Normalización de bases de datos
 | Este artículo necesita la atención de un experto en bases de datos . Consulte la página de discusión para obtener más detalles. ( Marzo de 2018 ) |
La normalización de bases de datos es el proceso de estructurar una base de datos relacional de acuerdo con una serie de las denominadas formas normales con el fin de reducir la redundancia de datos y mejorar su integridad . Fue propuesta por primera vez por el informático británico Edgar F. Codd como parte de su modelo relacional .
La normalización implica organizar las columnas (atributos) y las tablas (relaciones) de una base de datos para garantizar que sus dependencias se cumplan correctamente mediante las restricciones de integridad de la base de datos. Se logra mediante la aplicación de algunas reglas formales, ya sea mediante un proceso de síntesis (creación de un nuevo diseño de base de datos) o de descomposición (mejora de un diseño de base de datos existente).
Objetivos
Un objetivo básico de la primera forma normal definida por Codd en 1970 era permitir que los datos se consultaran y manipularan utilizando un "sublenguaje de datos universal" basado en la lógica de primer orden . [1] Un ejemplo de dicho lenguaje es SQL , aunque Codd lo consideraba seriamente defectuoso. [2]
Los objetivos de la normalización más allá de 1NF (primera forma normal) fueron establecidos por Codd como:
- Para liberar la colección de relaciones de dependencias de inserción, actualización y eliminación no deseadas.
- Reducir la necesidad de reestructurar la colección de relaciones, a medida que se introducen nuevos tipos de datos, y así aumentar la vida útil de los programas de aplicación.
- Para hacer que el modelo relacional sea más informativo para los usuarios.
- Hacer que la recopilación de relaciones sea neutral respecto de las estadísticas de consulta, donde estas estadísticas pueden cambiar con el paso del tiempo.
— EF Codd, "Mayor normalización del modelo relacional de la base de datos" [3]
{kind=link}
{kind=link}

{kind=link}

Cuando se intenta modificar (actualizar, insertar o eliminar) una relación, pueden surgir los siguientes efectos secundarios indeseables en relaciones que no se han normalizado lo suficiente:
- Anomalía de inserción
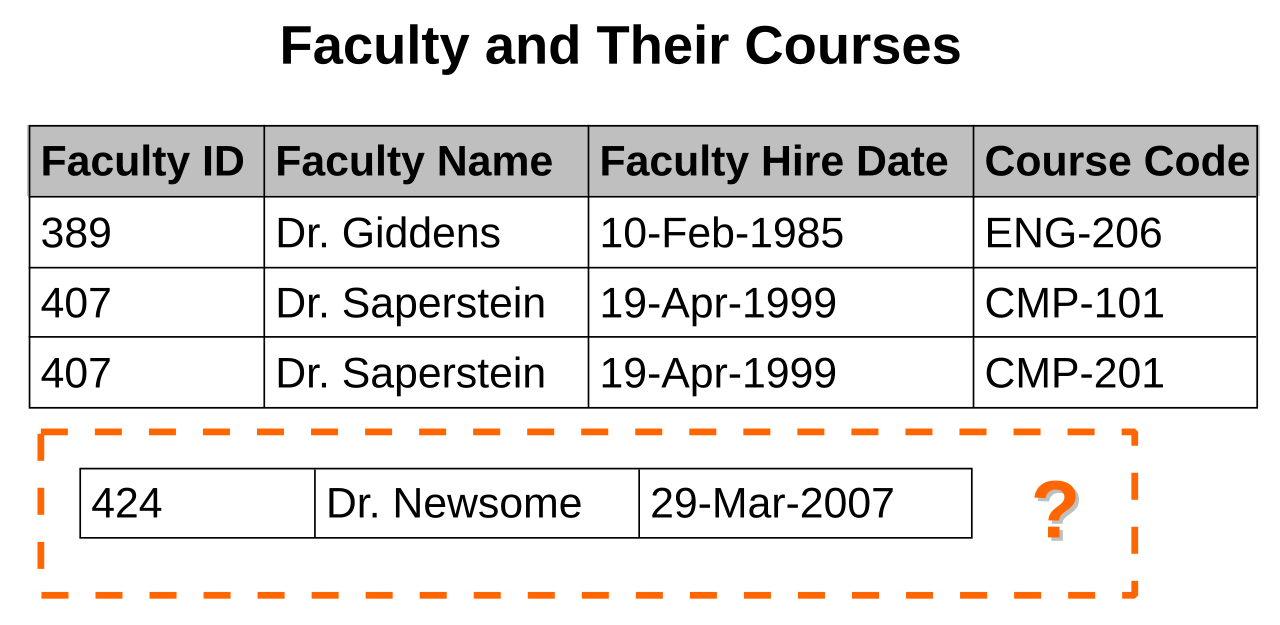
- Existen circunstancias en las que no se pueden registrar ciertos hechos. Por ejemplo, cada registro de una relación "Profesores y sus cursos" puede contener un ID de profesor, un nombre de profesor, una fecha de contratación de profesor y un código de curso. Por lo tanto, se pueden registrar los detalles de cualquier miembro del profesor que imparta al menos un curso, pero no se puede registrar un miembro del profesor recién contratado que aún no haya sido asignado para impartir ningún curso, excepto si se establece el código de curso en null .
