Protocolo de control de transmisión
| Pila de protocolos | |
| Abreviatura | Protocolo de control de tráfico |
|---|---|
| Desarrollador(es) | Vint Cerf y Bob Kahn |
| Introducción | 1974 ( 1974 ) |
| Residencia en | Programa de control de transmisión |
| Capa OSI | Capa de transporte (4) |
| RFC(s) | 9293 |
El Protocolo de Control de Transmisión ( TCP ) es uno de los principales protocolos de la suite de protocolos de Internet . Se originó en la implementación inicial de la red en la que complementó al Protocolo de Internet (IP). Por lo tanto, la suite completa se conoce comúnmente como TCP/IP . TCP proporciona una entrega confiable , ordenada y sin errores de un flujo de octetos (bytes) entre aplicaciones que se ejecutan en hosts que se comunican a través de una red IP. Las principales aplicaciones de Internet, como la World Wide Web , el correo electrónico, la administración remota y la transferencia de archivos , dependen de TCP, que es parte de la capa de transporte de la suite TCP/IP. SSL/TLS a menudo se ejecuta sobre TCP.
TCP está orientado a la conexión , lo que significa que el remitente y el receptor primero deben establecer una conexión basada en parámetros acordados; lo hacen a través del procedimiento de protocolo de enlace de tres vías. [1] El servidor debe estar escuchando (apertura pasiva) las solicitudes de conexión de los clientes antes de que se establezca una conexión. El protocolo de enlace de tres vías (apertura activa), la retransmisión y la detección de errores aumentan la confiabilidad pero alargan la latencia . Las aplicaciones que no requieren un servicio de flujo de datos confiable pueden usar el Protocolo de datagramas de usuario (UDP) en su lugar, que proporciona un servicio de datagramas sin conexión que prioriza el tiempo sobre la confiabilidad. TCP emplea la prevención de congestión de red . Sin embargo, existen vulnerabilidades en TCP, incluida la denegación de servicio , el secuestro de conexión , el veto de TCP y el ataque de reinicio .
| Conjunto de protocolos de Internet |
|---|
| Capa de aplicación |
| Capa de transporte |
|
| Capa de Internet |
| Capa de enlace |
Origen histórico
En mayo de 1974, Vint Cerf y Bob Kahn describieron un protocolo de interconexión de redes para compartir recursos mediante conmutación de paquetes entre nodos de red. [2] Los autores habían estado trabajando con Gérard Le Lann para incorporar conceptos del proyecto francés CYCLADES en la nueva red. [3] La especificación del protocolo resultante, RFC 675 ( Especificación del programa de control de transmisión de Internet ), fue escrita por Vint Cerf, Yogen Dalal y Carl Sunshine, y publicada en diciembre de 1974. [4] Contiene el primer uso atestiguado del término internet , como una abreviatura de interconexión de redes . [ cita requerida ]
El Programa de Control de Transmisión incorporó enlaces orientados a conexión y servicios de datagramas entre hosts. En la versión 4, el Programa de Control de Transmisión monolítico se dividió en una arquitectura modular que consistía en el Protocolo de Control de Transmisión y el Protocolo de Internet . [5] [6] Esto dio como resultado un modelo de red que se conoció informalmente como TCP/IP , aunque formalmente se lo denominó modelo de arquitectura de Internet del Departamento de Defensa ( modelo DoD para abreviar) o modelo DARPA . [7] [8] [9] Más tarde, se convirtió en parte de, y sinónimo de, el Conjunto de Protocolos de Internet .
Los siguientes documentos de Internet Experiment Note (IEN) describen la evolución de TCP hasta la versión moderna: [10]
- IEN 5 Especificación del programa de control de transmisión de Internet TCP versión 2 ( marzo de 1977).
- IEN 21 Especificación del programa de control de transmisión de interconexión de redes TCP versión 3 ( enero de 1978).
- IEN 27
- IEN 40
- IEN 44
- IEN 55
- IEN 81
- IEN 112
- IEN 124
El TCP se estandarizó en enero de 1980 como RFC 761.
En 2004, Vint Cerf y Bob Kahn recibieron el Premio Turing por su trabajo fundacional sobre TCP/IP. [11] [12]
Función de red
El Protocolo de Control de Transmisión proporciona un servicio de comunicación en un nivel intermedio entre un programa de aplicación y el Protocolo de Internet. Proporciona conectividad de host a host en la capa de transporte del modelo de Internet . Una aplicación no necesita conocer los mecanismos particulares para enviar datos a través de un enlace a otro host, como la fragmentación de IP requerida para acomodar la unidad de transmisión máxima del medio de transmisión. En la capa de transporte, TCP maneja todos los detalles de transmisión y de establecimiento de contacto y presenta una abstracción de la conexión de red a la aplicación, generalmente a través de una interfaz de socket de red .
En los niveles inferiores de la pila de protocolos, debido a la congestión de la red , el equilibrio de la carga de tráfico o un comportamiento impredecible de la red, los paquetes IP pueden perderse , duplicarse o entregarse fuera de orden . TCP detecta estos problemas, solicita la retransmisión de los datos perdidos, reorganiza los datos fuera de orden e incluso ayuda a minimizar la congestión de la red para reducir la aparición de otros problemas. Si los datos siguen sin entregarse, se notifica a la fuente de este fallo. Una vez que el receptor TCP ha vuelto a ensamblar la secuencia de octetos transmitidos originalmente, los pasa a la aplicación receptora. De este modo, TCP abstrae la comunicación de la aplicación de los detalles de red subyacentes.
TCP es ampliamente utilizado por muchas aplicaciones de Internet, incluidas la World Wide Web (WWW), el correo electrónico, el Protocolo de transferencia de archivos , Secure Shell , el intercambio de archivos entre pares y la transmisión de medios .
El protocolo TCP está optimizado para una entrega precisa en lugar de una entrega oportuna y puede incurrir en demoras relativamente largas (del orden de segundos) mientras se esperan mensajes fuera de orden o retransmisiones de mensajes perdidos. Por lo tanto, no es particularmente adecuado para aplicaciones en tiempo real como voz sobre IP . Para tales aplicaciones, generalmente se recomiendan protocolos como el Protocolo de transporte en tiempo real (RTP) que opera sobre el Protocolo de datagramas de usuario (UDP). [13]
TCP es un servicio de entrega de flujo de bytes confiable que garantiza que todos los bytes recibidos serán idénticos y estarán en el mismo orden que los enviados. Dado que la transferencia de paquetes por parte de muchas redes no es confiable, TCP logra esto utilizando una técnica conocida como acuse de recibo positivo con retransmisión . Esto requiere que el receptor responda con un mensaje de acuse de recibo cuando recibe los datos. El remitente mantiene un registro de cada paquete que envía y mantiene un temporizador desde el momento en que se envió el paquete. El remitente retransmite un paquete si el temporizador expira antes de recibir el acuse de recibo. El temporizador es necesario en caso de que un paquete se pierda o se corrompa. [13]
Mientras que el protocolo IP se encarga de la entrega real de los datos, el protocolo TCP realiza un seguimiento de los segmentos (las unidades individuales de transmisión de datos en las que se divide un mensaje para un enrutamiento eficiente a través de la red). Por ejemplo, cuando se envía un archivo HTML desde un servidor web, la capa de software TCP de ese servidor divide el archivo en segmentos y los reenvía individualmente a la capa de Internet en la pila de red . El software de la capa de Internet encapsula cada segmento TCP en un paquete IP agregando un encabezado que incluye (entre otros datos) la dirección IP de destino . Cuando el programa cliente en la computadora de destino los recibe, el software TCP en la capa de transporte vuelve a ensamblar los segmentos y se asegura de que estén correctamente ordenados y libres de errores mientras transmite el contenido del archivo a la aplicación receptora.
Estructura del segmento TCP
El Protocolo de Control de Transmisión acepta datos de un flujo de datos, los divide en fragmentos y agrega un encabezado TCP para crear un segmento TCP. Luego, el segmento TCP se encapsula en un datagrama de Protocolo de Internet (IP) y se intercambia con los pares. [14]
El término paquete TCP aparece tanto en el uso informal como en el formal, mientras que en una terminología más precisa segmento se refiere a la unidad de datos del protocolo TCP (PDU), datagrama [15] a la PDU IP y trama a la PDU de la capa de enlace de datos :
Los procesos transmiten datos llamando al TCP y pasando buffers de datos como argumentos. El TCP empaqueta los datos de estos buffers en segmentos y llama al módulo de Internet [p. ej., IP] para transmitir cada segmento al TCP de destino. [16]
Un segmento TCP consta de un encabezado de segmento y una sección de datos . El encabezado de segmento contiene 10 campos obligatorios y un campo de extensión opcional ( Opciones , fondo rosa en la tabla). La sección de datos sigue al encabezado y son los datos de carga útil transportados para la aplicación. [17] La longitud de la sección de datos no se especifica en el encabezado de segmento; se puede calcular restando la longitud combinada del encabezado de segmento y el encabezado IP de la longitud total del datagrama IP especificada en el encabezado IP. [ cita requerida ]
| Compensar | Octeto | 0 | 1 | 2 | 3 | ||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Octeto | Poco | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| 0 | 0 | Puerto de origen | Puerto de destino | ||||||||||||||||||||||||||||||
| 4 | 32 | Número de secuencia | |||||||||||||||||||||||||||||||
| 8 | 64 | Número de reconocimiento (significativo cuando se establece el bit ACK) | |||||||||||||||||||||||||||||||
| 12 | 96 | Desplazamiento de datos | Reservado | CWR | CEPE | Urgencia | Acuse de recibo | PSH | Primera vez | SINÓNIMO | ALETA | Ventana | |||||||||||||||||||||
| 16 | 128 | Suma de comprobación | Puntero urgente (significativo cuando el bit URG está establecido) [18] | ||||||||||||||||||||||||||||||
| 20 | 160 | (Opciones) Si está presente, el desplazamiento de datos será mayor que 5. Se rellena con ceros hasta un múltiplo de 32 bits, ya que el desplazamiento de datos cuenta palabras de 4 octetos. | |||||||||||||||||||||||||||||||
| ⋮ | ⋮ | ||||||||||||||||||||||||||||||||
| 56 | 448 | ||||||||||||||||||||||||||||||||
| 60 | 480 | Datos | |||||||||||||||||||||||||||||||
| 64 | 512 | ||||||||||||||||||||||||||||||||
| ⋮ | ⋮ | ||||||||||||||||||||||||||||||||
- Puerto de origen: 16 bits
- Identifica el puerto de envío.
- Puerto de destino: 16 bits
- Identifica el puerto de recepción.
- Número de secuencia: 32 bits
- Tiene una doble función:
- Si el indicador SYN está establecido (1), este es el número de secuencia inicial. El número de secuencia del primer byte de datos real y el número reconocido en el ACK correspondiente son este número de secuencia más 1.
- Si el indicador SYN no está configurado (0), este es el número de secuencia acumulado del primer byte de datos de este segmento para la sesión actual.
- Número de reconocimiento: 32 bits
- Si se activa el indicador ACK, el valor de este campo es el siguiente número de secuencia que el remitente del ACK espera. Esto confirma la recepción de todos los bytes anteriores (si los hay). [19] El primer ACK enviado por cada extremo confirma el número de secuencia inicial del otro extremo, pero no los datos. [20]
- Desplazamiento de datos (DOffset): 4 bits
- Especifica el tamaño del encabezado TCP en palabras de 32 bits . El tamaño mínimo del encabezado es de 5 palabras y el máximo de 15 palabras, lo que da un tamaño mínimo de 20 bytes y un máximo de 60 bytes, lo que permite hasta 40 bytes de opciones en el encabezado. Este campo recibe su nombre del hecho de que también es el desplazamiento desde el inicio del segmento TCP hasta los datos reales. [ cita requerida ]
- Reservado (Rsrvd): 4 bits
- Para uso futuro y debe establecerse en cero; los remitentes no deben establecerlos y los receptores deben ignorarlos si se configuran, en ausencia de más especificaciones e implementación.
- Entre 2003 y 2017, el último bit (bit 103 del encabezado) se definió como el indicador NS (Nonce Sum) en el RFC experimental 3540, ECN-nonce. El uso de ECN-nonce nunca se generalizó y el RFC pasó a tener el estado histórico. [21]
- Banderas: 8 bits
- Contiene 8 indicadores de 1 bit (bits de control) como se indica a continuación:
- CWR: 1 bit
- El host de envío establece el indicador de ventana de congestión reducida (CWR) para indicar que recibió un segmento TCP con el indicador ECE establecido y que respondió en el mecanismo de control de congestión. [22] [a]
- ECE: 1 bit
- ECN-Echo tiene una doble función, según el valor del indicador SYN. Indica:
- Si el indicador SYN está configurado (1), el par TCP tiene capacidad ECN . [23]
- Si el indicador SYN no está configurado (0), se recibió un paquete con el indicador Congestión experimentada configurado (ECN=11) en su encabezado IP durante la transmisión normal. [a] Esto sirve como una indicación de congestión de red (o congestión inminente) para el remitente TCP. [24]
- Urg: 1 bit
- Indica que el campo de puntero Urgente es significativo.
- ACK: 1 bit
- Indica que el campo de acuse de recibo es significativo. Todos los paquetes posteriores al paquete SYN inicial enviado por el cliente deben tener este indicador activado. [25]
- PSH: 1 bit
- Función Push. Solicita enviar los datos almacenados en el búfer a la aplicación receptora.
- RST: 1 bit
- Restablecer la conexión
- SIN.: 1 bit
- Sincronizar números de secuencia. Solo el primer paquete enviado desde cada extremo debe tener este indicador activado. Algunos otros indicadores y campos cambian de significado en función de este indicador, y algunos solo son válidos cuando está activado y otros cuando está desactivado.
