran subcategorías de los sistemas distribuidos peer to peer. [23]
Véase también
- Seguridad de puntos finales
- Extremos delantero y trasero
- Programación modular
- Patrón de observador
- Patrón de publicación y suscripción
- Tecnología de tracción
- Tecnología Push
- Llamada a procedimiento remoto
- Número de cambio de servidor
- Arquitectura de red de sistemas , una arquitectura de red propia de IBM
- Cliente ligero
- Computación en red configurable , una arquitectura cliente-servidor patentada por JD Edwards
Notas
- ^ "Arquitectura de aplicaciones distribuidas" (PDF) . Sun Microsystem. Archivado desde el original (PDF) el 6 de abril de 2011 . Consultado el 16 de junio de 2009 .
- ^ El sistema X Window es un ejemplo.
- ^ Benatallah, B.; Casati, F.; Toumani, F. (2004). "Modelado de conversaciones de servicios web: una piedra angular para la automatización del comercio electrónico". IEEE Internet Computing . 8 : 46–54. doi :10.1109/MIC.2004.1260703. S2CID 8121624.
- ^ Dustdar, S.; Schreiner, W. (2005). "Una encuesta sobre la composición de los servicios web" (PDF) . Revista internacional de servicios web y grid . 1 : 1. CiteSeerX 10.1.1.139.4827 . doi :10.1504/IJWGS.2005.007545.
- ^ abc "¿Cuáles son las diferencias entre la programación del lado del servidor y la del lado del cliente?". softwareengineering.stackexchange.com . Consultado el 13 de diciembre de 2016 .
- ^ "Introducción al lado del servidor - Aprenda desarrollo web | MDN". developer.mozilla.org . 2023-11-05 . Consultado el 2023-11-13 .
- ^ "Programación de sitios web del lado del servidor - Aprenda desarrollo web | MDN". developer.mozilla.org . 2023-06-30 . Consultado el 2023-11-13 .
- ^ ab Lehtinen, Rick; Russell, Deborah; Gangemi, GT (2006). Fundamentos de seguridad informática (2.ª ed.). O'Reilly Media . ISBN 9780596006693. Recuperado el 7 de julio de 2017 .
- ^ ab JS (15 de octubre de 2015). "Semana 4: ¿Existe una diferencia entre el lado del cliente y el lado del servidor?". n3tweb.wordpress.com . Consultado el 7 de julio de 2017 .
- ^ ab Espinosa, Christian (23 de abril de 2016). "Descifrando el hack" (PDF) . alpinesecurity.com . Consultado el 7 de julio de 2017 .[ enlace muerto permanente ]
- ^ ab Rulifson, Jeff (junio de 1969). DEL. IETF . doi : 10.17487/RFC0005 . RFC 5 . Consultado el 30 de noviembre de 2013 .
- ^ Shapiro, Elmer B. (marzo de 1969). Network Timetable. IETF . doi : 10.17487/RFC0004 . RFC 4. Consultado el 30 de noviembre de 2013 .
- ^ Sturgis, Howard E.; Mitchell, James George; Israel, Jay E. (1978). "Separación de datos y funciones en un sistema de archivos distribuido". Xerox PARC .
- ^ Harper, Douglas. "servidor". Diccionario Etimológico Online . Consultado el 30 de noviembre de 2013 .
- ^ "Separación de datos y funciones en un sistema de archivos distribuido". GetInfo . Biblioteca Nacional Alemana de Ciencia y Tecnología . Archivado desde el original el 2 de diciembre de 2013 . Consultado el 29 de noviembre de 2013 .
- ^ ab Nieh, Jason; Yang, S. Jae; Novik, Naomi (2000). "Una comparación de arquitecturas informáticas de cliente ligero". Academic Commons . doi :10.7916/D8Z329VF . Consultado el 28 de noviembre de 2018 .
- ^ d'Amore, MJ; Oberst, DJ (1983). "Microcomputadoras y mainframes". Actas de la 11.ª conferencia anual ACM SIGUCCS sobre servicios de usuario - SIGUCCS '83 . p. 7. doi :10.1145/800041.801417. ISBN 978-0897911160. Número de identificación del sujeto 14248076.
- ^ Tolia, Niraj; Andersen, David G.; Satyanarayanan, M. (marzo de 2006). "Cuantificación de la experiencia de usuario interactiva en clientes ligeros" (PDF) . Computer . 39 (3). IEEE Computer Society : 46–52. doi :10.1109/mc.2006.101. S2CID 8399655.
- ^ Otey, Michael (22 de marzo de 2011). "¿Es la nube realmente solo el regreso de la informática mainframe?". SQL Server Pro . Penton Media . Archivado desde el original el 3 de diciembre de 2013. Consultado el 1 de diciembre de 2013 .
- ^ Barros, AP; Dumas, M. (2006). "El auge de los ecosistemas de servicios web". IT Professional . 8 (5): 31. doi :10.1109/MITP.2006.123. S2CID 206469224.
- ^ Cardellini, V.; Colajanni, M.; Yu, PS (1999). "Balanceo de carga dinámico en sistemas de servidores web". IEEE Internet Computing . 3 (3). Instituto de Ingenieros Eléctricos y Electrónicos (IEEE): 28–39. doi :10.1109/4236.769420. ISSN 1089-7801.
- ^ "¿Qué es el balanceo de carga? Cómo funcionan los balanceadores de carga". NGINX . 1 de junio de 2014 . Consultado el 21 de enero de 2020 .
- ^ Varma, Vasudeva (2009). "1: Introducción a la arquitectura de software". Arquitectura de software: un enfoque basado en casos . Delhi: Pearson Education India. pág. 29. ISBN 9788131707494. Recuperado el 4 de julio de 2017.
Sistemas distribuidos punto a punto [...] Este es un estilo genérico cuyos estilos más populares son el estilo cliente-servidor y el estilo maestro-esclavo.