- Anomalía de actualización
- La misma información se puede expresar en varias filas; por lo tanto, las actualizaciones de la relación pueden dar lugar a inconsistencias lógicas. Por ejemplo, cada registro de una relación "Habilidades de los empleados" puede contener un ID de empleado, una dirección de empleado y una habilidad; por lo tanto, es posible que sea necesario aplicar un cambio de dirección para un empleado en particular a varios registros (uno para cada habilidad). Si la actualización solo se realiza parcialmente (la dirección del empleado se actualiza en algunos registros, pero no en otros), la relación queda en un estado inconsistente. En concreto, la relación proporciona respuestas contradictorias a la pregunta de cuál es la dirección de este empleado en particular.
- Anomalía de eliminación
- En determinadas circunstancias, la eliminación de datos que representan ciertos hechos requiere la eliminación de datos que representan hechos completamente diferentes. La relación "Profesorado y sus cursos" descrita en el ejemplo anterior sufre este tipo de anomalía, ya que si un miembro del profesorado deja de estar asignado temporalmente a algún curso, el último de los registros en el que aparece ese miembro del profesorado debe eliminarse, lo que en la práctica también elimina al miembro del profesorado, a menos que el campo Código del curso se establezca en nulo.
Minimizar el rediseño al ampliar la estructura de la base de datos
Una base de datos completamente normalizada permite que su estructura se amplíe para dar cabida a nuevos tipos de datos sin cambiar demasiado la estructura existente. Como resultado, las aplicaciones que interactúan con la base de datos se ven mínimamente afectadas.
Las relaciones normalizadas, y la relación entre una relación normalizada y otra, reflejan conceptos del mundo real y sus interrelaciones.
Formas normales
Codd introdujo el concepto de normalización y lo que ahora se conoce como la primera forma normal (1NF) en 1970. [4] Codd definió la segunda forma normal (2NF) y la tercera forma normal (3NF) en 1971, [5] y Codd y Raymond F. Boyce definieron la forma normal de Boyce-Codd (BCNF) en 1974. [6]
De manera informal, una relación de base de datos relacional a menudo se describe como "normalizada" si cumple con la tercera forma normal. [7] La mayoría de las relaciones 3NF están libres de anomalías de inserción, actualización y eliminación.