- FIN: 1 bit
- Último paquete del remitente
- Ventana: 16 bits
- El tamaño de la ventana de recepción , que especifica la cantidad de unidades de tamaño de ventana [b] que el remitente de este segmento está dispuesto a recibir actualmente. [c] (Véase § Control de flujo y § Escala de ventana).
- Suma de comprobación : 16 bits
- El campo de suma de comprobación de 16 bits se utiliza para comprobar si hay errores en el encabezado TCP, la carga útil y un pseudoencabezado IP. El pseudoencabezado consta de la dirección IP de origen , la dirección IP de destino , el número de protocolo para el protocolo TCP (6) y la longitud de los encabezados TCP y la carga útil (en bytes).
- Puntero urgente: 16 bits
- Si se establece el indicador URG, este campo de 16 bits es un desplazamiento del número de secuencia que indica el último byte de datos urgentes.
- Opciones (Opción TCP): Variable de 0 a 320 bits, en unidades de 32 bits; tamaño (Opciones) == (DOffset - 5) * 32
- La longitud de este campo está determinada por el campo Desplazamiento de datos . El relleno del encabezado TCP se utiliza para garantizar que el encabezado TCP finalice y los datos comiencen en un límite de 32 bits. El relleno está compuesto de ceros. [16]
- Las opciones tienen hasta tres campos: Option-Kind (1 byte), Option-Length (1 byte), Option-Data (variable). El campo Option-Kind indica el tipo de opción y es el único campo que no es opcional. Según el valor de Option-Kind, se pueden configurar los dos campos siguientes. Option-Length indica la longitud total de la opción y Option-Data contiene los datos asociados con la opción, si corresponde. Por ejemplo, un byte Option-Kind de 1 indica que se trata de una opción sin operación que se utiliza solo para relleno y no tiene campos Option-Length u Option-Data a continuación. Un byte Option-Kind de 0 marca el final de las opciones y también es solo un byte. Un byte Option-Kind de 2 se utiliza para indicar la opción Tamaño máximo de segmento y será seguido por un byte Option-Length que especifica la longitud del campo MSS. Option-Length es la longitud total del campo de opciones dado, incluidos los campos Option-Kind y Option-Length. Entonces, mientras que el valor MSS normalmente se expresa en dos bytes, Option-Length será 4. A modo de ejemplo, un campo de opción MSS con un valor de 0x05B4 se codifica como ( 0x02 0x04 0x05B4 ) en la sección de opciones TCP.
- Algunas opciones solo se pueden enviar cuando se configura SYN. Se indican a continuación como
[SYN]. Tipo de opción y longitudes estándar como (Tipo de opción, Longitud de opción).
Tipo de opción Opción-Longitud Opción-Datos Objetivo Notas 0 — — Fin de la lista de opciones 1 — — Sin operación Esto se puede utilizar para alinear los campos de opciones en límites de 32 bits para un mejor rendimiento. 2 4 Espartano Tamaño máximo del segmento Consulte § Tamaño máximo de segmento para obtener más detalles. [SYN]3 3 S Escala de ventana Consulte § Escala de ventana para obtener más detalles. [26] [SYN]4 2 — Se permite el reconocimiento selectivo Véase el § Agradecimientos selectivos para más detalles. [27] [SYN]5 N (10, 18, 26 o 34) BBBB, EEEE, ... Reconocimiento selectivo de mensajes (SACK) [28] A estos dos primeros bytes les sigue una lista de 1 a 4 bloques que se reconocen de forma selectiva y se especifican como punteros de inicio/fin de 32 bits. 8 10 TTTT, EEEE Marca de tiempo y eco de la marca de tiempo anterior Consulte § Marcas de tiempo TCP para obtener más detalles. [26] 28 4 — Opción de tiempo de espera del usuario Consulte RFC 5482. 29 norte — Opción de autenticación TCP (TCP-AO) Para la autenticación de mensajes, reemplazando la autenticación MD5 (opción 19) originalmente diseñada para proteger sesiones BGP . [29] Véase RFC 5925. 30 norte — Protocolo multitrayecto (MPTCP) Consulte Multipath TCP para obtener más detalles.
- Los valores de Option-Kind restantes son históricos, obsoletos, experimentales, aún no estandarizados o no asignados. Las asignaciones de números de opción las mantiene la Autoridad de Números Asignados de Internet (IANA). [30]
- Datos : Variable
- La carga útil del paquete TCP
Operación del protocolo

Las operaciones del protocolo TCP se pueden dividir en tres fases. El establecimiento de la conexión es un proceso de enlace de varios pasos que establece una conexión antes de entrar en la fase de transferencia de datos . Una vez finalizada la transferencia de datos, la terminación de la conexión cierra la conexión y libera todos los recursos asignados.
Una conexión TCP es administrada por un sistema operativo a través de un recurso que representa el punto final local para las comunicaciones, el socket de Internet . Durante la vida útil de una conexión TCP, el punto final local sufre una serie de cambios de estado : [31]
| Estado | Punto final | Descripción |
|---|---|---|
| ESCUCHAR | Servidor | Esperando una solicitud de conexión desde cualquier punto final TCP remoto. |
| SYN-SENT | Cliente | Esperando una solicitud de conexión coincidente después de haber enviado una solicitud de conexión. |
| SYN-RECIBIDO | Servidor | Esperando un acuse de recibo de solicitud de conexión después de haber recibido y enviado una solicitud de conexión. |
| ESTABLECIDO | Servidor y cliente | Conexión abierta, los datos recibidos pueden entregarse al usuario. Estado normal de la fase de transferencia de datos de la conexión. |
| FIN-ESPERA-1 | Servidor y cliente | Esperando una solicitud de finalización de conexión del TCP remoto, o un reconocimiento de la solicitud de finalización de conexión enviada previamente. |
| FIN-ESPERA-2 | Servidor y cliente | Esperando una solicitud de finalización de conexión del TCP remoto. |
| CERRAR-ESPERAR | Servidor y cliente | Esperando una solicitud de finalización de conexión del usuario local. |
| CIERRE | Servidor y cliente | Esperando un acuse de recibo de solicitud de finalización de conexión del TCP remoto. |
| ÚLTIMO ACK | Servidor y cliente | Esperando un reconocimiento de la solicitud de finalización de conexión enviada previamente al TCP remoto (que incluye un reconocimiento de su solicitud de finalización de conexión). |
| TIEMPO DE ESPERA | Servidor o cliente | Esperando que pase el tiempo suficiente para estar seguro de que todos los paquetes restantes en la conexión hayan expirado. |
| CERRADO | Servidor y cliente | No hay ningún estado de conexión en absoluto. |
Establecimiento de conexión
Antes de que un cliente intente conectarse con un servidor, el servidor primero debe vincularse a un puerto y escuchar en él para abrirlo a las conexiones: esto se denomina apertura pasiva. Una vez que se establece la apertura pasiva, un cliente puede establecer una conexión iniciando una apertura activa mediante el protocolo de enlace de tres vías (o de tres pasos):
- SYN : La apertura activa se realiza cuando el cliente envía un SYN al servidor. El cliente establece el número de secuencia del segmento en un valor aleatorio A.
- SYN-ACK : En respuesta, el servidor responde con un SYN-ACK. El número de acuse de recibo se establece en uno más que el número de secuencia recibido, es decir, A+1, y el número de secuencia que el servidor elige para el paquete es otro número aleatorio, B.
- ACK : Por último, el cliente envía un ACK al servidor. El número de secuencia se establece en el valor de confirmación recibido, es decir, A+1, y el número de confirmación se establece en uno más que el número de secuencia recibido, es decir, B+1.
Los pasos 1 y 2 establecen y reconocen el número de secuencia para una dirección (del cliente al servidor). Los pasos 2 y 3 establecen y reconocen el número de secuencia para la otra dirección (del servidor al cliente). Una vez completados estos pasos, tanto el cliente como el servidor han recibido los reconocimientos y se ha establecido una comunicación full-duplex.
Terminación de la conexión
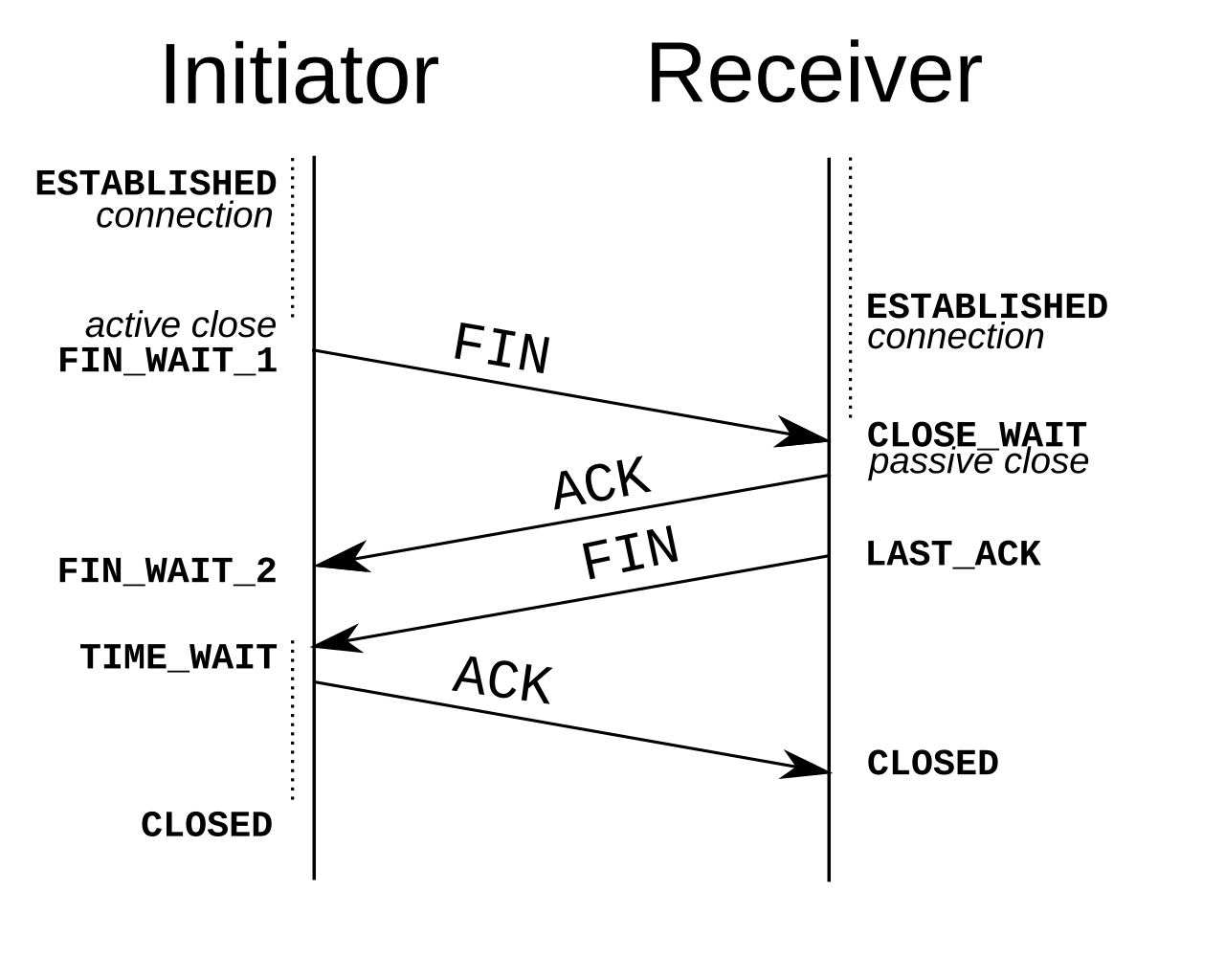
_-_sequence_diagram.svg/1280px-TCP_close()_-_sequence_diagram.svg.png)
La fase de terminación de la conexión utiliza un protocolo de enlace de cuatro vías, en el que cada lado de la conexión termina de forma independiente. Cuando un punto final desea detener su mitad de la conexión, transmite un paquete FIN, que el otro extremo reconoce con un ACK. Por lo tanto, una desconexión típica requiere un par de segmentos FIN y ACK de cada punto final TCP. Después de que el lado que envió el primer FIN haya respondido con el ACK final, espera un tiempo de espera antes de cerrar finalmente la conexión, durante el cual el puerto local no está disponible para nuevas conexiones; este estado permite al cliente TCP reenviar el reconocimiento final al servidor en caso de que el ACK se pierda en tránsito. La duración del tiempo depende de la implementación, pero algunos valores comunes son 30 segundos, 1 minuto y 2 minutos. Después del tiempo de espera, el cliente ingresa al estado CERRADO y el puerto local queda disponible para nuevas conexiones. [32]
También es posible finalizar la conexión mediante un protocolo de enlace de tres vías, cuando el host A envía un FIN y el host B responde con un FIN y ACK (combinando dos pasos en uno) y el host A responde con un ACK. [33]
Algunos sistemas operativos, como Linux y HP-UX , [ cita requerida ] implementan una secuencia de cierre half-duplex. Si el host cierra activamente una conexión, aunque todavía tenga datos entrantes sin leer disponibles, el host envía la señal RST (perdiendo cualquier dato recibido) en lugar de FIN. Esto asegura que una aplicación TCP esté al tanto de que hubo una pérdida de datos. [34]
Una conexión puede estar en un estado semiabierto , en cuyo caso un lado ha terminado la conexión, pero el otro no. El lado que ha terminado ya no puede enviar más datos a la conexión, pero el otro lado sí puede. El lado que termina debe continuar leyendo los datos hasta que el otro lado también termine. [ cita requerida ]
Uso de recursos
La mayoría de las implementaciones asignan una entrada en una tabla que asigna una sesión a un proceso del sistema operativo en ejecución. Debido a que los paquetes TCP no incluyen un identificador de sesión, ambos puntos finales identifican la sesión utilizando la dirección y el puerto del cliente. Siempre que se recibe un paquete, la implementación TCP debe realizar una búsqueda en esta tabla para encontrar el proceso de destino. Cada entrada de la tabla se conoce como bloque de control de transmisión o TCB. Contiene información sobre los puntos finales (IP y puerto), el estado de la conexión, los datos en ejecución sobre los paquetes que se están intercambiando y los búferes para enviar y recibir datos.