Las formas normales (de menos normalizada a más normalizada) son:
- UNF: Forma no normalizada
- 1NF: Primera forma normal
- 2NF: Segunda forma normal
- 3NF: Tercera forma normal
- EKNF: Forma normal de clave elemental
- BCNF: Forma normal de Boyce-Codd
- 4NF: Cuarta forma normal
- ETNF: Forma normal de tupla esencial
- 5NF: Quinta forma normal
- DKNF: Forma normal de clave de dominio
- 6NF: Sexta forma normal
| Restricción (descripción informal entre paréntesis) | Universidad de Florida (1970) | 1NF (1970) | 2NF (1971) | 3NF (1971) | EKNF (1982) | NFBC (1974) | 4NF (1977) | Fundación Nacional de la Educación (2012) | 5NF (1979) | El FN (1981) | 6NF (2003) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Filas únicas (sin registros duplicados) [4] |  |  | | | | | | | | | |
| Columnas escalares (las columnas no pueden contener relaciones o valores compuestos) [5] |  | | | | | | | | | | |
| Cada atributo no principal tiene una dependencia funcional completa de cada clave candidata (los atributos dependen de la totalidad de cada clave) [5] | | | | | | | | | | | |
| Toda dependencia funcional no trivial comienza con una superclave o termina con un atributo principal (los atributos dependen solo de las claves candidatas) [5] | | | | | | | | | | | |
| Toda dependencia funcional no trivial comienza con una superclave o termina con un atributo primo elemental (una forma más estricta de 3NF) | | | | | | | | | | | — |
| Toda dependencia funcional no trivial comienza con una superclave (una forma más estricta de 3NF) | | | | | | | | | | | — |
| Toda dependencia multivalor no trivial comienza con una superclave | | | | | | | | | | | — |
| Cada dependencia de unión tiene un componente de superclave [8] | | | | | | | | | | | — |
| Cada dependencia de unión solo tiene componentes de superclave | | | | | | | | | | | — |
| Toda restricción es una consecuencia de las restricciones del dominio y de las restricciones clave. | | | | | | | | | | | |
| Cada dependencia de unión es trivial | | | | | | | | | | | |
Ejemplo de una normalización paso a paso
La normalización es una técnica de diseño de bases de datos que se utiliza para diseñar una tabla de base de datos relacional hasta una forma normal superior. [9] El proceso es progresivo y no se puede lograr un nivel más alto de normalización de la base de datos a menos que se hayan satisfecho los niveles anteriores. [10]
Esto significa que, al tener datos en forma no normalizada (la menos normalizada) y apuntar a lograr el mayor nivel de normalización, el primer paso sería asegurar el cumplimiento de la primera forma normal , el segundo paso sería asegurar que se satisfaga la segunda forma normal , y así sucesivamente en el orden mencionado anteriormente, hasta que los datos se ajusten a la sexta forma normal .
Sin embargo, vale la pena señalar que las formas normales más allá de 4NF son principalmente de interés académico, ya que los problemas que existen para resolver rara vez aparecen en la práctica. [11]
Los datos del siguiente ejemplo se diseñaron intencionalmente para contradecir la mayoría de las formas normales. En la práctica, a menudo es posible omitir algunos de los pasos de normalización porque los datos ya están normalizados hasta cierto punto. La corrección de una violación de una forma normal también suele corregir una violación de una forma normal superior. En el ejemplo, se ha elegido una tabla para la normalización en cada paso, lo que significa que, al final, es posible que algunas tablas no estén lo suficientemente normalizadas.
Datos iniciales
Sea una tabla de base de datos con la siguiente estructura: [10]
| Título | Autor | Nacionalidad del autor | Formato | Precio | Sujeto | Páginas | Espesor | Editor | País del editor | Identificación de género | Nombre del género | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Introducción al diseño y optimización de bases de datos MySQL | Chad Russell | Americano | De tapa dura | 49,99 |
| 520 | Grueso | Apretar | EE.UU | 1 | Tutorial |
Para este ejemplo se supone que cada libro tiene un solo autor.
Una tabla que se ajusta al modelo relacional tiene una clave principal que identifica de forma única una fila. En nuestro ejemplo, la clave principal es una clave compuesta de {Título, Formato} (indicada por el subrayado):
| Título | Autor | Nacionalidad del autor | Formato | Precio | Sujeto | Páginas | Espesor | Editor | País del editor | Identificación de género | Nombre del género | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Introducción al diseño y optimización de bases de datos MySQL | Chad Russell | Americano | De tapa dura | 49,99 |
| 520 | Grueso | Apretar | EE.UU | 1 | Tutorial |
Satisfactorio 1NF
En la primera forma normal, cada campo contiene un único valor. Un campo no puede contener un conjunto de valores ni un registro anidado.