El número de sesiones en el lado del servidor está limitado únicamente por la memoria y puede aumentar a medida que llegan nuevas conexiones, pero el cliente debe asignar un puerto efímero antes de enviar el primer SYN al servidor. Este puerto permanece asignado durante toda la conversación y limita de manera efectiva el número de conexiones salientes desde cada una de las direcciones IP del cliente. Si una aplicación no logra cerrar correctamente las conexiones no requeridas, un cliente puede quedarse sin recursos y no poder establecer nuevas conexiones TCP, incluso desde otras aplicaciones.
Ambos puntos finales también deben asignar espacio para paquetes no reconocidos y datos recibidos (pero no leídos).
Transferencia de datos
El Protocolo de Control de Transmisión difiere en varias características clave en comparación con el Protocolo de Datagramas de Usuario :
- Transferencia de datos ordenada: el host de destino reorganiza los segmentos según un número de secuencia [13]
- Retransmisión de paquetes perdidos: cualquier flujo acumulado no reconocido se retransmite [13]
- Transferencia de datos sin errores: los paquetes dañados se tratan como perdidos y se retransmiten [14]
- Control de flujo: limita la velocidad a la que un remitente transfiere datos para garantizar una entrega confiable. El receptor le indica continuamente al remitente cuántos datos puede recibir. Cuando el búfer del host receptor se llena, el siguiente acuse de recibo suspende la transferencia y permite que se procesen los datos en el búfer. [13]
- Control de congestión: los paquetes perdidos (presumiblemente debidos a la congestión) provocan una reducción en la tasa de entrega de datos [13]
Transmisión confiable
TCP utiliza un número de secuencia para identificar cada byte de datos. El número de secuencia identifica el orden de los bytes enviados desde cada computadora, de modo que los datos se puedan reconstruir en orden, independientemente de cualquier entrega fuera de orden que pueda ocurrir. El número de secuencia del primer byte lo elige el transmisor para el primer paquete, que se marca como SYN. Este número puede ser arbitrario y, de hecho, debería ser impredecible para defenderse contra ataques de predicción de secuencia TCP .
Los acuses de recibo (ACK) se envían con un número de secuencia por parte del receptor de datos para indicar al remitente que se han recibido los datos en el byte especificado. Los ACK no implican que los datos se hayan entregado a la aplicación, simplemente significan que ahora es responsabilidad del receptor entregar los datos.
La confiabilidad se logra cuando el remitente detecta la pérdida de datos y los retransmite. TCP utiliza dos técnicas principales para identificar pérdidas: tiempo de espera de retransmisión (RTO) y confirmaciones acumulativas duplicadas (DupAcks).
Cuando se retransmite un segmento TCP, conserva el mismo número de secuencia que el intento de entrega original. Esta combinación de entrega y ordenamiento lógico de datos significa que, cuando se recibe un acuse de recibo después de una retransmisión, el remitente no puede saber si se está acusando recibo de la transmisión original o de la retransmisión, lo que se denomina ambigüedad de retransmisión . [35] TCP incurre en complejidad debido a la ambigüedad de retransmisión. [36]
Retransmisión basada en Dupack
Si se pierde un solo segmento (por ejemplo, el segmento número 100) en un flujo, el receptor no puede reconocer paquetes por encima de ese número de segmento (100) porque utiliza ACK acumulativos. Por lo tanto, el receptor reconoce el paquete 99 nuevamente al recibir otro paquete de datos. Este reconocimiento duplicado se utiliza como una señal de pérdida de paquetes. Es decir, si el remitente recibe tres reconocimientos duplicados, retransmite el último paquete no reconocido. Se utiliza un umbral de tres porque la red puede reordenar segmentos causando reconocimientos duplicados. Se ha demostrado que este umbral evita retransmisiones espurias debido al reordenamiento. [37] Algunas implementaciones de TCP utilizan reconocimientos selectivos (SACK) para proporcionar retroalimentación explícita sobre los segmentos que se han recibido. Esto mejora en gran medida la capacidad de TCP para retransmitir los segmentos correctos.
La ambigüedad de la retransmisión puede provocar retransmisiones rápidas espurias y evitar la congestión si hay un reordenamiento más allá del umbral de reconocimiento duplicado. [38] En las últimas dos décadas se ha observado un mayor reordenamiento de paquetes en Internet [39] , lo que llevó a las implementaciones de TCP, como la del núcleo de Linux, a adoptar métodos heurísticos para escalar el umbral de reconocimiento duplicado. [40] Recientemente, ha habido esfuerzos para eliminar por completo las retransmisiones rápidas basadas en dupack y reemplazarlas por otras basadas en temporizador. [41] (No debe confundirse con el RTO clásico que se analiza a continuación). El algoritmo de detección de pérdida basado en el tiempo llamado Reconocimiento reciente (RACK) [42] se ha adoptado como el algoritmo predeterminado en Linux y Windows. [43]
Retransmisión basada en tiempo de espera
Cuando un remitente transmite un segmento, inicializa un temporizador con una estimación conservadora del tiempo de llegada del acuse de recibo. El segmento se retransmite si el temporizador expira, con un nuevo umbral de tiempo de espera del doble del valor anterior, lo que da como resultado un comportamiento de retroceso exponencial . Normalmente, el valor inicial del temporizador es , donde es la granularidad del reloj. [44] Esto protege contra el tráfico de transmisión excesivo debido a actores defectuosos o maliciosos, como los atacantes de denegación de servicio del tipo "man-in-the-middle" .


Las estimaciones precisas de RTT son importantes para la recuperación de pérdidas, ya que permiten al remitente suponer que un paquete no reconocido se pierde después de que transcurra suficiente tiempo (es decir, determinar el tiempo RTO). [45] La ambigüedad de la retransmisión puede hacer que la estimación de RTT de un remitente sea imprecisa. [45] En un entorno con RTT variables, pueden ocurrir tiempos de espera falsos: [46] si se subestima el RTT, entonces se activa el RTO y desencadena una retransmisión innecesaria y un inicio lento. Después de una retransmisión falsa, cuando llegan los reconocimientos para las transmisiones originales, el remitente puede creer que están reconociendo la retransmisión y concluir, incorrectamente, que se han perdido los segmentos enviados entre la transmisión original y la retransmisión, lo que provoca más retransmisiones innecesarias hasta el punto de que el enlace realmente se congestiona; [47] [48] el reconocimiento selectivo puede reducir este efecto. [49] La RFC 6298 especifica que las implementaciones no deben utilizar segmentos retransmitidos al estimar el RTT. [50] El algoritmo de Karn garantiza que se producirá una buena estimación del RTT (eventualmente) al esperar hasta que haya un reconocimiento inequívoco antes de ajustar el RTO. [51] Sin embargo, después de retransmisiones espurias, puede pasar un tiempo significativo antes de que llegue dicho reconocimiento inequívoco, lo que degrada el rendimiento en el ínterin. [52] Las marcas de tiempo TCP también resuelven el problema de ambigüedad de la retransmisión al establecer el RTO, [50] aunque no necesariamente mejoran la estimación del RTT. [53]
Detección de errores
Los números de secuencia permiten a los receptores descartar paquetes duplicados y secuenciar correctamente los paquetes fuera de orden. Los acuses de recibo permiten a los remitentes determinar cuándo retransmitir los paquetes perdidos.
Para asegurar la corrección, se incluye un campo de suma de comprobación; consulte § Cálculo de la suma de comprobación para obtener más detalles. La suma de comprobación TCP es una comprobación débil según los estándares modernos y normalmente se combina con una comprobación de integridad CRC en la capa 2 , por debajo de TCP e IP, como se utiliza en PPP o en la trama Ethernet . Sin embargo, la introducción de errores en paquetes entre saltos protegidos con CRC es común y la suma de comprobación TCP de 16 bits detecta la mayoría de ellos. [54]
Control de flujo
TCP utiliza un protocolo de control de flujo de extremo a extremo para evitar que el emisor envíe datos demasiado rápido para que el receptor TCP los reciba y procese de manera confiable. Tener un mecanismo para el control de flujo es esencial en un entorno donde se comunican máquinas de distintas velocidades de red. Por ejemplo, si una PC envía datos a un teléfono inteligente que procesa lentamente los datos recibidos, el teléfono inteligente debe poder regular el flujo de datos para no verse sobrecargado. [13]
TCP utiliza un protocolo de control de flujo de ventana deslizante . En cada segmento TCP, el receptor especifica en el campo de ventana de recepción la cantidad de datos adicionales recibidos (en bytes) que está dispuesto a almacenar en búfer para la conexión. El host emisor puede enviar solo hasta esa cantidad de datos antes de tener que esperar un acuse de recibo y recibir una actualización de ventana del host receptor.

Cuando un receptor anuncia un tamaño de ventana de 0, el emisor deja de enviar datos e inicia su temporizador de persistencia . El temporizador de persistencia se utiliza para proteger a TCP de una situación de bloqueo que podría surgir si se pierde una actualización posterior del tamaño de ventana del receptor y el emisor no puede enviar más datos hasta recibir una nueva actualización del tamaño de ventana del receptor. Cuando el temporizador de persistencia expira, el emisor TCP intenta la recuperación enviando un pequeño paquete para que el receptor responda enviando otro acuse de recibo que contenga el nuevo tamaño de ventana.
Si un receptor está procesando datos entrantes en pequeños incrementos, puede anunciar repetidamente una pequeña ventana de recepción. Esto se conoce como el síndrome de la ventana tonta , ya que resulta ineficiente enviar solo unos pocos bytes de datos en un segmento TCP, dada la sobrecarga relativamente grande del encabezado TCP.
Control de congestión
El último aspecto principal de TCP es el control de la congestión . TCP utiliza una serie de mecanismos para lograr un alto rendimiento y evitar el colapso por congestión , una situación de bloqueo en la que el rendimiento de la red se degrada gravemente. Estos mecanismos controlan la velocidad de entrada de datos a la red, manteniendo el flujo de datos por debajo de una velocidad que provocaría un colapso. También producen una asignación aproximadamente justa entre flujos con un valor máximo y mínimo .
Los remitentes utilizan los acuses de recibo de los datos enviados, o la falta de ellos, para inferir las condiciones de la red entre el remitente y el receptor TCP. Junto con los temporizadores, los remitentes y receptores TCP pueden alterar el comportamiento del flujo de datos. Esto se conoce más generalmente como control de congestión o prevención de congestión.
Las implementaciones modernas de TCP contienen cuatro algoritmos entrelazados: inicio lento , evitación de congestión , retransmisión rápida y recuperación rápida . [55]
Además, los remitentes emplean un tiempo de espera de retransmisión (RTO) que se basa en el tiempo de ida y vuelta estimado (RTT) entre el remitente y el receptor, así como en la varianza de este tiempo de ida y vuelta. [56] Existen sutilezas en la estimación de RTT. Por ejemplo, los remitentes deben ser cuidadosos al calcular muestras de RTT para paquetes retransmitidos; normalmente utilizan el algoritmo de Karn o marcas de tiempo TCP. [26] Estas muestras de RTT individuales se promedian a lo largo del tiempo para crear un tiempo de ida y vuelta suavizado (SRTT) utilizando el algoritmo de Jacobson. Este valor de SRTT es lo que se utiliza como estimación del tiempo de ida y vuelta.
La mejora del protocolo TCP para gestionar de forma fiable las pérdidas, minimizar los errores, gestionar la congestión y funcionar con rapidez en entornos de muy alta velocidad son áreas de investigación y desarrollo de estándares en curso. Como resultado, existen diversas variaciones del algoritmo TCP para evitar la congestión .
Tamaño máximo del segmento
El tamaño máximo de segmento (MSS) es la mayor cantidad de datos, especificada en bytes, que TCP está dispuesto a recibir en un solo segmento. Para un mejor rendimiento, el MSS debe configurarse lo suficientemente pequeño como para evitar la fragmentación de IP , que puede provocar la pérdida de paquetes y retransmisiones excesivas. Para lograr esto, normalmente cada lado anuncia el MSS mediante la opción MSS cuando se establece la conexión TCP. El valor de la opción se deriva del tamaño máximo de la unidad de transmisión (MTU) de la capa de enlace de datos de las redes a las que están conectados directamente el remitente y el receptor. Los remitentes TCP pueden utilizar el descubrimiento de la MTU de ruta para inferir la MTU mínima a lo largo de la ruta de red entre el remitente y el receptor, y utilizar esto para ajustar dinámicamente el MSS para evitar la fragmentación de IP dentro de la red.
El anuncio MSS también puede denominarse negociación MSS pero, estrictamente hablando, el MSS no se negocia . Se permiten dos valores completamente independientes de MSS para las dos direcciones de flujo de datos en una conexión TCP, [57] [16] por lo que no es necesario acordar una configuración MSS común para una conexión bidireccional.
Agradecimientos selectivos
Confiar únicamente en el esquema de reconocimiento acumulativo empleado por el TCP original puede generar ineficiencias cuando se pierden paquetes. Por ejemplo, supongamos que se envían bytes con números de secuencia del 1000 al 10 999 en 10 segmentos TCP diferentes de igual tamaño, y el segundo segmento (números de secuencia del 2000 al 2999) se pierde durante la transmisión. En un protocolo de reconocimiento acumulativo puro, el receptor solo puede enviar un valor ACK acumulativo de 2000 (el número de secuencia inmediatamente posterior al último número de secuencia de los datos recibidos) y no puede decir que recibió los bytes del 3000 al 10 999 correctamente. Por lo tanto, el remitente puede tener que volver a enviar todos los datos a partir del número de secuencia 2000.
Para aliviar este problema, TCP emplea la opción de acuse de recibo selectivo (SACK) , definida en 1996 en RFC 2018, que permite al receptor reconocer bloques discontinuos de paquetes que se recibieron correctamente, además del número de secuencia inmediatamente posterior al último número de secuencia del último byte contiguo recibido sucesivamente, como en el acuse de recibo básico de TCP. El acuse de recibo puede incluir una serie de bloques SACK , donde cada bloque SACK se transmite por el borde izquierdo del bloque (el primer número de secuencia del bloque) y el borde derecho del bloque (el número de secuencia inmediatamente posterior al último número de secuencia del bloque), siendo un bloque un rango contiguo que el receptor recibió correctamente. En el ejemplo anterior, el receptor enviaría un segmento ACK con un valor ACK acumulativo de 2000 y un encabezado de opción SACK con los números de secuencia 3000 y 11 000. El remitente retransmitiría entonces únicamente el segundo segmento con los números de secuencia del 2.000 al 2.999.
Un emisor TCP puede interpretar la entrega de un segmento fuera de orden como un segmento perdido. Si lo hace, el emisor TCP retransmitirá el segmento anterior al paquete fuera de orden y reducirá la velocidad de entrega de datos para esa conexión. La opción duplicate-SACK, una extensión de la opción SACK que se definió en mayo de 2000 en RFC 2883, resuelve este problema. Una vez que el receptor TCP detecta un segundo paquete duplicado, envía un D-ACK para indicar que no se perdieron segmentos, lo que permite al emisor TCP restablecer la velocidad de transmisión más alta.
La opción SACK no es obligatoria y entra en funcionamiento solo si ambas partes la admiten. Esto se negocia cuando se establece una conexión. SACK utiliza una opción de encabezado TCP (consulte § Estructura del segmento TCP para obtener más detalles). El uso de SACK se ha generalizado: todas las pilas TCP populares lo admiten. El reconocimiento selectivo también se utiliza en el protocolo de transmisión de control de flujo (SCTP).
Los reconocimientos selectivos pueden ser "renegados", donde el receptor descarta unilateralmente los datos reconocidos selectivamente. El RFC 2018 desaconsejaba tal comportamiento, pero no lo prohibía para permitir a los receptores la opción de renegar si, por ejemplo, se quedaban sin espacio en el búfer. [58] La posibilidad de renegar genera complejidad de implementación tanto para los remitentes como para los receptores, y también impone costos de memoria al remitente. [59]
Escala de ventana
Para un uso más eficiente de redes de gran ancho de banda, se puede utilizar un tamaño de ventana TCP mayor. Un campo de tamaño de ventana TCP de 16 bits controla el flujo de datos y su valor está limitado a 65.535 bytes. Dado que el campo de tamaño no se puede ampliar más allá de este límite, se utiliza un factor de escala. La opción de escala de ventana TCP , tal como se define en RFC 1323, es una opción que se utiliza para aumentar el tamaño máximo de ventana a 1 gigabyte. La ampliación a estos tamaños de ventana más grandes es necesaria para el ajuste de TCP .
La opción de escala de ventana se utiliza únicamente durante el protocolo de enlace de tres vías TCP. El valor de escala de ventana representa la cantidad de bits que se deben desplazar hacia la izquierda el campo de tamaño de ventana de 16 bits al interpretarlo. El valor de escala de ventana se puede configurar de 0 (sin desplazamiento) a 14 para cada dirección de forma independiente. Ambos lados deben enviar la opción en sus segmentos SYN para habilitar el escalado de ventana en cualquier dirección.
Algunos enrutadores y cortafuegos de paquetes reescriben el factor de escala de la ventana durante una transmisión. Esto hace que los lados de envío y recepción asuman tamaños de ventana TCP diferentes. El resultado es un tráfico inestable que puede ser muy lento. El problema es visible en algunos sitios detrás de un enrutador defectuoso. [60]
Marcas de tiempo TCP
Las marcas de tiempo TCP, definidas en RFC 1323 en 1992, pueden ayudar a TCP a determinar en qué orden se enviaron los paquetes. Las marcas de tiempo TCP normalmente no están alineadas con el reloj del sistema y comienzan con un valor aleatorio. Muchos sistemas operativos incrementarán la marca de tiempo por cada milisegundo transcurrido; sin embargo, la RFC solo establece que los ticks deben ser proporcionales.
Hay dos campos de marca de tiempo:
- un valor de marca de tiempo del remitente de 4 bytes (mi marca de tiempo)
- un valor de marca de tiempo de respuesta de eco de 4 bytes (la marca de tiempo más reciente recibida de usted).
Las marcas de tiempo TCP se utilizan en un algoritmo conocido como Protección contra números de secuencia envueltos o PAWS . PAWS se utiliza cuando la ventana de recepción cruza el límite de envoltura del número de secuencia. En el caso de que un paquete fuera potencialmente retransmitido, responde a la pregunta: "¿Este número de secuencia está en los primeros 4 GB o en los segundos?" Y la marca de tiempo se utiliza para desempatar.
Además, el algoritmo de detección de Eifel utiliza marcas de tiempo TCP para determinar si se producen retransmisiones porque se pierden paquetes o simplemente están fuera de servicio. [61]
Las marcas de tiempo TCP están habilitadas de forma predeterminada en Linux, [62] y deshabilitadas de forma predeterminada en Windows Server 2008, 2012 y 2016. [63]
Las estadísticas recientes muestran que el nivel de adopción de marcas de tiempo TCP se ha estancado, en aproximadamente un 40%, debido a que Windows Server dejó de brindar soporte desde Windows Server 2008. [64]
Datos fuera de banda
Es posible interrumpir o abortar el flujo en cola en lugar de esperar a que finalice. Esto se hace especificando los datos como urgentes . Esto marca la transmisión como datos fuera de banda (OOB) y le dice al programa receptor que los procese inmediatamente. Cuando termina, TCP informa a la aplicación y reanuda la cola de flujo. Un ejemplo es cuando TCP se utiliza para una sesión de inicio de sesión remota donde el usuario puede enviar una secuencia de teclado que interrumpe o aborta el programa que se ejecuta de forma remota sin esperar a que el programa finalice su transferencia actual. [13]
El puntero urgente solo altera el procesamiento en el host remoto y no acelera ningún procesamiento en la red en sí. La capacidad se implementa de manera diferente o deficiente en diferentes sistemas o puede no ser compatible. Cuando está disponible, es prudente asumir que solo se manejarán de manera confiable bytes individuales de datos OOB. [65] [66] Dado que la función no se usa con frecuencia, no se ha probado bien en algunas plataformas y se ha asociado con vulnerabilidades , WinNuke por ejemplo.
Forzar la entrega de datos
Normalmente, TCP espera 200 ms para enviar un paquete completo de datos ( el algoritmo de Nagle intenta agrupar mensajes pequeños en un solo paquete). Esta espera crea pequeños retrasos, pero potencialmente graves, si se repite constantemente durante una transferencia de archivos. Por ejemplo, un bloque de envío típico sería de 4 KB, un MSS típico es de 1460, por lo que salen 2 paquetes en una red Ethernet de 10 Mbit/s que tardan aproximadamente 1,2 ms cada uno, seguidos de un tercero que lleva los 1176 restantes después de una pausa de 197 ms porque TCP está esperando que se llene el búfer. En el caso de Telnet, el servidor repite cada pulsación de tecla del usuario antes de que el usuario pueda verla en la pantalla. Este retraso se volvería muy molesto.
Al configurar la opción de socketTCP_NODELAY , se anula el retraso de envío predeterminado de 200 ms. Los programas de aplicación utilizan esta opción de socket para forzar el envío de la salida después de escribir un carácter o una línea de caracteres.
El RFC [ ¿cuál? ] define el PSHbit push como "un mensaje a la pila TCP receptora para enviar estos datos inmediatamente a la aplicación receptora". [13] No hay forma de indicarlo o controlarlo en el espacio de usuario utilizando sockets Berkeley ; está controlado únicamente por la pila de protocolos . [67]
Vulnerabilidades
El protocolo TCP puede ser atacado de diversas maneras. Los resultados de una evaluación exhaustiva de la seguridad del protocolo TCP, junto con las posibles mitigaciones de los problemas identificados, se publicaron en 2009 [68] y se analizaron en el marco del IETF hasta 2012. [69] Entre las vulnerabilidades más destacadas se incluyen la denegación de servicio, el secuestro de conexión, el veto de TCP y el ataque de restablecimiento de TCP .
Denegación de servicio
Al utilizar una dirección IP falsificada y enviar repetidamente paquetes SYN ensamblados a propósito , seguidos de muchos paquetes ACK, los atacantes pueden hacer que el servidor consuma grandes cantidades de recursos para realizar un seguimiento de las conexiones falsas. Esto se conoce como un ataque de inundación SYN . Las soluciones propuestas para este problema incluyen cookies SYN y rompecabezas criptográficos, aunque las cookies SYN vienen con su propio conjunto de vulnerabilidades. [70] Sockstress es un ataque similar, que podría mitigarse con la gestión de recursos del sistema. [71] Un ataque DoS avanzado que implica la explotación del temporizador de persistencia TCP fue analizado en Phrack No. 66. [72] Las inundaciones PUSH y ACK son otras variantes. [73]
Secuestro de conexión
Un atacante que pueda espiar una sesión TCP y redirigir paquetes puede secuestrar una conexión TCP. Para ello, el atacante aprende el número de secuencia de la comunicación en curso y falsifica un segmento falso que se parece al siguiente segmento de la secuencia. Un secuestro simple puede provocar que un paquete sea aceptado erróneamente en un extremo. Cuando el host receptor reconoce el segmento falso, se pierde la sincronización. [74] El secuestro puede combinarse con la suplantación de ARP u otros ataques de enrutamiento que permiten a un atacante tomar el control permanente de la conexión TCP.
Suplantar una dirección IP diferente no era difícil antes de RFC 1948, cuando el número de secuencia inicial era fácilmente adivinable. Las implementaciones anteriores permitían a un atacante enviar a ciegas una secuencia de paquetes que el receptor creería que provenían de una dirección IP diferente, sin necesidad de interceptar la comunicación mediante ARP o ataques de enrutamiento: basta con asegurarse de que el host legítimo de la dirección IP suplantada esté inactivo, o llevarlo a esa condición mediante ataques de denegación de servicio . Es por eso que ahora el número de secuencia inicial se elige al azar.
Veto del TCP
Un atacante que puede escuchar a escondidas y predecir el tamaño del próximo paquete que se enviará puede hacer que el receptor acepte una carga maliciosa sin interrumpir la conexión existente. El atacante inyecta un paquete malicioso con el número de secuencia y el tamaño de carga del siguiente paquete esperado. Cuando finalmente se recibe el paquete legítimo, se descubre que tiene el mismo número de secuencia y longitud que un paquete ya recibido y se descarta silenciosamente como un paquete duplicado normal: el paquete legítimo es vetado por el paquete malicioso. A diferencia del secuestro de conexión, la conexión nunca se desincroniza y la comunicación continúa normalmente después de que se acepta la carga maliciosa. El veto TCP le da al atacante menos control sobre la comunicación, pero hace que el ataque sea particularmente resistente a la detección. La única evidencia para el receptor de que algo anda mal es un solo paquete duplicado, una ocurrencia normal en una red IP. El remitente del paquete vetado nunca ve ninguna evidencia de un ataque. [75]
Puertos TCP
Una conexión TCP se identifica mediante una tupla de cuatro bits de la dirección de origen, el puerto de origen , la dirección de destino y el puerto de destino. [d] [76] [77] Los números de puerto se utilizan para identificar diferentes servicios y para permitir múltiples conexiones entre hosts. [14] TCP utiliza números de puerto de 16 bits , lo que proporciona 65.536 valores posibles para cada uno de los puertos de origen y destino. [17] La dependencia de la identidad de la conexión en las direcciones significa que las conexiones TCP están vinculadas a una única ruta de red; TCP no puede utilizar otras rutas que los hosts multihomed tengan disponibles, y las conexiones se interrumpen si cambia la dirección de un punto final. [78]
Los números de puerto se clasifican en tres categorías básicas: conocidos, registrados y dinámicos o privados. Los puertos conocidos son asignados por la Autoridad de Números Asignados de Internet (IANA) y generalmente son utilizados por procesos a nivel de sistema. Las aplicaciones conocidas que se ejecutan como servidores y escuchan pasivamente las conexiones generalmente utilizan estos puertos. Algunos ejemplos incluyen: FTP (20 y 21), SSH (22), TELNET (23), SMTP (25), HTTP sobre SSL/TLS (443) y HTTP (80). [e] Los puertos registrados generalmente son utilizados por aplicaciones de usuario final como puertos de origen efímeros cuando se comunican con servidores, pero también pueden identificar servicios con nombre que han sido registrados por un tercero. Los puertos dinámicos o privados también pueden ser utilizados por aplicaciones de usuario final, sin embargo, estos puertos generalmente no contienen ningún significado fuera de una conexión TCP particular.
La traducción de direcciones de red (NAT) normalmente utiliza números de puerto dinámicos en el lado público para eliminar la ambigüedad del flujo de tráfico que pasa entre una red pública y una subred privada , lo que permite que muchas direcciones IP (y sus puertos) en la subred sean atendidas por una única dirección pública.