El sujeto contiene un conjunto de valores de sujeto, lo que significa que no cumple.
Para resolver el problema, los sujetos se extraen en una tabla de sujetos separada : [10]
| Título | Autor | Nacionalidad del autor | Formato | Precio | Páginas | Espesor | Editor | País del editor | Identificación de género | Nombre del género |
|---|---|---|---|---|---|---|---|---|---|---|
| Introducción al diseño y optimización de bases de datos MySQL | Chad Russell | Americano | De tapa dura | 49,99 | 520 | Grueso | Apretar | EE.UU | 1 | Tutorial |
| Título | Nombre del sujeto |
|---|---|
| Introducción al diseño y optimización de bases de datos MySQL | MySQL |
| Introducción al diseño y optimización de bases de datos MySQL | Base de datos |
| Introducción al diseño y optimización de bases de datos MySQL | Diseño |
En lugar de una tabla en forma no normalizada , ahora hay dos tablas que cumplen con la 1NF.
Satisfactorio 2NF
Recuerde que la tabla Book que se muestra a continuación tiene una clave compuesta de {Título, Formato} , que no cumplirá con la 2NF si algún subconjunto de esa clave es un determinante. En este punto de nuestro diseño, la clave no está finalizada como clave principal , por lo que se denomina clave candidata . Considere la siguiente tabla:
| Título | Formato | Autor | Nacionalidad del autor | Precio | Páginas | Espesor | Editor | País del editor | Identificación de género | Nombre del género |
|---|---|---|---|---|---|---|---|---|---|---|
| Introducción al diseño y optimización de bases de datos MySQL | De tapa dura | Chad Russell | Americano | 49,99 | 520 | Grueso | Apretar | EE.UU | 1 | Tutorial |
| Introducción al diseño y optimización de bases de datos MySQL | Libro electrónico | Chad Russell | Americano | 22.34 | 520 | Grueso | Apretar | EE.UU | 1 | Tutorial |
| El modelo relacional para la gestión de bases de datos: versión 2 | Libro electrónico | Código EFC | británico | 13,88 | 538 | Grueso | Addison Wesley | EE.UU | 2 | Ciencia popular |
| El modelo relacional para la gestión de bases de datos: versión 2 | Libro de bolsillo | Código EFC | británico | 39,99 | 538 | Grueso | Addison Wesley | EE.UU | 2 | Ciencia popular |
Todos los atributos que no forman parte de la clave candidata dependen de Title , pero solo Price también depende de Format . Para cumplir con 2NF y eliminar duplicados, cada atributo que no sea de la clave candidata debe depender de toda la clave candidata, no solo de una parte de ella.
Para normalizar esta tabla, haga que {Title} sea una clave candidata (simple) (la clave principal) de modo que cada atributo que no sea una clave candidata dependa de la clave candidata completa, y elimine Price en una tabla separada para que se pueda preservar su dependencia de Format :
| Título | Autor | Nacionalidad del autor | Páginas | Espesor | Editor | País del editor | Identificación de género | Nombre del género |
|---|---|---|---|---|---|---|---|---|
| Introducción al diseño y optimización de bases de datos MySQL | Chad Russell | Americano | 520 | Grueso | Apretar | EE.UU | 1 | Tutorial |
| El modelo relacional para la gestión de bases de datos: versión 2 | Código EFC | británico | 538 | Grueso | Addison Wesley | EE.UU | 2 | Ciencia popular |
| Título | Formato | Precio |
|---|---|---|
| Introducción al diseño y optimización de bases de datos MySQL | De tapa dura | 49,99 |
| Introducción al diseño y optimización de bases de datos MySQL | Libro electrónico | 22.34 |
| El modelo relacional para la gestión de bases de datos: versión 2 | Libro electrónico | 13,88 |
| El modelo relacional para la gestión de bases de datos: versión 2 | Libro de bolsillo | 39,99 |
Ahora, tanto la tabla de Libros como la de Precios se ajustan a la 2NF .