Desarrollo
TCP es un protocolo complejo. Sin embargo, aunque se han realizado y propuesto mejoras significativas a lo largo de los años, su funcionamiento más básico no ha cambiado significativamente desde su primera especificación RFC 675 en 1974 y la especificación v4 RFC 793, publicada en septiembre de 1981. La RFC 1122, publicada en octubre de 1989, aclaró una serie de requisitos de implementación del protocolo TCP. Una lista de las 8 especificaciones requeridas y más de 20 mejoras fuertemente recomendadas está disponible en la RFC 7414. Entre esta lista se encuentra la RFC 2581, TCP Congestion Control, una de las RFC más importantes relacionadas con TCP en los últimos años, que describe algoritmos actualizados que evitan la congestión indebida. En 2001, se escribió la RFC 3168 para describir la Notificación Explícita de Congestión (ECN), un mecanismo de señalización para evitar la congestión.
El algoritmo original de prevención de congestión TCP se conocía como TCP Tahoe , pero desde entonces se han propuesto muchos algoritmos alternativos (incluidos TCP Reno , TCP Vegas , FAST TCP , TCP New Reno y TCP Hybla ).
Multipath TCP (MPTCP) [79] [80] es un esfuerzo en curso dentro del IETF que apunta a permitir que una conexión TCP utilice múltiples rutas para maximizar el uso de recursos y aumentar la redundancia. La redundancia ofrecida por Multipath TCP en el contexto de redes inalámbricas permite el uso simultáneo de diferentes redes, lo que brinda mayor rendimiento y mejores capacidades de transferencia. Multipath TCP también brinda beneficios de rendimiento en entornos de centros de datos. [81] La implementación de referencia [82] de Multipath TCP se desarrolló en el núcleo Linux. [83] Multipath TCP se utiliza para admitir la aplicación de reconocimiento de voz Siri en iPhones, iPads y Macs. [84]
tcpcrypt es una extensión propuesta en julio de 2010 para proporcionar cifrado a nivel de transporte directamente en el propio TCP. Está diseñada para funcionar de forma transparente y no requerir ninguna configuración. A diferencia de TLS (SSL), tcpcrypt en sí no proporciona autenticación, pero proporciona primitivas simples a la aplicación para que lo haga. La RFC de tcpcrypt fue publicada por el IETF en mayo de 2019. [85]
TCP Fast Open es una extensión para acelerar la apertura de conexiones TCP sucesivas entre dos puntos finales. Funciona omitiendo el protocolo de enlace de tres vías mediante una cookie criptográfica . Es similar a una propuesta anterior llamada T/TCP , que no fue ampliamente adoptada debido a problemas de seguridad. [86] TCP Fast Open se publicó como RFC 7413 en 2014. [87]
Propuesta en mayo de 2013, la reducción de velocidad proporcional (PRR) es una extensión TCP desarrollada por los ingenieros de Google. PRR garantiza que el tamaño de la ventana TCP después de la recuperación sea lo más cercano posible al umbral de inicio lento . [88] El algoritmo está diseñado para mejorar la velocidad de recuperación y es el algoritmo de control de congestión predeterminado en los núcleos Linux 3.2+. [89]
Propuestas obsoletas
TCP Cookie Transactions (TCPCT) es una extensión propuesta en diciembre de 2009 [90] para proteger a los servidores contra ataques de denegación de servicio. A diferencia de las cookies SYN, TCPCT no entra en conflicto con otras extensiones TCP como el escalado de ventanas . TCPCT se diseñó debido a las necesidades de DNSSEC , donde los servidores tienen que manejar grandes cantidades de conexiones TCP de corta duración. En 2016, TCPCT quedó obsoleto en favor de TCP Fast Open. El estado de la RFC original se cambió a histórico . [91]
Implementaciones de hardware
Una forma de superar los requisitos de potencia de procesamiento del TCP es construir implementaciones de hardware del mismo, conocidas ampliamente como motores de descarga TCP (TOE). El principal problema de los TOE es que son difíciles de integrar en los sistemas informáticos, lo que requiere cambios importantes en el sistema operativo del ordenador o dispositivo.
Imagen de alambre y osificación
Los datos de cable de TCP proporcionan importantes oportunidades de recopilación y modificación de información a los observadores en ruta, ya que los metadatos del protocolo se transmiten en texto claro . [92] [93] Si bien esta transparencia es útil para los operadores de red [94] e investigadores, [95] la información recopilada de los metadatos del protocolo puede reducir la privacidad del usuario final. [96] Esta visibilidad y maleabilidad de los metadatos ha llevado a que TCP sea difícil de extender (un caso de osificación del protocolo ), ya que cualquier nodo intermedio (un " middlebox ") puede tomar decisiones basadas en esos metadatos o incluso modificarlos, [97] [98] rompiendo el principio de extremo a extremo . [99] Una medición encontró que un tercio de las rutas a través de Internet encuentran al menos un intermediario que modifica los metadatos de TCP, y el 6,5% de las rutas encuentran efectos osificantes dañinos de los intermediarios. [100] Evitar los riesgos de extensibilidad de los intermediarios impuso restricciones significativas en el diseño de MPTCP , [101] [102] y las dificultades causadas por los intermediarios han obstaculizado la implementación de TCP Fast Open en navegadores web . [103] Otra fuente de osificación es la dificultad de modificación de las funciones TCP en los puntos finales, típicamente en el núcleo del sistema operativo [104] o en hardware con un motor de descarga TCP . [105]
Actuación
Como TCP proporciona a las aplicaciones la abstracción de un flujo de bytes confiable , puede sufrir bloqueos de cabecera : si los paquetes se reordenan o se pierden y necesitan ser retransmitidos (y por lo tanto se reordenan), los datos de las partes secuencialmente posteriores del flujo pueden recibirse antes que las partes secuencialmente anteriores del flujo; sin embargo, los datos posteriores normalmente no se pueden usar hasta que se hayan recibido los datos anteriores, lo que genera latencia de red . Si se encapsulan y multiplexan múltiples mensajes independientes de nivel superior en una única conexión TCP, entonces el bloqueo de cabecera puede hacer que el procesamiento de un mensaje completamente recibido que se envió más tarde espere la entrega de un mensaje que se envió antes. [106] Los navegadores web intentan mitigar el bloqueo de cabecera abriendo múltiples conexiones paralelas. Esto genera el costo del establecimiento de la conexión repetidamente, así como la multiplicación de los recursos necesarios para rastrear esas conexiones en los puntos finales. [107] Las conexiones paralelas también tienen un control de congestión que opera independientemente una de otra, en lugar de poder agrupar la información y responder más rápidamente a las condiciones de red observadas; [108] Los patrones de envío iniciales agresivos de TCP pueden causar congestión si se abren múltiples conexiones paralelas; y el modelo de equidad por conexión conduce a una monopolización de recursos por parte de las aplicaciones que adoptan este enfoque. [109]
El establecimiento de la conexión es un importante contribuyente a la latencia que experimentan los usuarios web. [110] [111] El protocolo de enlace de tres vías de TCP introduce un RTT de latencia durante el establecimiento de la conexión antes de que se puedan enviar los datos. [111] Para flujos cortos, estos retrasos son muy significativos. [112] La seguridad de la capa de transporte (TLS) requiere un protocolo de enlace propio para el intercambio de claves en el establecimiento de la conexión. Debido al diseño en capas, el protocolo de enlace TCP y el protocolo de enlace TLS proceden en serie; el protocolo de enlace TLS no puede comenzar hasta que el protocolo de enlace TCP haya concluido. [113] Se requieren dos RTT para el establecimiento de la conexión con TLS 1.2 sobre TCP. [114] TLS 1.3 permite la reanudación de la conexión con RTT cero en algunas circunstancias, pero, cuando se aplica en capas sobre TCP, todavía se requiere un RTT para el protocolo de enlace TCP, y esto no puede ayudar a la conexión inicial; Los protocolos de enlace RTT cero también presentan desafíos criptográficos, ya que el intercambio de claves no interactivo , seguro y de repetición segura es un tema de investigación abierto. [115] TCP Fast Open permite la transmisión de datos en los paquetes iniciales (es decir, SYN y SYN-ACK), eliminando un RTT de latencia durante el establecimiento de la conexión. [116] Sin embargo, TCP Fast Open ha sido difícil de implementar debido a la osificación del protocolo; a partir de 2020 , ningún navegador web lo usaba de forma predeterminada. [103][actualizar]
El rendimiento de TCP se ve afectado por la reordenación de paquetes . Los paquetes reordenados pueden provocar el envío de confirmaciones duplicadas que, si cruzan un umbral, activarán una retransmisión espuria y un control de congestión. El comportamiento de transmisión también puede volverse irregular, ya que se confirman rangos grandes de una sola vez cuando se recibe un paquete reordenado al comienzo del rango (de manera similar a cómo el bloqueo de cabecera de línea afecta a las aplicaciones). [117] Blanton y Allman (2002) descubrieron que el rendimiento estaba inversamente relacionado con la cantidad de reordenación, hasta un umbral en el que toda reordenación activa una retransmisión espuria. [118] La mitigación de la reordenación depende de la capacidad de un remitente para determinar que ha enviado una retransmisión espuria y, por lo tanto, de resolver la ambigüedad de la retransmisión. [119] La reducción de las retransmisiones espurias inducidas por la reordenación puede ralentizar la recuperación de una pérdida genuina. [120]
El reconocimiento selectivo puede proporcionar un beneficio significativo al rendimiento; Bruyeron, Hemon y Zhang (1998) midieron ganancias de hasta el 45 %. [121] Un factor importante en la mejora es que el reconocimiento selectivo puede evitar con mayor frecuencia entrar en un inicio lento después de una pérdida y, por lo tanto, puede utilizar mejor el ancho de banda disponible. [122] Sin embargo, TCP solo puede reconocer selectivamente un máximo de tres bloques de números de secuencia. Esto puede limitar la tasa de retransmisión y, por lo tanto, la recuperación de pérdidas o causar retransmisiones innecesarias, especialmente en entornos de alta pérdida. [123] [124]
TCP fue diseñado originalmente para redes cableadas. La pérdida de paquetes se considera el resultado de la congestión de la red y el tamaño de la ventana de congestión se reduce drásticamente como medida de precaución. Sin embargo, se sabe que los enlaces inalámbricos experimentan pérdidas esporádicas y generalmente temporales debido al desvanecimiento, el sombreado, la transferencia, la interferencia y otros efectos de radio, que no son estrictamente congestión. Después de la reducción (errónea) del tamaño de la ventana de congestión, debido a la pérdida de paquetes inalámbricos, puede haber una fase de evitación de la congestión con una disminución conservadora del tamaño de la ventana. Esto hace que el enlace de radio se subutilice. Se han realizado investigaciones exhaustivas para combatir estos efectos nocivos. Las soluciones sugeridas se pueden clasificar como soluciones de extremo a extremo, que requieren modificaciones en el cliente o servidor, [125] soluciones de capa de enlace, como el Protocolo de enlace de radio ( RLP ) en redes celulares, o soluciones basadas en proxy que requieren algunos cambios en la red sin modificar los nodos finales. [125] [126]
Se han propuesto varios algoritmos alternativos de control de congestión, como Vegas , Westwood , Veno y Santa Cruz, para ayudar a resolver el problema inalámbrico. [ cita requerida ]
Aceleración
La idea de un acelerador TCP es terminar las conexiones TCP dentro del procesador de red y luego retransmitir los datos a una segunda conexión hacia el sistema final. Los paquetes de datos que se originan en el remitente se almacenan en el nodo acelerador, que es responsable de realizar retransmisiones locales en caso de pérdida de paquetes. De este modo, en caso de pérdidas, el bucle de retroalimentación entre el remitente y el receptor se acorta al que existe entre el nodo acelerador y el receptor, lo que garantiza una entrega más rápida de los datos al receptor. [127]
Dado que TCP es un protocolo de velocidad adaptable, la velocidad a la que el emisor TCP inyecta paquetes en la red es directamente proporcional a la condición de carga predominante en la red, así como a la capacidad de procesamiento del receptor. El emisor juzga las condiciones predominantes en la red en función de los reconocimientos que recibe. El nodo de aceleración divide el bucle de retroalimentación entre el emisor y el receptor y, por lo tanto, garantiza un tiempo de ida y vuelta (RTT) más corto por paquete. Un RTT más corto es beneficioso, ya que garantiza un tiempo de respuesta más rápido a cualquier cambio en la red y una adaptación más rápida por parte del emisor para combatir estos cambios.
Las desventajas de este método incluyen el hecho de que la sesión TCP debe dirigirse a través del acelerador; esto significa que si el enrutamiento cambia, de modo que el acelerador ya no está en la ruta, la conexión se interrumpirá. También destruye la propiedad de extremo a extremo del mecanismo de reconocimiento TCP; cuando el remitente recibe el reconocimiento, el paquete ha sido almacenado por el acelerador, no entregado al receptor.
Depuración
Un sniffer de paquetes , que intercepta el tráfico TCP en un enlace de red, puede ser útil para depurar redes, pilas de red y aplicaciones que utilizan TCP, ya que muestra al usuario qué paquetes pasan por un enlace. Algunas pilas de red admiten la opción de socket SO_DEBUG, que se puede habilitar en el socket mediante setsockopt. Esa opción vuelca todos los paquetes, estados TCP y eventos en ese socket, lo que resulta útil para la depuración. Netstat es otra utilidad que se puede utilizar para la depuración.
Alternativas
Para muchas aplicaciones, el protocolo TCP no es adecuado. Un problema (al menos con las implementaciones normales) es que la aplicación no puede acceder a los paquetes que vienen después de un paquete perdido hasta que se recibe la copia retransmitida del paquete perdido. Esto causa problemas para aplicaciones en tiempo real, como la transmisión de medios, los juegos multijugador en tiempo real y la voz sobre IP (VoIP), donde generalmente es más útil obtener la mayoría de los datos de manera oportuna que obtener todos los datos en orden.