Satisfaciendo 3NF
La tabla Book todavía tiene una dependencia funcional transitiva ({Author Nationality} depende de {Author}, que a su vez depende de {Title}). Existen violaciones similares para la editorial ({Publisher Country} depende de {Publisher}, que a su vez depende de {Title}) y para el género ({Genre Name} depende de {Genre ID}, que a su vez depende de {Title}). Por lo tanto, la tabla Book no está en 3NF. Para resolver esto, podemos colocar {Author Nationality}, {Publisher Country} y {Genre Name} en sus respectivas tablas, eliminando así las dependencias funcionales transitivas:
| Título | Autor | Páginas | Espesor | Editor | Identificación de género |
|---|---|---|---|---|---|
| Introducción al diseño y optimización de bases de datos MySQL | Chad Russell | 520 | Grueso | Apretar | 1 |
| El modelo relacional para la gestión de bases de datos: versión 2 | Código EFC | 538 | Grueso | Addison Wesley | 2 |
|
| Autor | Nacionalidad del autor |
|---|---|
| Chad Russell | Americano |
| Código EFC | británico |
| Editor | País |
|---|---|
| Apretar | EE.UU |
| Addison Wesley | EE.UU |
| Identificación de género | Nombre |
|---|---|
| 1 | Tutorial |
| 2 | Ciencia popular |
Satisfaciendo EKNF
La forma normal de clave elemental (EKNF) se encuentra estrictamente entre la 3NF y la BCNF y no se analiza mucho en la literatura. Su objetivo es "captar las cualidades destacadas tanto de la 3NF como de la BCNF" y evitar los problemas de ambas (es decir, que la 3NF es "demasiado indulgente" y la BCNF es "propensa a la complejidad computacional"). Dado que rara vez se menciona en la literatura, no se incluye en este ejemplo.
Satisfaciendo 4NF
Supongamos que la base de datos pertenece a una franquicia de librerías que tiene varios franquiciados que poseen tiendas en diferentes ubicaciones y, por lo tanto, la librería decidió agregar una tabla que contiene datos sobre la disponibilidad de los libros en diferentes ubicaciones:
| Identificación del franquiciado | Título | Ubicación |
|---|---|---|
| 1 | Introducción al diseño y optimización de bases de datos MySQL | California |
| 1 | Introducción al diseño y optimización de bases de datos MySQL | Florida |
| 1 | Introducción al diseño y optimización de bases de datos MySQL | Texas |
| 1 | El modelo relacional para la gestión de bases de datos: versión 2 | California |
| 1 | El modelo relacional para la gestión de bases de datos: versión 2 | Florida |
| 1 | El modelo relacional para la gestión de bases de datos: versión 2 | Texas |
| 2 | Introducción al diseño y optimización de bases de datos MySQL | California |
| 2 | Introducción al diseño y optimización de bases de datos MySQL | Florida |
| 2 | Introducción al diseño y optimización de bases de datos MySQL | Texas |
| 2 | El modelo relacional para la gestión de bases de datos: versión 2 | California |
| 2 | El modelo relacional para la gestión de bases de datos: versión 2 | Florida |
| 2 | El modelo relacional para la gestión de bases de datos: versión 2 | Texas |
| 3 | Introducción al diseño y optimización de bases de datos MySQL | Texas |
Como esta estructura de tabla consta de una clave principal compuesta , no contiene ningún atributo que no sea clave y ya está en BCNF (y, por lo tanto, también satisface todas las formas normales anteriores). Sin embargo, suponiendo que todos los libros disponibles se ofrecen en cada área, el título no está vinculado de manera inequívoca a una ubicación determinada y, por lo tanto, la tabla no satisface 4NF .
Esto significa que, para satisfacer la cuarta forma normal , esta tabla también debe descomponerse:
|
|
Ahora, cada registro se identifica de forma inequívoca mediante una superclave , por lo tanto, se satisface la 4NF .