Por razones históricas y de rendimiento, la mayoría de las redes de área de almacenamiento (SAN) utilizan el Protocolo de canal de fibra (FCP) sobre conexiones de canal de fibra .
Además, para sistemas integrados , arranque de red y servidores que atienden solicitudes simples de una gran cantidad de clientes (por ejemplo, servidores DNS ), la complejidad de TCP puede ser un problema. Finalmente, algunos trucos, como transmitir datos entre dos hosts que están detrás de NAT (usando STUN o sistemas similares), son mucho más simples sin un protocolo relativamente complejo como TCP en el camino.
Generalmente, cuando el protocolo TCP no es adecuado, se utiliza el protocolo de datagramas de usuario (UDP). Este protocolo proporciona a la aplicación la multiplexación y las sumas de comprobación que ofrece el protocolo TCP, pero no gestiona flujos ni retransmisiones, lo que da al desarrollador de la aplicación la capacidad de codificarlos de una manera adecuada para la situación o de reemplazarlos con otros métodos como la corrección de errores de avance o la interpolación .
El protocolo de transmisión de control de flujo (SCTP) es otro protocolo que proporciona servicios confiables orientados al flujo similares al TCP. Es más nuevo y considerablemente más complejo que el TCP, y aún no se ha implementado de manera generalizada. Sin embargo, está especialmente diseñado para usarse en situaciones donde la confiabilidad y las consideraciones de tiempo casi real son importantes.
El Protocolo de Transporte Venturi (VTP) es un protocolo propietario patentado que está diseñado para reemplazar al TCP de forma transparente para superar las ineficiencias percibidas relacionadas con el transporte de datos inalámbricos.
TCP también tiene problemas en entornos con un gran ancho de banda. El algoritmo de prevención de congestión TCP funciona muy bien en entornos ad hoc en los que no se conoce de antemano quién envía los datos. Si el entorno es predecible, un protocolo basado en tiempos como el modo de transferencia asíncrona (ATM) puede evitar la sobrecarga de retransmisiones de TCP.
El Protocolo de Transferencia de Datos (UDT) basado en UDP tiene una mejor eficiencia y equidad que el TCP en redes que tienen un producto de retardo de ancho de banda alto . [128]
El Protocolo de Transacción Multipropósito (MTP/IP) es un software propietario patentado que está diseñado para lograr de manera adaptativa un alto rendimiento de procesamiento y transacciones en una amplia variedad de condiciones de red, particularmente aquellas en las que se percibe que TCP es ineficiente.
Cálculo de suma de comprobación
Suma de comprobación TCP para IPv4
Cuando TCP se ejecuta sobre IPv4 , el método utilizado para calcular la suma de comprobación se define de la siguiente manera: [16]
El campo de suma de comprobación es el complemento a uno de 16 bits de la suma del complemento a uno de todas las palabras de 16 bits del encabezado y el texto. El cálculo de la suma de comprobación debe garantizar la alineación de 16 bits de los datos que se suman. Si un segmento contiene una cantidad impar de octetos de encabezado y texto, la alineación se puede lograr rellenando el último octeto con ceros a su derecha para formar una palabra de 16 bits para fines de suma de comprobación. El relleno no se transmite como parte del segmento. Al calcular la suma de comprobación, el campo de suma de comprobación en sí se reemplaza con ceros.
En otras palabras, después de un relleno adecuado, se suman todas las palabras de 16 bits mediante la aritmética del complemento a uno . Luego, la suma se complementa bit a bit y se inserta como campo de suma de comprobación. En la siguiente tabla se muestra un pseudoencabezado que imita el encabezado del paquete IPv4 utilizado en el cálculo de la suma de comprobación.
| Compensar | Octeto | 0 | 1 | 2 | 3 | ||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Octeto | Poco | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| 0 | 0 | Dirección de origen | |||||||||||||||||||||||||||||||
| 4 | 32 | Dirección de destino | |||||||||||||||||||||||||||||||
| 8 | 64 | Ceros | Protocolo (6) | Longitud TCP | |||||||||||||||||||||||||||||
| 12 | 96 | Puerto de origen | Puerto de destino | ||||||||||||||||||||||||||||||
| 16 | 128 | Número de secuencia | |||||||||||||||||||||||||||||||
| 20 | 160 | Número de acuse de recibo | |||||||||||||||||||||||||||||||
| 24 | 192 | Desplazamiento de datos | Reservado | Banderas | Ventana | ||||||||||||||||||||||||||||
| 28 | 224 | Suma de comprobación | Puntero urgente | ||||||||||||||||||||||||||||||
| 32 | 256 | (Opciones) | |||||||||||||||||||||||||||||||
| 36 | 288 | Datos | |||||||||||||||||||||||||||||||
| 40 | 320 | ||||||||||||||||||||||||||||||||
| ⋮ | ⋮ | ||||||||||||||||||||||||||||||||
La suma de comprobación se calcula sobre los siguientes campos:
- Dirección de origen: 32 bits
- La dirección de origen en el encabezado IPv4
- Dirección de destino: 32 bits
- La dirección de destino en el encabezado IPv4.
- Ceros: 8 bits; Ceros == 0
- Todos ceros.
- Protocolo: 8 bits
- El valor del protocolo para TCP: 6 .
- Longitud TCP: 16 bits
- La longitud del encabezado TCP y los datos (medida en octetos). Por ejemplo, supongamos que tenemos un paquete IPv4 con una longitud total de 200 bytes y un valor IHL de 5, lo que indica una longitud de 5 × 32 bits = 160 bits = 20 bytes. Podemos calcular la longitud TCP como , es decir , que da como resultado bytes.



{kind=link}
{kind=link}
_-_sequence_diagram.svg){kind=link}
{kind=link}
Suma de comprobación TCP para IPv6
Cuando TCP se ejecuta sobre IPv6 , el método utilizado para calcular la suma de comprobación cambia: [129]
Cualquier protocolo de transporte u otro protocolo de capa superior que incluya las direcciones del encabezado IP en su cálculo de suma de comprobación debe modificarse para su uso sobre IPv6, para incluir las direcciones IPv6 de 128 bits en lugar de las direcciones IPv4 de 32 bits.
A continuación se muestra un pseudoencabezado que imita el encabezado IPv6 para el cálculo de la suma de comprobación.
| Compensar | Octeto | 0 | 1 | 2 | 3 | ||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Octeto | Poco | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| 0 | 0 | Dirección de origen | |||||||||||||||||||||||||||||||
| 4 | 32 | ||||||||||||||||||||||||||||||||
| 8 | 64 | ||||||||||||||||||||||||||||||||
| 12 | 96 | ||||||||||||||||||||||||||||||||
| 16 | 128 | Dirección de destino | |||||||||||||||||||||||||||||||
| 20 | 160 | ||||||||||||||||||||||||||||||||
| 24 | 192 | ||||||||||||||||||||||||||||||||
| 28 | 224 | ||||||||||||||||||||||||||||||||
| 32 | 256 | Longitud TCP | |||||||||||||||||||||||||||||||
| 36 | 288 | Ceros | Siguiente encabezado (6) | ||||||||||||||||||||||||||||||
| 40 | 320 | Puerto de origen | Puerto de destino | ||||||||||||||||||||||||||||||
| 44 | 352 | Número de secuencia | |||||||||||||||||||||||||||||||
| 48 | 384 | Número de acuse de recibo | |||||||||||||||||||||||||||||||
| 52 | 416 | Desplazamiento de datos | Reservado | Banderas | Ventana | ||||||||||||||||||||||||||||
| 56 | 448 | Suma de comprobación | Puntero urgente | ||||||||||||||||||||||||||||||
| 60 | 480 | (Opciones) | |||||||||||||||||||||||||||||||
| 64 | 512 | Datos | |||||||||||||||||||||||||||||||
| 68 | 544 | ||||||||||||||||||||||||||||||||
| ⋮ | ⋮ | ||||||||||||||||||||||||||||||||
La suma de comprobación se calcula sobre los siguientes campos:
- Dirección de origen: 128 bits
- La dirección en el encabezado IPv6.
- Dirección de destino: 128 bits
- El destino final; si el paquete IPv6 no contiene un encabezado de enrutamiento, TCP utiliza la dirección de destino en el encabezado IPv6, de lo contrario, en el nodo de origen, utiliza la dirección en el último elemento del encabezado de enrutamiento y, en el nodo receptor, utiliza la dirección de destino en el encabezado IPv6.
- Longitud TCP: 32 bits
- La longitud del encabezado TCP y los datos (medida en octetos).
- Ceros: 24 bits; Ceros == 0
- Todos ceros.
- Siguiente encabezado: 8 bits
- El valor del protocolo para TCP: 6 .
Descarga de suma de comprobación
Muchas implementaciones de la pila de software TCP/IP ofrecen opciones para utilizar la asistencia de hardware para calcular automáticamente la suma de comprobación en el adaptador de red antes de la transmisión a la red o al recibirla de la red para su validación. Esto puede evitar que el sistema operativo utilice valiosos ciclos de CPU para calcular la suma de comprobación. Por lo tanto, se mejora el rendimiento general de la red.
Esta característica puede hacer que los analizadores de paquetes que desconocen o no están seguros acerca del uso de la descarga de suma de comprobación informen sumas de comprobación no válidas en paquetes salientes que aún no han llegado al adaptador de red. [130] Esto solo ocurrirá para los paquetes que se interceptan antes de ser transmitidos por el adaptador de red; todos los paquetes transmitidos por el adaptador de red en el cable tendrán sumas de comprobación válidas. [131] Este problema también puede ocurrir al monitorear paquetes que se transmiten entre máquinas virtuales en el mismo host, donde un controlador de dispositivo virtual puede omitir el cálculo de la suma de comprobación (como una optimización), sabiendo que la suma de comprobación se calculará más tarde por el núcleo del host de la VM o su hardware físico.
Véase también
- Mensajería tolerante a fallos
- Micro-ráfagas (redes)
- Sincronización global TCP
- Fusión TCP
- Ritmo TCP
- TCP sigiloso
- Capa de transporte § Comparación de protocolos de capa de transporte
- WTCP es una modificación de TCP basada en proxy para redes inalámbricas
Notas
- ^ ab Añadido al encabezado por RFC 3168
- ^ Las unidades de tamaño de Windows son, de forma predeterminada, bytes.
- ^ El tamaño de la ventana es relativo al segmento identificado por el número de secuencia en el campo de reconocimiento.
- ^ De manera equivalente, un par de sockets de red para el origen y el destino, cada uno de los cuales se compone de una dirección y un puerto.
- ^ A partir del último estándar, HTTP/3 , se utiliza QUIC como transporte en lugar de TCP.
Referencias
- ^ Labrador, Miguel A.; Pérez, Alfredo J.; Wightman, Pedro M. (2010). Sistemas de información basados en la localización: desarrollo de aplicaciones de seguimiento en tiempo real . CRC Press. ISBN 9781000556803.
- ^ Vinton G. Cerf; Robert E. Kahn (mayo de 1974). "Un protocolo para la intercomunicación de redes de paquetes" (PDF) . IEEE Transactions on Communications . 22 (5): 637–648. doi :10.1109/tcom.1974.1092259. Archivado desde el original (PDF) el 4 de marzo de 2016.
- ^ Bennett, Richard (septiembre de 2009). "Designed for Change: End-to-End Arguments, Internet Innovation, and the Net Neutrality Debate" (PDF) . Fundación para la Tecnología de la Información y la Innovación. pág. 11. Archivado (PDF) del original el 29 de agosto de 2019. Consultado el 11 de septiembre de 2017 .
- ^ RFC 675.
- ^ Russell, Andrew Lawrence (2008). 'Legislaturas industriales': estandarización por consenso en la segunda y tercera revolución industrial (Tesis)."Véase Abbate, Inventing the Internet , 129–30; Vinton G. Cerf (octubre de 1980). "Protocolos para redes de paquetes interconectadas". ACM SIGCOMM Computer Communication Review . 10 (4): 10–11.; y RFC 760. doi : 10.17487/RFC0760 ."
- ^ Postel, Jon (15 de agosto de 1977), Comentarios sobre el Protocolo de Internet y TCP, IEN 2, archivado del original el 16 de mayo de 2019 , consultado el 11 de junio de 2016 ,
Estamos cometiendo un error en nuestro diseño de protocolos de Internet al violar el principio de capas. En concreto, estamos intentando utilizar TCP para hacer dos cosas: servir como protocolo de extremo a extremo a nivel de host y servir como protocolo de empaquetado y enrutamiento de Internet. Estas dos cosas deberían proporcionarse de forma modular y en capas.
- ^ Cerf, Vinton G. (1 de abril de 1980). "Informe final del Proyecto TCP de la Universidad de Stanford".
- ^ Cerf, Vinton G; Cain, Edward (octubre de 1983). "El modelo de arquitectura de Internet del Departamento de Defensa". Redes informáticas . 7 (5): 307–318. doi :10.1016/0376-5075(83)90042-9.
- ^ "Guía TCP/IP: arquitectura TCP/IP y modelo TCP/IP". www.tcpipguide.com . Consultado el 11 de febrero de 2020 .
- ^ "Índice de notas sobre experimentos de Internet". www.rfc-editor.org . Consultado el 21 de enero de 2024 .
- ^ "Robert E Kahn – Ganador del premio AM Turing". amturing.acm.org . Archivado desde el original el 2019-07-13 . Consultado el 2019-07-13 .
- ^ "Vinton Cerf – Ganador del premio AM Turing". amturing.acm.org . Archivado desde el original el 2021-10-11 . Consultado el 2019-07-13 .
- ^ abcdefghi Comer, Douglas E. (2006). Interconexión de redes con TCP/IP: principios, protocolos y arquitectura . Vol. 1 (5.ª ed.). Prentice Hall. ISBN 978-0-13-187671-2.