ETNF satisfactorio
Supongamos que los franquiciados también pueden encargar libros a distintos proveedores. Supongamos que la relación también está sujeta a la siguiente restricción:
- Si un determinado proveedor suministra un determinado título
- y el título se entrega al franquiciado
- y el franquiciado está siendo abastecido por el proveedor,
- Luego el proveedor suministra el título al franquiciado . [12]
| Identificación del proveedor | Título | Identificación del franquiciado |
|---|---|---|
| 1 | Introducción al diseño y optimización de bases de datos MySQL | 1 |
| 2 | El modelo relacional para la gestión de bases de datos: versión 2 | 2 |
| 3 | Aprendiendo SQL | 3 |
Esta tabla está en 4NF , pero el ID del proveedor es igual a la unión de sus proyecciones: {{ID del proveedor, título}, {Título, ID del franquiciado}, {ID del franquiciado, ID del proveedor}}. Ningún componente de esa dependencia de unión es una superclave (la única superclave es el encabezado completo), por lo que la tabla no satisface la ETNF y se puede descomponer aún más: [12]
|
|
|
La descomposición produce conformidad con ETNF.
Satisfactorio 5NF
Para detectar una tabla que no cumple con la 5NF , normalmente es necesario examinar los datos en profundidad. Supongamos la tabla del ejemplo de la 4NF con una pequeña modificación en los datos y examinemos si cumple con la 5NF :
| Identificación del franquiciado | Título | Ubicación |
|---|---|---|
| 1 | Introducción al diseño y optimización de bases de datos MySQL | California |
| 1 | Aprendiendo SQL | California |
| 1 | El modelo relacional para la gestión de bases de datos: versión 2 | Texas |
| 2 | El modelo relacional para la gestión de bases de datos: versión 2 | California |
Al descomponer esta tabla se reducen las redundancias, lo que da como resultado las dos tablas siguientes:
|
|
La consulta que une estas tablas devolvería los siguientes datos:
| Identificación del franquiciado | Título | Ubicación |
|---|---|---|
| 1 | Introducción al diseño y optimización de bases de datos MySQL | California |
| 1 | Aprendiendo SQL | California |
| 1 | El modelo relacional para la gestión de bases de datos: versión 2 | California |
| 1 | El modelo relacional para la gestión de bases de datos: versión 2 | Texas |
| 1 | Aprendiendo SQL | Texas |
| 1 | Introducción al diseño y optimización de bases de datos MySQL | Texas |
| 2 | El modelo relacional para la gestión de bases de datos: versión 2 | California |
La operación JOIN devuelve tres filas más de las que debería; agregar otra tabla para aclarar la relación da como resultado tres tablas separadas:
|
|
|
¿Qué devolverá ahora el JOIN? En realidad no es posible unir estas tres tablas. Eso significa que no fue posible descomponer la Franquicia - Libro - Ubicación sin pérdida de datos, por lo tanto, la tabla ya satisface 5NF .
CJ Date ha argumentado que sólo una base de datos en 5NF está verdaderamente "normalizada". [13]
Satisfaciendo a DKNF
Echemos un vistazo a la tabla de libros de los ejemplos anteriores y veamos si satisface la forma normal de clave de dominio :
| Título | Páginas | Espesor | Identificación de género | Identificación del editor |
|---|---|---|---|---|
| Introducción al diseño y optimización de bases de datos MySQL | 520 | Grueso | 1 | 1 |
| El modelo relacional para la gestión de bases de datos: versión 2 | 538 | Grueso | 2 | 2 |
| Aprendiendo SQL | 338 | Delgado | 1 | 3 |
| Libro de recetas de SQL | 636 | Grueso | 1 | 3 |
Lógicamente, el grosor se determina por el número de páginas. Eso significa que depende de las páginas , que no es una clave. Pongamos como ejemplo una convención que diga que un libro de hasta 350 páginas se considera "delgado" y un libro de más de 350 páginas se considera "grueso".
Esta convención es técnicamente una restricción, pero no es una restricción de dominio ni una restricción de clave; por lo tanto, no podemos confiar en las restricciones de dominio y las restricciones de clave para mantener la integridad de los datos.
En otras palabras, nada nos impide poner, por ejemplo, "Grueso" para un libro con sólo 50 páginas, y esto hace que la tabla viole DKNF .