- ^ abc RFC 9293, 2.2. Conceptos clave de TCP.
- ^ RFC 791, págs. 5–6.
- ^ abcd RFC 9293.
- ^ abc RFC 9293, 3.1. Formato de encabezado.
- ^ RFC 9293, 3.8.5 La comunicación de información urgente.
- ^ RFC 9293, 3.4. Números de secuencia.
- ^ RFC 9293, 3.4.1. Selección del número de secuencia inicial.
- ^ "Cambiar RFC 3540 "Señalización de notificación de congestión explícita robusta (ECN) con nonces" a histórico". datatracker.ietf.org . Consultado el 18 de abril de 2023 .
- ^ RFC 3168, pág. 13-14.
- ^ RFC 3168, pág. 15.
- ^ RFC 3168, pág. 18-19.
- ^ RFC 793.
- ^abc RFC 7323.
- ^ RFC 2018, 2. Opción permitida por Sack.
- ^ RFC 2018, 3. Formato de opción de despido.
- ^ Heffernan, Andy (agosto de 1998). "Protección de sesiones BGP mediante la opción de firma TCP MD5". IETF . Consultado el 30 de diciembre de 2023 .
- ^ "Parámetros del Protocolo de Control de Transmisión (TCP): Números de tipo de opción TCP". IANA. Archivado desde el original el 2017-10-02 . Consultado el 19-10-2017 .
- ^ RFC 9293, 3.3.2. Descripción general de la máquina de estados.
- ^ Kurose, James F. (2017). Redes informáticas: un enfoque de arriba hacia abajo. Keith W. Ross (7.ª ed.). Harlow, Inglaterra. pág. 286. ISBN 978-0-13-359414-0.OCLC 936004518 .
{{cite book}}: CS1 maint: location missing publisher (link) - ^ Tanenbaum, Andrew S. (17 de marzo de 2003). Redes informáticas (cuarta edición). Prentice Hall. ISBN 978-0-13-066102-9.
- ^ RFC 1122, 4.2.2.13. Cierre de una conexión.
- ^ Karn y Partridge 1991, pág. 364.
- ^ RFC 9002, 4.2. Números de paquetes que aumentan monótonamente.
- ^ Mathis; Mathew; Semke; Mahdavi; Ott (1997). "El comportamiento macroscópico del algoritmo de evitación de congestión TCP". ACM SIGCOMM Computer Communication Review . 27 (3): 67–82. CiteSeerX 10.1.1.40.7002 . doi :10.1145/263932.264023. S2CID 1894993.
- ^ RFC 3522, pág. 4.
- ^ Leung, Ka-cheong; Li, Victor Ok; Yang, Daiqin (2007). "Una descripción general de la reordenación de paquetes en el Protocolo de control de transmisión (TCP): problemas, soluciones y desafíos". IEEE Transactions on Parallel and Distributed Systems . 18 (4): 522–535. doi :10.1109/TPDS.2007.1011.
- ^ Johannessen, Mads (2015). Investigación sobre reordenamiento en TCP de Linux (tesis de maestría). Universidad de Oslo.
- ^ Cheng, Yuchung (2015). RACK: una detección rápida de pérdidas basada en el tiempo para TCP draft-cheng-tcpm-rack-00 (PDF) . IETF94. Yokohama: IETF.
- ^ RFC 8985.
- ^ Cheng, Yuchung; Cardwell, Neal; Dukkipati, Nandita; Jha, Priyaranjan (2017). RACK: un sistema de recuperación de pérdidas rápido basado en el tiempo draft-ietf-tcpm-rack-02 (PDF) . IETF100. Yokohama: IETF.
- ^ RFC 6298, pág. 2.
- ^Ab Zhang 1986, pág. 399.
- ^ Karn y Partridge 1991, pág. 365.
- ^ Ludwig y Katz 2000, pág. 31-33.
- ^ Gurtov y Ludwig 2003, pág. 2.
- ^ Gurtov y Floyd 2004, pág. 1.
- ^ desde RFC 6298, pág. 4.
- ^ Karn y Partridge 1991, págs. 370-372.
- ^ Allman y Paxson 1999, pág. 268.
- ^ RFC 7323, pág. 7.
- ^ Stone; Partridge (2000). "Cuando la suma de comprobación CRC y TCP no concuerdan". Actas de la conferencia sobre aplicaciones, tecnologías, arquitecturas y protocolos para la comunicación informática . ACM SIGCOMM Computer Communication Review . pp. 309–319. CiteSeerX 10.1.1.27.7611 . doi :10.1145/347059.347561. ISBN 978-1581132236. S2CID 9547018. Archivado desde el original el 5 de mayo de 2008. Consultado el 28 de abril de 2008 .
- ^ RFC 5681.
- ^ RFC 6298.
- ^ RFC 1122.
- ^ RFC 2018, pág. 10.
- ^ RFC 9002, 4.4. No se permiten renegar.
- ^ "Escalado de ventanas TCP y enrutadores dañados". LWN.net . Archivado desde el original el 2020-03-31 . Consultado el 2016-07-21 .
- ^ RFC 3522.
- ^ "IP sysctl". Documentación del kernel de Linux . Archivado desde el original el 5 de marzo de 2016. Consultado el 15 de diciembre de 2018 .
- ^ Wang, Eve. "La marca de tiempo TCP está deshabilitada". Technet – Windows Server 2012 Essentials . Microsoft. Archivado desde el original el 2018-12-15 . Consultado el 2018-12-15 .
- ^ David Murray; Terry Koziniec; Sebastian Zander; Michael Dixon; Polychronis Koutsakis (2017). "An Analysis of Changing Enterprise Network Traffic Characteristics" (PDF) . 23.ª Conferencia de Asia y el Pacífico sobre Comunicaciones (APCC 2017). Archivado (PDF) del original el 3 de octubre de 2017. Consultado el 3 de octubre de 2017 .
- ^ Gont, Fernando (noviembre de 2008). "Sobre la implementación de datos urgentes TCP". 73.ª reunión de la IETF. Archivado desde el original el 16 de mayo de 2019. Consultado el 4 de enero de 2009 .
- ^ Peterson, Larry (2003). Redes informáticas . Morgan Kaufmann. pág. 401. ISBN 978-1-55860-832-0.
- ^ Richard W. Stevens (noviembre de 2011). TCP/IP Illustrated. Vol. 1, Los protocolos . Addison-Wesley. pp. Capítulo 20. ISBN 978-0-201-63346-7.
- ^ "Evaluación de seguridad del Protocolo de control de transmisión (TCP)" (PDF) . Archivado desde el original el 6 de marzo de 2009 . Consultado el 23 de diciembre de 2010 .
{{cite web}}: CS1 maint: bot: original URL status unknown (link) - ^ Encuesta sobre métodos de fortalecimiento de la seguridad para implementaciones del Protocolo de control de transmisión (TCP)
- ^ Jakob Lell (13 de agosto de 2013). "Suplantación de conexión TCP ciega rápida con cookies SYN". Archivado desde el original el 22 de febrero de 2014. Consultado el 5 de febrero de 2014 .
- ^ "Algunas ideas sobre las recientes vulnerabilidades de denegación de servicio (DoS) en TCP" (PDF) . Archivado desde el original (PDF) el 2013-06-18 . Consultado el 2010-12-23 .
- ^ "Explotación de TCP y la infinitud del temporizador de persistencia". Archivado desde el original el 22 de enero de 2010. Consultado el 22 de enero de 2010 .
- ^ "Inundación de PUSH y ACK". f5.com . Archivado desde el original el 28 de septiembre de 2017. Consultado el 27 de septiembre de 2017 .
- ^ Laurent Joncheray (1995). "Ataque activo simple contra TCP" (PDF) . Consultado el 4 de junio de 2023 .
- ^ John T. Hagen; Barry E. Mullins (2013). "Veto TCP: Un nuevo ataque de red y su aplicación a los protocolos SCADA". Conferencia sobre tecnologías innovadoras de redes inteligentes (ISGT) de IEEE PES de 2013. Tecnologías innovadoras de redes inteligentes (ISGT), IEEE PES de 2013. págs. 1–6. doi :10.1109/ISGT.2013.6497785. ISBN 978-1-4673-4896-6. Número de identificación del sujeto 25353177.
- ^ RFC 9293, 4. Glosario.
- ^ RFC 8095, pág. 6.
- ^ RFC 6182.
- ^ RFC 6824.
- ^ Raiciu; Barre; Pluntke; Greenhalgh; Wischik; Handley (2011). "Mejora del rendimiento y la robustez del centro de datos con TCP multitrayecto". ACM SIGCOMM Computer Communication Review . 41 (4): 266. CiteSeerX 10.1.1.306.3863 . doi :10.1145/2043164.2018467. Archivado desde el original el 2020-04-04 . Consultado el 2011-06-29 .
- ^ "MultiPath TCP – Implementación del kernel de Linux". Archivado desde el original el 27 de marzo de 2013. Consultado el 24 de marzo de 2013 .
- ^ Raiciu; Paasch; Barre; Ford; Honda; Duchene; Bonaventure; Handley (2012). "¿Qué tan difícil puede ser? Diseño e implementación de un TCP multitrayecto desplegable". Usenix NSDI : 399–412. Archivado desde el original el 2013-06-03 . Consultado el 2013-03-24 .
- ^ Bonaventure; Seo (2016). «Implementaciones TCP de múltiples rutas». IETF Journal . Archivado desde el original el 23 de febrero de 2020. Consultado el 3 de enero de 2017 .
- ^ Protección criptográfica de flujos TCP (tcpcrypt). Mayo de 2019. doi : 10.17487/RFC8548 . RFC 8548.
- ^ Michael Kerrisk (1 de agosto de 2012). "TCP Fast Open: agilizando los servicios web". LWN.net . Archivado desde el original el 3 de agosto de 2014. Consultado el 21 de julio de 2014 .
- ^ RFC 7413.
- ^ RFC 6937.
- ^ Grigorik, Ilya (2013). Redes de navegadores de alto rendimiento (1. ed.). Pekín: O'Reilly. ISBN 978-1449344764.
- ^ RFC 6013.
- ^ RFC 7805.
- ^ RFC 8546, pág. 6.
- ^ RFC 8558, pág. 3.
- ^ RFC 9065, 2. Usos actuales de los encabezados de transporte dentro de la red.
- ^ RFC 9065, 3. Investigación, desarrollo e implementación.
- ^ RFC 8558, pág. 8.
- ^ RFC 9170, 2.3. Interacciones entre múltiples partes y middleboxes.
- ^ RFC 9170, A.5. TCP.
- ^ Papastergiou y col. 2017, pág. 620.
- ^ Edeline y Donnet 2019, pag. 175-176.
- ^ Raiciu y otros, 2012, pág. 1.
- ^ Hesmans y otros, 2013, pág. 1.
- ^ desde Rybczyńska 2020.
- ^ Papastergiou y col. 2017, pág. 621.
- ^ Corbet 2015.
- ^ Briscoe y col. 2016, págs. 29-30.
- ^ Marx 2020, Bloqueo HOL en HTTP/1.1.
- ^ Marx 2020, Bono: Control de la congestión del transporte.
- ^ Grupo de trabajo HTTP de IETF, ¿Por qué solo una conexión TCP?
- ^ Corbet 2018.
- ^ desde RFC 7413, pág. 3.
- ^ Sy et al. 2020, pág. 271.
- ^ Chen et al. 2021, págs. 8-9.
- ^ Ghedini 2018.
- ^ Chen et al. 2021, págs. 3-4.
- ^ RFC 7413, pág. 1.
- ^ Blanton y Allman 2002, págs. 1-2.
- ^ Blanton y Allman 2002, págs. 4-5.
- ^ Blanton y Allman 2002, págs. 3-4.
- ^ Blanton y Allman 2002, págs. 6-8.
- ^ Bruyeron, Hemon y Zhang 1998, pág. 67.
- ^ Bruyeron, Hemon y Zhang 1998, pág. 72.
- ^ Bhat, Rizk y Zink 2017, pág. 14.
- ^ RFC 9002, 4.5. Más rangos ACK.
- ^ ab "Rendimiento TCP sobre CDMA2000 RLP". Archivado desde el original el 3 de mayo de 2011. Consultado el 30 de agosto de 2010 .
- ^ Muhammad Adeel y Ahmad Ali Iqbal (2007). "Optimización de la ventana de congestión TCP para redes de datos por paquetes CDMA2000". Cuarta Conferencia Internacional sobre Tecnología de la Información (ITNG'07) . pp. 31–35. doi :10.1109/ITNG.2007.190. ISBN 978-0-7695-2776-5. Número de identificación del sujeto 8717768.
- ^ "Aceleración TCP". Archivado desde el original el 22 de abril de 2024. Consultado el 18 de abril de 2024 .
- ^ Yunhong Gu, Xinwei Hong y Robert L. Grossman. "Análisis del algoritmo AIMD con incrementos decrecientes" Archivado el 5 de marzo de 2016 en Wayback Machine . 2004.
- ^ RFC 8200.
- ^ "Wireshark: descarga". Archivado desde el original el 31 de enero de 2017. Consultado el 24 de febrero de 2017. Wireshark
captura los paquetes antes de enviarlos al adaptador de red. No verá la suma de comprobación correcta porque aún no se ha calculado. Peor aún, la mayoría de los sistemas operativos no se molestan en inicializar estos datos, por lo que probablemente esté viendo pequeños fragmentos de memoria que no debería ver. Las nuevas instalaciones de Wireshark 1.2 y posteriores deshabilitan la validación de suma de comprobación de IP, TCP y UDP de forma predeterminada. Puede deshabilitar la validación de suma de comprobación en cada uno de esos disectores de forma manual si es necesario.
- ^ "Wireshark: sumas de comprobación". Archivado desde el original el 22 de octubre de 2016. Consultado el 24 de febrero de 2017. La
descarga de sumas de comprobación suele causar confusión, ya que los paquetes de red que se van a transmitir se entregan a Wireshark antes de que se calculen realmente las sumas de comprobación. Wireshark obtiene estas sumas de comprobación "vacías" y las muestra como no válidas, aunque los paquetes contendrán sumas de comprobación válidas cuando salgan del hardware de red más tarde.
Bibliografía
Solicitudes de comentarios
- Cerf, Vint ; Dalal, Yogen ; Sunshine, Carl (diciembre de 1974). Especificación del programa de control de transmisión de Internet, versión de diciembre de 1974. doi : 10.17487/RFC0675 . RFC 675.
- Postel, Jon (septiembre de 1981). Protocolo de Internet. doi : 10.17487/RFC0791 . RFC 791.
- Postel, Jon (septiembre de 1981). Protocolo de control de transmisión. doi : 10.17487/RFC0793 . RFC 793.
- Braden, Robert , ed. (octubre de 1989). Requisitos para hosts de Internet: capas de comunicación. doi : 10.17487/RFC1122 . RFC 1122.
- Jacobson, Van ; Braden, Bob ; Borman, Dave (mayo de 1992). Extensiones TCP para alto rendimiento. doi : 10.17487/RFC1323 . RFC 1323.
- Bellovin, Steven M. (mayo de 1996). Defensa contra ataques de números de secuencia. doi : 10.17487/RFC1948 . RFC 1948.
- Mathis, Matt; Mahdavi, Jamshid; Floyd, Sally; Romanow, Allyn (octubre de 1996). Opciones de reconocimiento selectivo de TCP. doi : 10.17487/RFC2018 . RFC 2018.
- Allman, Mark; Paxson, Vern ; Stevens, W. Richard (abril de 1999). Control de congestión TCP. doi : 10.17487/RFC2581 . RFC 2581.
- Floyd, Sally ; Mahdavi, Jamshid; Mathis, Matt; Podolsky, Matthew (julio de 2000). Una extensión de la opción de acuse de recibo selectivo (SACK) para TCP. doi : 10.17487/RFC2883 . RFC 2883.
- Ramakrishnan, KK; Floyd, Sally ; Black, David (septiembre de 2001). La incorporación de la notificación explícita de congestión (ECN) a la propiedad intelectual. doi : 10.17487/RFC3168 . RFC 3168.
- Ludwig, Reiner; Meyer, Michael (abril de 2003). El algoritmo de detección de Eifel para TCP. doi : 10.17487/RFC3522 . RFC 3522.
- Spring, Neil; Weatherall, David; Ely, David (junio de 2003). Señalización de notificación de congestión explícita robusta (ECN) con nonces. doi : 10.17487/RFC3540 . RFC 3540.
- Allman, Mark; Paxson, Vern ; Blanton, Ethan (septiembre de 2009). Control de congestión TCP. doi : 10.17487/RFC5681 . RFC 5681.
- Simpson, William Allen (enero de 2011). Transacciones de cookies TCP (TCPCT). doi : 10.17487/RFC6013 . RFC 6013.
- Ford, Alan; Raiciu, Costin; Handley, Mark ; Barre, Sebastien; Iyengar, Janardhan (marzo de 2011). Pautas arquitectónicas para el desarrollo de TCP multitrayecto. doi : 10.17487/RFC6182 . RFC 6182.
- Paxson, Vern ; Allman, Mark; Chu, HK Jerry; Sargent, Matt (junio de 2011). Cálculo del temporizador de retransmisión de TCP. doi : 10.17487/RFC6298 . RFC 6298.
- Ford, Alan; Raiciu, Costin; Handley, Mark ; Bonaventure, Olivier (enero de 2013). Extensiones TCP para operaciones de múltiples rutas con múltiples direcciones. doi : 10.17487/RFC6824 . RFC 6824.
- Mathis, Matt; Dukkipati, Nandita; Cheng, Yuchung (mayo de 2013). Reducción de tasa proporcional para TCP. doi : 10.17487/RFC6937 . RFC 6937.
- Borman, David; Braden, Bob ; Jacobson, Van (septiembre de 2014). Scheffenegger, Richard (ed.). Extensiones TCP para alto rendimiento. doi : 10.17487/RFC7323 . RFC 7323.
- Duke, Martin; Braden, Robert ; Eddy, Wesley M.; Blanton, Ethan; Zimmermann, Alexander (febrero de 2015). Una hoja de ruta para los documentos de especificación del Protocolo de control de transmisión (TCP). doi : 10.17487/RFC7414 . RFC 7414.
- Cheng, Yuchung; Chu, Jerry; Radhakrishnan, Sivasankar; Jain, Arvind (diciembre de 2014). Apertura rápida de TCP. doi : 10.17487/RFC7413 . RFC 7413.
- Zimmermann, Alexander; Eddy, Wesley M.; Eggert, Lars (abril de 2016). Trasladar extensiones TCP obsoletas y documentos relacionados con TCP a un estado histórico o informativo. doi : 10.17487/RFC7805 . RFC 7805.
- Fairhurst, Gorry; Trammell, Brian; Kuehlewind, Mirja, eds. (marzo de 2017). Servicios proporcionados por los protocolos de transporte y mecanismos de control de la congestión de la IETF. doi : 10.17487/RFC8095 . RFC 8095.
- Cheng, Yuchung; Cardwell, Neal; Dukkipati, Nandita; Jha, Priyaranjan, eds. (febrero de 2021). El algoritmo de detección de pérdidas RACK-TLP para TCP. doi : 10.17487/RFC8985 . RFC 8985.
- Deering, Stephen E. ; Hinden, Robert M. (julio de 2017). Especificación del Protocolo de Internet, versión 6 (IPv6). doi : 10.17487/RFC8200 . RFC 8200.
- Trammell, Brian; Kuehlewind, Mirja (abril de 2019). La imagen de un protocolo de red. doi : 10.17487/RFC8546 . RFC 8546.
- Hardie, Ted, ed. (abril de 2019). Transport Protocol Path Signals (Señales de ruta del protocolo de transporte). doi : 10.17487/RFC8558 . RFC 8558.
- Iyengar, Jana; Swett, Ian, eds. (mayo de 2021). Detección de pérdidas y control de congestión QUIC. doi : 10.17487/RFC9002 . RFC 9002.
- Fairhurst, Gorry; Perkins, Colin (julio de 2021). Consideraciones sobre la confidencialidad de los encabezados de transporte, las operaciones de red y la evolución de los protocolos de transporte de Internet. doi : 10.17487/RFC9065 . RFC 9065.
- Thomson, Martin; Pauly, Tommy (diciembre de 2021). Viabilidad a largo plazo de los mecanismos de extensión de protocolos. doi : 10.17487/RFC9170 . RFC 9170.
- Eddy, Wesley M., ed. (agosto de 2022). Protocolo de control de transmisión (TCP). doi : 10.17487/RFC9293 . RFC 9293.
Otros documentos
- Allman, Mark; Paxson, Vern (octubre de 1999). "Sobre la estimación de propiedades de rutas de red de extremo a extremo". ACM SIGCOMM Computer Communication Review . 29 (4): 263–274. doi : 10.1145/316194.316230 . hdl : 2060/20000004338 .
- Bhat, Divyashri; Rizk, Amr; Zink, Michael (junio de 2017). "No tan QUIC: un estudio de rendimiento de DASH sobre QUIC". NOSSDAV'17: Actas del 27.° taller sobre compatibilidad de sistemas operativos y redes para audio y video digital . págs. 13–18. doi :10.1145/3083165.3083175. S2CID 32671949.
- Blanton, Ethan; Allman, Mark (enero de 2002). "Cómo hacer que TCP sea más robusto frente a la reordenación de paquetes" (PDF) . ACM SIGCOMM Computer Communication Review . 32 : 20–30. doi :10.1145/510726.510728. S2CID 15305731.
- Briscoe, Bob; Brunstrom, Anna; Petlund, Andreas; Hayes, David; Ros, David; Tsang, Ing-Jyh; Gjessing, Stein; Fairhurst, Gorry; Griwodz, Carsten; Welzl, Michael (2016). "Reducción de la latencia de Internet: un estudio de las técnicas y sus méritos". IEEE Communications Surveys & Tutorials . 18 (3): 2149–2196. doi :10.1109/COMST.2014.2375213. hdl : 2164/8018 . S2CID 206576469.
- Bruyeron, Renaud; Hemon, Bruno; Zhang, Lixa (abril de 1998). "Experimentaciones con reconocimiento selectivo TCP". ACM SIGCOMM Computer Communication Review . 28 (2): 54–77. doi :10.1145/279345.279350. S2CID 15954837.
- Chen, Shan; Jero, Samuel; Jagielski, Mateo; Boldyreva, Alexandra; Nita-Rotaru, Cristina (2021). "Establecimiento de un canal de comunicación seguro: TLS 1.3 (apertura rápida sobre TCP) frente a QUIC". Revista de criptología . 34 (3). doi : 10.1007/s00145-021-09389-w . S2CID 235174220.
- Corbet, Jonathan (8 de diciembre de 2015). "Descargas de suma de comprobación y osificación del protocolo". LWN.net .
- Corbet, Jonathan (29 de enero de 2018). "QUIC como solución a la osificación del protocolo". LWN.net .
- Edeline, Korian; Donnet, Benoit (2019). Una investigación de abajo hacia arriba de la osificación de la capa de transporte . Conferencia sobre medición y análisis del tráfico de red (TMA) de 2019. doi :10.23919/TMA.2019.8784690.
- Ghedini, Alessandro (26 de julio de 2018). "El camino hacia QUIC". Cloudflare .
- Gurtov, Andrei; Floyd, Sally (febrero de 2004). Resolución de ambigüedades de reconocimiento en protocolos TCP no SACK (PDF) . Teletráfico de próxima generación y redes avanzadas cableadas e inalámbricas (NEW2AN'04).
- Gurtov, Andrei; Ludwig, Reiner (2003). Respuesta a los tiempos de espera espurios en TCP (PDF) . IEEE INFOCOM 2003. Vigésima segunda conferencia anual conjunta de las sociedades de informática y comunicaciones del IEEE. doi :10.1109/INFCOM.2003.1209251.
- Hesmans, Benjamin; Duchene, Fabien; Paasch, Christoph; Detal, Gregory; Bonaventure, Olivier (2013). ¿Son las extensiones TCP a prueba de middlebox? . HotMiddlebox '13. CiteSeerX 10.1.1.679.6364 . doi :10.1145/2535828.2535830.
- Grupo de trabajo HTTP del IETF. "Preguntas frecuentes sobre HTTP/2".
- Karn, Phil ; Partridge, Craig (noviembre de 1991). "Mejora de las estimaciones de tiempos de ida y vuelta en protocolos de transporte fiables". ACM Transactions on Computer Systems . 9 (4): 364–373. doi : 10.1145/118544.118549 .
- Ludwig, Reiner; Katz, Randy Howard (enero de 2000). "El algoritmo Eifel: haciendo que TCP sea robusto frente a retransmisiones espurias". ACM SIGCOMM Computer Communication Review . doi : 10.1145/505688.505692 .
- Marx, Robin (3 de diciembre de 2020). "Bloqueo de cabecera de línea en QUIC y HTTP/3: los detalles".
- Paasch, Christoph; Bonaventure, Olivier (1 de abril de 2014). "Multipath TCP". Comunicaciones de la ACM . 57 (4): 51–57. doi :10.1145/2578901. S2CID 17581886.
- Papastergiou, Giorgos; Fairhurst, Gorry; Ros, David; Brunstrom, Anna; Grinnemo, Karl-Johan; Hurtig, Per; Khademi, Naeem; Tüxen, Michael; Welzl, Michael; Damjanovic, Dragana; Mangiante, Simone (2017). "Desosificación de la capa de transporte de Internet: un estudio y perspectivas futuras". IEEE Communications Surveys & Tutorials . 19 : 619–639. doi :10.1109/COMST.2016.2626780. hdl : 2164/8317 . S2CID 1846371.
- Rybczyńska, Marta (13 de marzo de 2020). "Una mirada rápida a HTTP/3". LWN.net .
- Sy, Erik; Mueller, Tobias; Burkert, Christian; Federrath, Hannes; Fischer, Mathias (2020). "Rendimiento mejorado y privacidad para TLS sobre TCP Fast Open". Actas sobre tecnologías de mejora de la privacidad . 2020 (2): 271–287. arXiv : 1905.03518 . doi : 10.2478/popets-2020-0027 .
- Zhang, Lixia (5 de agosto de 1986). "Por qué los temporizadores TCP no funcionan bien". ACM SIGCOMM Computer Communication Review . 16 (3): 397–405. doi :10.1145/1013812.18216.
Lectura adicional
- Stevens, W. Richard (10 de enero de 1994). TCP/IP Illustrated, volumen 1: los protocolos. Addison-Wesley Pub. Co. ISBN 978-0-201-63346-7.
- Stevens, W. Richard; Wright, Gary R (1994). TCP/IP Illustrated, Volumen 2: La implementación. Addison-Wesley. ISBN 978-0-201-63354-2.
- Stevens, W. Richard (1996). TCP/IP Illustrated, Volumen 3: TCP para transacciones, HTTP, NNTP y los protocolos de dominio UNIX . Addison-Wesley. ISBN 978-0-201-63495-2.**
Enlaces externos
- Entrevista de historia oral con Robert E. Kahn
- Asignaciones de puertos de la IANA
- Parámetros TCP de la IANA
- Descripción general de TCP de John Kristoff (conceptos fundamentales detrás de TCP y cómo se utiliza para transportar datos entre dos puntos finales)
- Ejemplo de suma de comprobación