Para resolver esto, se crea una tabla que contiene la enumeración que define el grosor y se elimina esa columna de la tabla original:
|
|
De esta manera, se ha eliminado la violación de integridad del dominio y la tabla está en DKNF .
Satisfactorio 6NF
Una definición simple e intuitiva de la sexta forma normal es que "una tabla está en 6NF cuando la fila contiene la clave principal y, como máximo, otro atributo" . [14]
Esto significa, por ejemplo, la tabla Publisher diseñada al crear el 1NF:
| Identificación del editor | Nombre | País |
|---|---|---|
| 1 | Apretar | EE.UU |
necesita descomponerse además en dos tablas:
|
|
La desventaja obvia de 6NF es la proliferación de tablas necesarias para representar la información de una sola entidad. Si una tabla en 5NF tiene una columna de clave principal y N atributos, representar la misma información en 6NF requerirá N tablas; las actualizaciones de múltiples campos de un solo registro conceptual requerirán actualizaciones de múltiples tablas; y las inserciones y eliminaciones requerirán de manera similar operaciones en múltiples tablas. Por esta razón, en bases de datos destinadas a satisfacer necesidades de procesamiento de transacciones en línea (OLTP), no se debe utilizar 6NF.
Sin embargo, en los almacenes de datos , que no permiten actualizaciones interactivas y que están especializados en consultas rápidas de grandes volúmenes de datos, ciertos DBMS utilizan una representación 6NF interna, conocida como almacén de datos en columnas . En situaciones en las que el número de valores únicos de una columna es mucho menor que el número de filas de la tabla, el almacenamiento orientado a columnas permite un ahorro significativo de espacio mediante la compresión de datos. El almacenamiento en columnas también permite la ejecución rápida de consultas de rango (por ejemplo, mostrar todos los registros en los que una columna en particular se encuentra entre X e Y, o es menor que X).
Sin embargo, en todos estos casos, el diseñador de la base de datos no tiene que realizar la normalización 6NF manualmente mediante la creación de tablas independientes. Algunos DBMS especializados en el almacenamiento, como Sybase IQ , utilizan el almacenamiento en columnas de forma predeterminada, pero el diseñador sigue viendo solo una única tabla de varias columnas. Otros DBMS, como Microsoft SQL Server 2012 y versiones posteriores, permiten especificar un "índice de almacén de columnas" para una tabla en particular. [15]
Véase también
Notas y referencias
- ^ "La adopción de un modelo relacional de datos... permite el desarrollo de un sublenguaje de datos universal basado en un cálculo de predicados aplicado. Un cálculo de predicados de primer orden es suficiente si la colección de relaciones está en forma normal. Un lenguaje de este tipo proporcionaría un criterio de potencia lingüística para todos los demás lenguajes de datos propuestos, y sería en sí mismo un candidato fuerte para su incorporación (con la modificación sintáctica adecuada) en una variedad de lenguajes anfitriones (de programación, orientados a comandos o a problemas)." Codd, "Un modelo relacional de datos para grandes bancos de datos compartidos" Archivado el 12 de junio de 2007 en Wayback Machine , p. 381
- ^ Codd, EF Capítulo 23, "Graves fallas en SQL", en El modelo relacional para la gestión de bases de datos: versión 2. Addison-Wesley (1990), págs. 371–389
- ^ Codd, EF "Mayor normalización del modelo relacional de la base de datos", pág. 34
- ^ ab Codd, EF (junio de 1970). "Un modelo relacional de datos para grandes bancos de datos compartidos". Comunicaciones de la ACM . 13 (6): 377–387. doi : 10.1145/362384.362685 . S2CID 207549016.
- ^ abcd Codd, EF "Further Normalization of the Data Base Relational Model". (Presentado en la serie 6 de simposios sobre ciencias de la computación de Courant, "Data Base Systems", Nueva York, 24-25 de mayo de 1971). Informe de investigación de IBM RJ909 (31 de agosto de 1971). Republicado en Randall J. Rustin (ed.), Data Base Systems: Courant Computer Science Symposia Series 6. Prentice-Hall, 1972.
- ^ Codd, EF "Investigaciones recientes sobre sistemas de bases de datos relacionales". Informe de investigación de IBM RJ1385 (23 de abril de 1974). Republicado en Proc. 1974 Congress (Estocolmo, Suecia, 1974), NY: North-Holland (1974).
- ^ Date, CJ (1999). Introducción a los sistemas de bases de datos . Addison-Wesley. pág. 290.
- ^ Darwen, Hugh; Date, CJ; Fagin, Ronald (2012). "Una forma normal para prevenir tuplas redundantes en bases de datos relacionales" (PDF) . Actas de la 15.ª Conferencia internacional sobre teoría de bases de datos . Conferencia conjunta EDBT/ICDT 2012. Serie de actas de conferencias internacionales de la ACM. Association for Computing Machinery . pág. 114. doi :10.1145/2274576.2274589. ISBN . 978-1-4503-0791-8. OCLC 802369023. Archivado (PDF) del original el 6 de marzo de 2016 . Consultado el 22 de mayo de 2018 .
- ^ Kumar, Kunal; Azad, SK (octubre de 2017). "Patrón de diseño de normalización de bases de datos". 2017 4.ª Conferencia internacional de la sección Uttar Pradesh del IEEE sobre electricidad, informática y electrónica (UPCON) . IEEE. págs. 318–322. doi :10.1109/upcon.2017.8251067. ISBN. 9781538630044.S2CID24491594 .
- ^ abc «Normalización de bases de datos en MySQL: cuatro pasos rápidos y sencillos». ComputerWeekly.com . Archivado desde el original el 30 de agosto de 2017. Consultado el 23 de marzo de 2021 .
- ^ "Normalización de bases de datos: quinta forma normal y más allá". Base de conocimientos de MariaDB . Consultado el 23 de enero de 2019 .
- ^ ab Date, CJ (21 de diciembre de 2015). El nuevo diccionario de bases de datos relacionales: términos, conceptos y ejemplos. "O'Reilly Media, Inc.", pág. 138. ISBN 9781491951699.
- ^ Date, CJ (21 de diciembre de 2015). El nuevo diccionario de bases de datos relacionales: términos, conceptos y ejemplos. "O'Reilly Media, Inc.", pág. 163. ISBN 9781491951699.
- ^ "normalización - Me gustaría entender 6NF con un ejemplo". Desbordamiento de pila . Consultado el 23 de enero de 2019 .
- ^ Microsoft Corporation. Índices de almacén de columnas: descripción general. https://docs.microsoft.com/en-us/sql/relational-databases/indexes/columnstore-indexes-overview. Consultado el 23 de marzo de 2020.
Lectura adicional
- Date, CJ (1999), Introducción a los sistemas de bases de datos (8.ª ed.). Addison-Wesley Longman. ISBN 0-321-19784-4 .
- Kent, W. (1983) Una guía sencilla de cinco formas normales en la teoría de bases de datos relacionales , Communications of the ACM, vol. 26, págs. 120-125
- H.-J. Schek, P. Pistor Estructuras de datos para un sistema integrado de gestión de bases de datos y recuperación de información
Enlaces externos
- Kent, William (febrero de 1983). "Una guía sencilla de cinco formas normales en la teoría de bases de datos relacionales". Comunicaciones de la ACM . 26 (2): 120–125. doi : 10.1145/358024.358054 . S2CID 9195704.
- Conceptos básicos de normalización de bases de datos Archivado el 5 de febrero de 2007 en Wayback Machine por Mike Chapple (About.com)
- Introducción a la normalización de bases de datos Archivado el 28 de septiembre de 2011 en Wayback Machine , Parte 2 Archivado el 8 de julio de 2011 en Wayback Machine
- Introducción a la normalización de bases de datos por Mike Hillyer.
- Un tutorial sobre las primeras 3 formas normales por Fred Coulson
- Descripción de los conceptos básicos de normalización de bases de datos por Microsoft
- Normalización en DBMS por Chaitanya (beginnersbook.com)
- Una guía paso a paso para la normalización de bases de datos
- ETNF – Forma normal de tupla esencial Archivado el 6 de marzo de 2016 en Wayback Machine.
